Today (Monday 27th of November) is the first day of a new AWS Certification: The AWS Certified Data Engineer —Associate. This is in a beta period now, and as such, any candidates who sit this certification won’t get a result until up to 13 weeks after the end of the beta period.
That beta period is November 27, 2023 – January 12, 2024; so in some time in February or March candidates will find out how they went. During that period, AWS will be assessing where the pass mark should be.
I’ve been pretty forthright in attempting most AWS certifications; I’ve always like to lead from the front to help demonstrate even an aging open source tech geek sys admin like myself can do this. And to that end, I reserved a quiet meeting room at 0200 UTC today (10am AWST) to do the online-proctored exam for this certification.
As always there are terms & conditions on disclosure, so I can only speak at high level. It was 85 questions, the vast majority where to select one correct answer (key) from four possibilities; only a handful had the “select any TWO” option.
The questions I received focuses on Glue, Redshift, Athena, Kinesis, and in passing, S3 and IAM. I say “I received“, as there is a pool of questions, and I would have only had 85 from a larger pool; your assessment would likely be different questions.
It took me around ne hour fifteen minutes, and I went back to review just 2 questrions.
Overall I found this was perhaps a little more detailed and domain based than the existing Associate level certifications. There were use cases for Redshift that I’ve not used that stumped me. There were Glue and Databrew use cases I haven’t used in production.
All in all I think its well placed to ensure that candidates have a solid understanding of data engineering, fault tolerance, cost, and durability of data. For those that are doing cloud native data analytics pipelines, then I would say this should be on your list of certs to get.
We’ll find out in Q1 if I am up to speed on this. 😉
Code build sits amongst a slew of Code* services, which developers can pick and chose from to get their jobs done. I’m going to concentrate on just three of them:
Code Commit: a managed Git repository
Code Build: a service to launch compute* to execute software compile/built/test services
Code Pipeline: a CI/CD pipeline that helps orchestrate the pattern of build and release actions, across different environments
My common use case is for publishing (mostly) static web sites. Being a web developer since the early 1990s, I’m pretty comfortable with importing some web frameworks, writing some HTML and additional CSS, grabbing some images, and then publishing the content.
That content is typically deployed to an S3 Bucket, with CloudFront sitting in front of it, and Route53 doing its duty for DNS resolution… times two or three environments (dev, test, prod).
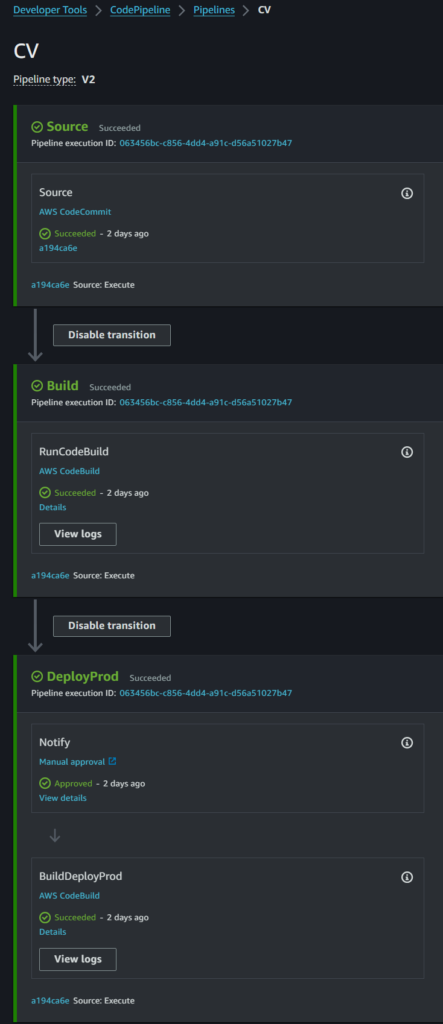
CodePipeline can be automatically kicked off when a developer pushes a commit to the repo. For several years I have used the native Code Pipeline service to deploy this artifact, but there’s always been a few niggles.
As a developer, I also like having some pre-commit hooks. I like to ensure my HTML is reasonable, that I haven’t put any credentials in my code, etc. For this I use the pre-commit hooks.
Here’s my “.pre-commit-config.yaml” file, that sits in the base of my content repo:
There’s a few more “dot” files such as “.htmllintrc” that also get created and persisted to the repo, but here’s the catch: I want them there for the developers, but I want them purged when being published.
Using the original CodePipeline with the native S3 Deployer was simple, but didn’t give the opportunity to tidy up. That would require Code Build.
However, until this new announcement, using code build meant defining a whole EC2 instance (and VPC for it to live in) and waiting the 20 – 60 seconds for it to start before running your code. The time, and cost, wasn’t worth it in my opinion.
Until now, with Lambda.
I defined (and committed to the repo) a buildspec.yml file, and the commands in the build section show what I am tidying up:
Yes, the buildspec.yml file is one of the files I don’t want to publish.
Time to change the Pipeline order, and include a Build stage that created a new output artifact based upon that. The above buildspec.yml file then has an additional section at the end:
artifacts:
files:
- '**/*'
This the code Build job config, we define a new name for the output artifacts, int his case I called it “TidySource”.However there was an issue with the output artifact from this.
When CodeCommit triggers a build, it makes a single artifact available to the pipeline: the ZIP contents from the repo, in an S3 Bucket for the pipeline. The format of this object’s key (name) is:
The original S3 Deployer in CodePipeline understood that, and gave you the option to decompress the object (zip file) when it put it in the configured destination bucket.
CodeBuild supports multiple artifacts, and its format for the output object defined from the buildspec is:
As such, S3 Deployer would then look for the object that should match the first syntax, and fails.
Hmmm.
OK, I had one more niggle about the s3 deployer: it doesn’t tidy up. If you delete something from your repo, the S3 deploy does not delete from the deployment location – it just unpacks over the top, leaving previously deployed files in place.
So my last change was to ditch both the output artifact from code build, and the original S3 deployer itself, and use the trusty aws s3 sync command, and a few variables in the code pipeline:
You can view the resulting web site at https://cv.jamesbromberger.com/. If you read the footnotes here it will tell you about some of the pipeline. Now I have a new place to play in – automating some of the framework management via NPM during the build phase, and running a few sed commands to update resulting paths in HTML content.
But my big wins are:
You can’t hit https://cv.jamesbromberger.com/.htmllintrc any more (not that there was anything secure in there, but I like to be… tidy)
Older versions of frameworks (bootstrap) are no longer lying around in /assets/bootstrap-${version}/.
Its not costing me more timer or money when doing this tidy up, thanks to Lambda.
Its great to see another minor improvement like this. External resources that your service depends upon – APIs, etc – should now see connections over IPv6.
If you host an API, then you should be making it dual-stack in order to facilitate your clients making IPv6 connections, and avoiding things like small charged and complexity for using up scarce IPv4 addresses.
However, this is also useful if you’re trying to access private resources with in an AWS VPC.
VPC Subnets can be IPv4 only, dual-stack, or IPv6 only. Taking the IPv6 only approach permits you to provision vast numbers of EC2 instances, RDS, etc. Now your Lambda code can access those services directly without needing a proxy bottleneck) to do so.
At some stage, we’ll be looking at VPCs that are IPv6 only, with only API Gateways and/or Elastic Load Balancers being dual stack for external inbound requests.
Presumably Lambda will be dual stack for some time, but perhaps there is a future possibility that IPv6-only Lambda could be a thing – ditching the IPv4 requirement completely for use cases that support. Even then, having a VPC lambda connecting to an IPv6 only subnet, but with DNS64 and NAT64 enabled, would perhaps still permit backwards connectivity to IPv4 only services. It’s a few hops to jump through, but could be useful when there is very rare IPv4-only services being accessed from your code.
For anyone learning AWS, then online learning platform that is Skillbuilder.aws is a well known resource. It took over from training.aws as the training platform several years ago, though the latter lives on in a very minor way – as a bridge between SkillBuilder and the AWS Certification portal.
Many individuals hold AWS certifications – personal I currently hold 9 of them. The majority of people have those certifications in an AWS Training & Certification account that is accessed via logging in via a personal login – something not linked to your employer. This is because certifications remain attached to the individual, not the employer.
Historically, this meant using Logon For Amazon, to use the same credentials you could potentially use on the Amazon.com retail platform. Yes, the same credentials that some people buy underpants with also links to your AWS Certifications.
In the AWS Partner space, individuals often end up needing to acquire AWS Accreditations; however they are not exposed on SkillBuilder.aws to individuals not linked to a recognised AWS Partner organisation. Instead, individuals much register in the AWS Partner portal, using a recognised email address domain that links to a given AWS partner entity.
From the partner portal, a user can then access SkillBuilder, using the AWS Partner Portal as a login provider, triggering the creation of a (second) SkillBuilder login – but this time linked as a Partner account.
This is clearly confusing, having multiple logins.
SkillBuilder has evolved, and now also offers paid subscriptions for enterprises. For that set of organisations, federated logins (SSO) are available.
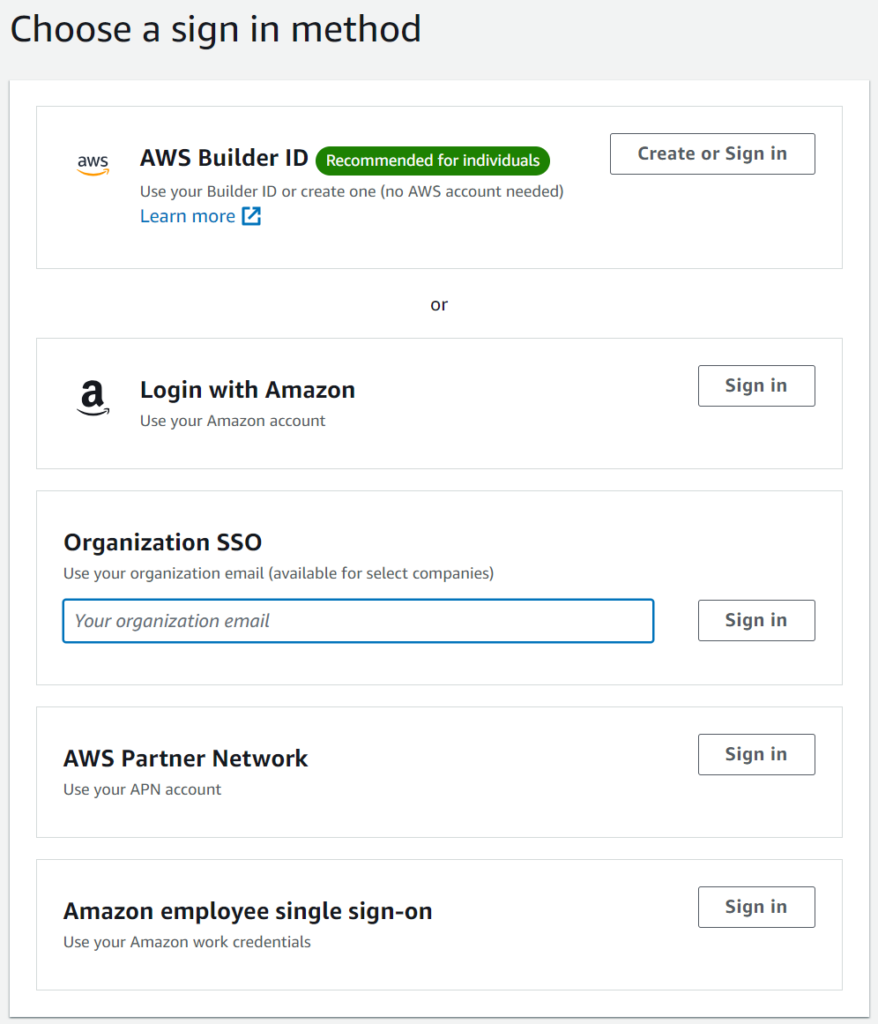
Now, the situation is changing again for individuals. AWS has introduced their separate identity store, called the AWS Builder ID.
Luckily, this new AWS Builder ID does not create a separate identity within SkillBuilder, but adds an additional login for the account linked to your existing Login with Amazon identity.
Onboarding to this is easy. The process validates that you have the email address, and then you can simply use the AWS Builder ID login option where you used to use Login with Amazon.
I’d suggest if you are learning AWS, start using your AWS Builder ID to access SkillBuilder.
I’ve switched to using Unifi a few years back, and made the investment in a Unifi Dream Machine when my home Internet connection exceeded 25 MB/sec — basically when NBN Fibre to the Premises (FTTP) became available in my area, replacing the ADSL circuit previously used.
I’d also shifted ISPs, as I wanted one that gave me native IPv6 so that I can test customer deployments (and be ahead of the curve). I selected Aussie Broadband, and they have been very good.
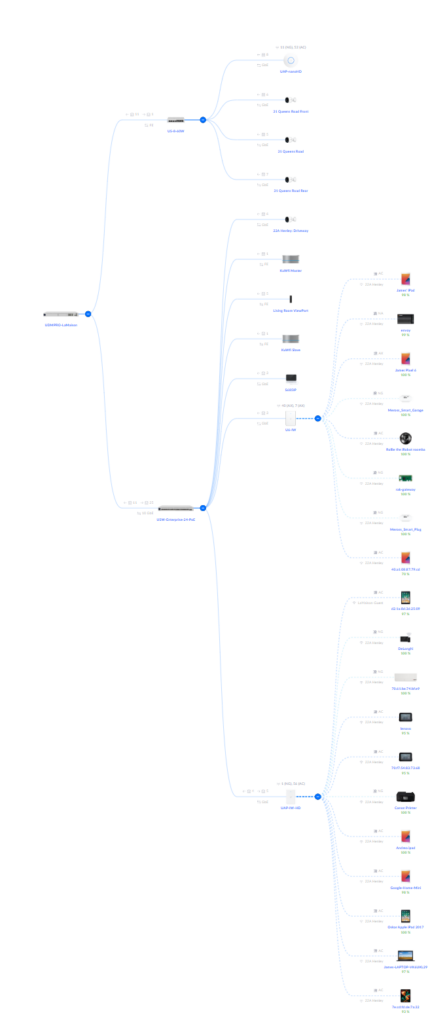
Here’s what my home network topology looks like, according to Unifi:
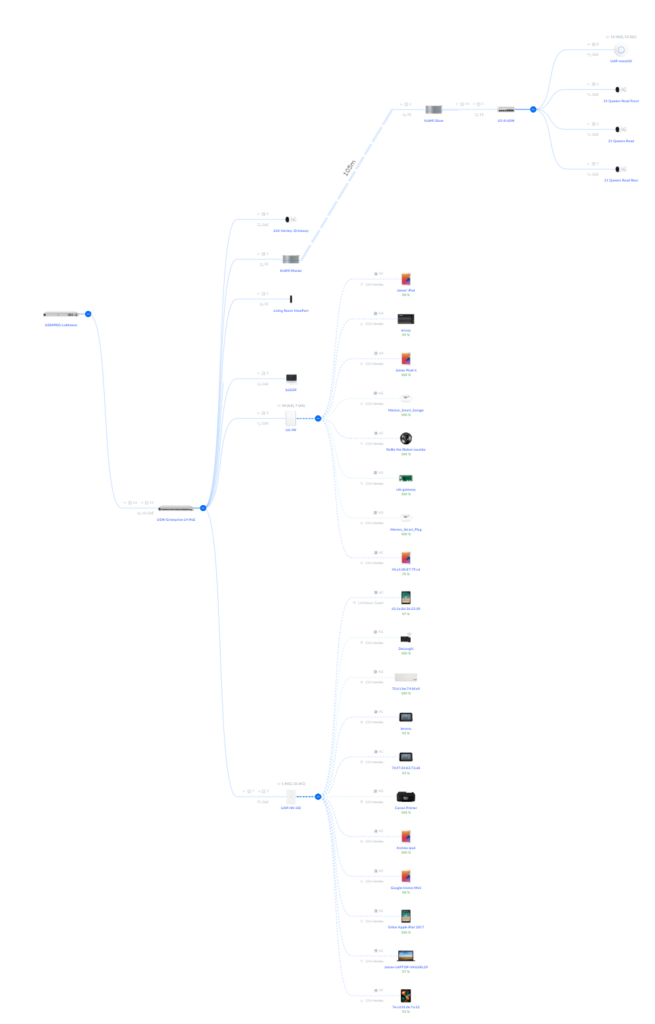
But actually, this is what it really is like:
The difference is the top cluster, which has the two point-to-point devices, separated by around 105 meters (300ft), which the Unifi device does not see.
Meanwhile, my family had a separate property 300 kms away in the southwest of Western Australia, which until two months ago, had been a totally disconnected site: no Internet and no telephone. With aging family members, it was becoming more pressing to have a telephone service available at the property, and resolve the issue of using a mobile hot spot when on site.
At the same time, we had a desire to get some CCTV set up, and my Unifi Protect had been working particularly well for several years now at my location(s) – including over a 100m point-to-point WiFi link.
Once again, we selected Aussie Broadband as an ISP, but a slower Fibre to the Node (FTTN) was delivered, which we weren’t expecting. This required an additional VDSL bridge to convert from the analogue phone line, to ethernet presentation to the UDM SE gateway/router.
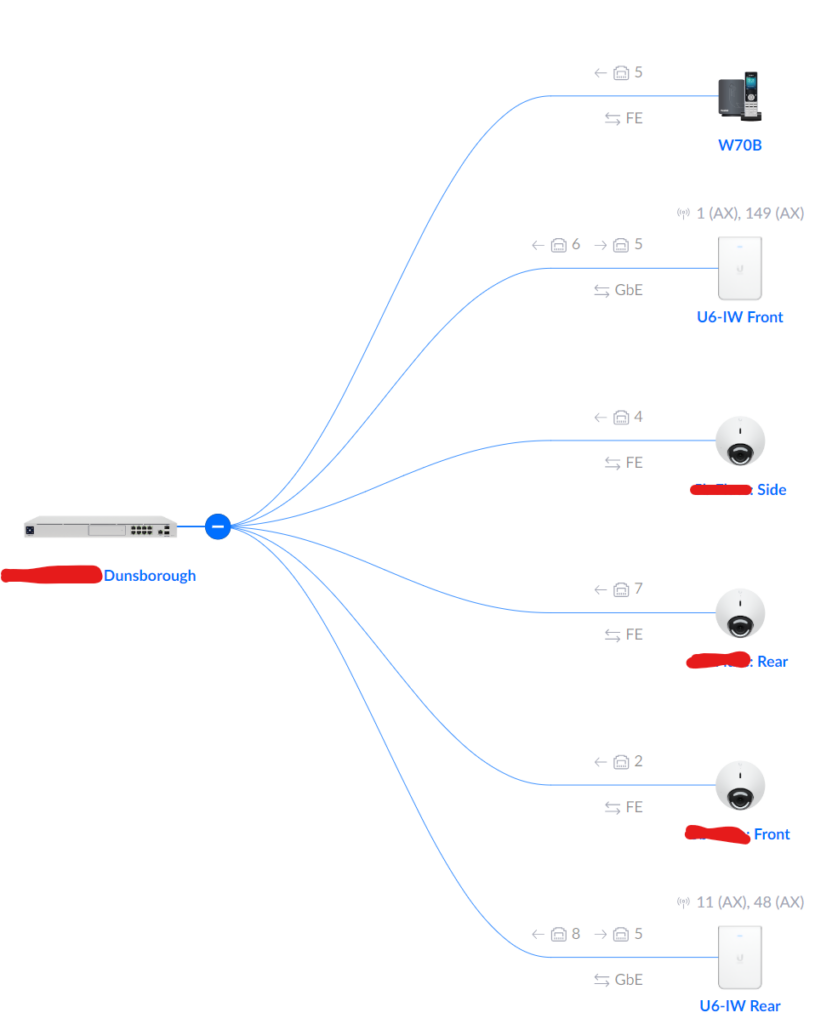
Here’s the topology of the new site:
Easy. The Unifi device has some great remove administration capabilities, which means ensuring everything is working is easy to do when 300 kms away.
Unifi Site Magic
And then this week, I see this:
So I wander over to unifi.ui.com, and try to link my two sites – one subnet at each of the two sites, and it starts to try to connect:
But after a while, I give up. It won’t connect.
I see it only supports IPv4 (at this time). Everything else looks fine…
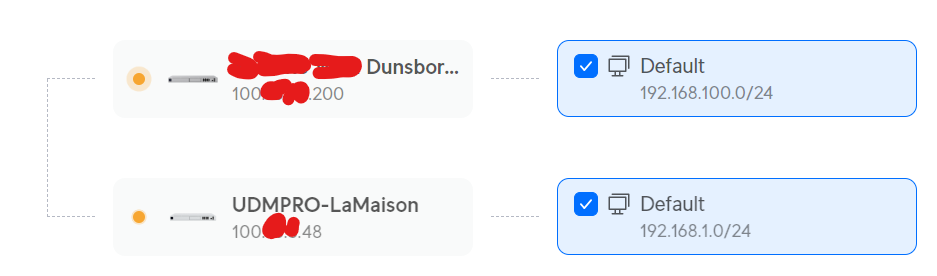
It’s only then (after a post to the Ubiquiti forums) that I’m pointed at the face that both sites are on 100.xxx, which are reserved addresses for Carrier Grade NAT.
A quick look up on the Aussie Broadband site, and I see I can opt out of CGNAT, and today I made that call. Explaining the situation, I requested one site be moved out (I’m not greedy, and IPv4 space is scarce).
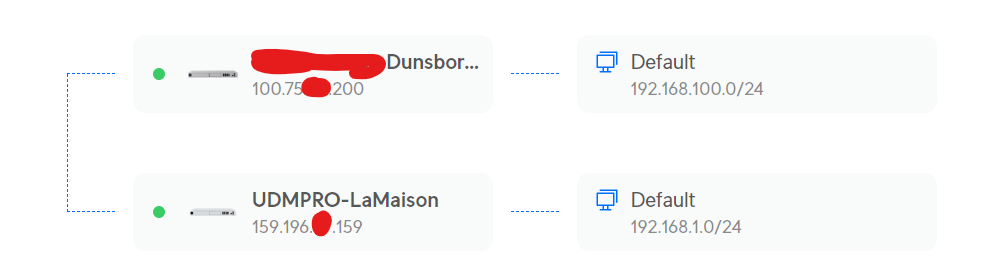
Am hour later, and I have a better outcome:
And now, from Perth, I can ping the VoIP phone on-site 300 kms away behind the router:
C:\Users\james>ping 192.168.100.122
Pinging 192.168.100.122 with 32 bytes of data: Reply from 192.168.100.122: bytes=32 time=19ms TTL=62 Reply from 192.168.100.122: bytes=32 time=20ms TTL=62 Reply from 192.168.100.122: bytes=32 time=19ms TTL=62 Reply from 192.168.100.122: bytes=32 time=19ms TTL=62
Ping statistics for 192.168.100.122: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 19ms, Maximum = 20ms, Average = 19ms
What’s interesting is that only ONE of my sites had to be popped out from behind the ISP’s CGNAT, and the Site Magic worked.
Of course in future, having IPv6 should be sufficient without having to deal with CGNAT.