Amazon CloudFront, the AWS Content Delivery Network (CDN) service, has come a long way since I first saw it launch; I recall a slight chortle when it had 53 points of presence (PoPs) account the world, as CloudFront often (normally?) shares edge location facilities with the Amazon Route53 (Hosted DNS) service.
Today it’s over 400 PoPs, and is used for large and small web acceleration workloads.
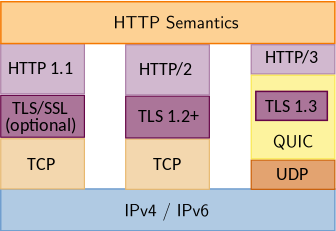
One common pattern is having CloudFront serve static objects (files) that are stored in AWS’s Simple Storage Service, S3. Those static objects are often HTML files, images, Cascading Style Sheet documents, and more. And while S3 has a native Website serving function, it has long been my strong recommendation to my friends and colleagues to not use it, but use CloudFront in front of S3. There’s many reasons for this, one of which is you can configure the TLS certificate handed out, set the minimally permitted TLS version, and inject the various HTTP Security Headers we’ve come to see as minimal requirements for asking web browsers to help secure workloads.
Indeed, having any CDN sit in front of an origin server is an architecture that’s as old as web 2.0 (or more). One consideration her is that you don’t want end users circumventing the CDN and going direct to your origin server; if that origin gets overloaded, then the CDN (which caches) may not be able to fetch content for it’s viewers.
It’s not uncommon for CDNs to exceed 99.99% caching of objects (files), greatly reducing the origin server(s) that host the content. CDNs can also do conditional GET requests against an origin, to check that a cached version of an object (file) has not changed, which helps ensure the cached object can still be served our to visitors.
Ensuring that origin doesn’t get overloaded then becomes a question of blocking all other requests to the origin except those from the CDN. Amzon CloudFront has evolved its pattern over the years, staring with each edge operating independently. As the number of PoPs grew, this became an issue, so a mid tier cache, called the CloudFront Regional Edge, was introduced to help absorb some of that traffic. It’s a pattern that Akamai was using in the 2000’s when it had hundreds/thousands of PoPs.
For S3, the initial approach was to use a CloudFront Origin Identity (OID), which would cause a CloudFront origin request (from the edge, to the origin) to be authenticated against the S3 endpoint. An S3 Bucket Policy could then be applied that would permit access for this identity, and thus protect the origin from denial of service.
The S3 documentation to restrict access to S3 for this is useful.
Here’s an example S3 Bucket policy from where I serve my web content (from various prefixes therein):
{
"Version": "2008-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity E6BL78W5XXXXX"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::xxxxxxxx-my-dev-web-bucket/*"
}
]
}This has now been revised, an in one release post, labelled as legacy and deprecated. The new approach is called an Origin Access Control (OAC), and will give finer-grained control.
One question I look at is the migration from one to another, trying to reach this with minimal (or no) downtime.
In my case, I am not concerned with restricted access to the S3 object to a specific CloudFront distribution ID; I am happy to have one identity that all my CloudFront distributions share against the same S3 Bucket (with different prefixes). As such, my update is straight forward, in that I am going to start by updating the above Bucket policy:
{
"Version": "2008-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity E6BL78W5XXXXX",
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::xxxxxxxx-my-dev-web-bucket/*"
}
]
}With this additional Service line, any CloudFront distribution can now grab objects from my account (possibly across account as well). I can add conditions to this policy as well, such as checking the Distribution IDs, but as part of the migration from OID to OAC we’ll come back to that.
Next up, in the CloudFront Console (or in a Cloud Formation update) we create a new OAC entry, with the v4sig being enabled for origin requests. Here’s the CloudFormation snippet:
OriginControl:
Type: AWS::CloudFront::OriginAccessControl
Properties:
OriginAccessControlConfig:
DisplayName: S3Access
Description: "Access to S3"
OriginType: s3
SigningBehavior: always
SigningProtocol: sigv4Now we have an Origin Access Control, which in the console looks like this:
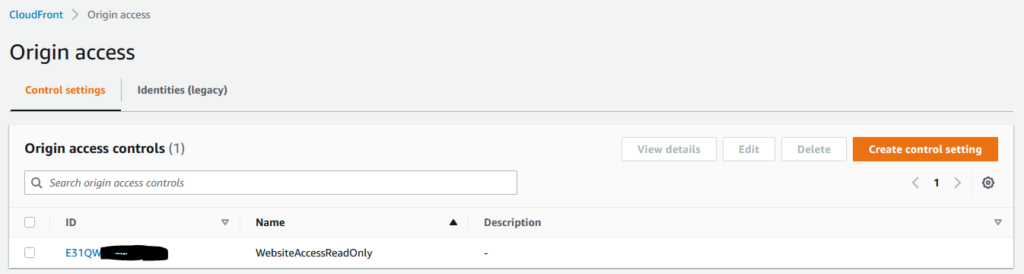
With this in place, then we need to update the CloudFront distributions to use this for each behaviour’s origin.
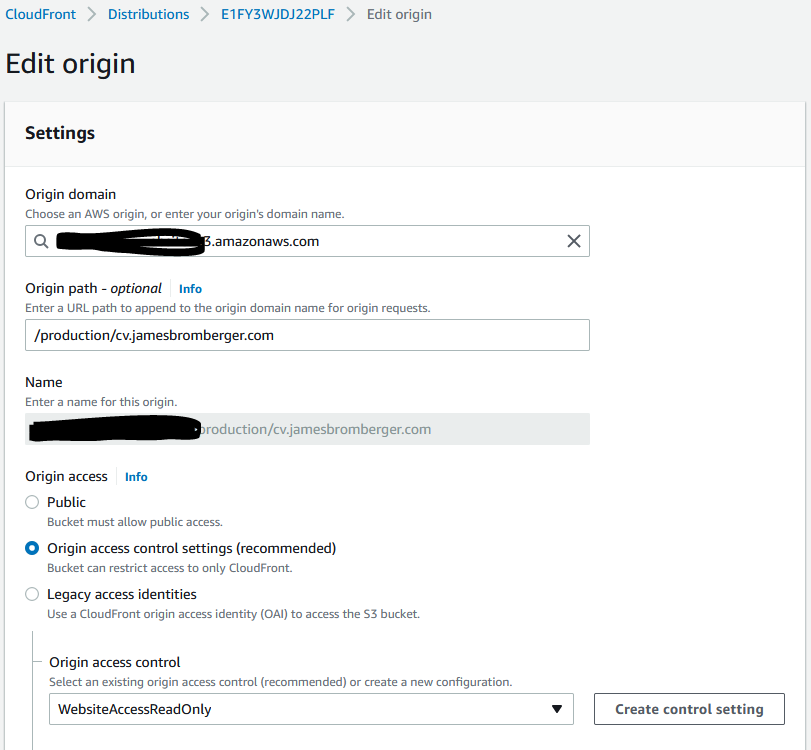
Give it a few minutes, check the content is still being delivered, and then its time to now back out the old CloudFront origin Access identity from the S3 Bucket Policy:
{
"Version": "2008-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::xxxxxxxx-my-dev-web-bucket/*"
}
]
}Then pop back to the CloudFront world and remove the old Origin Access Id (again, but either Cloud Formation update if that’s how you created it, or via the console or API).
This is also a good time to look at the Condition options in that policy, and see if you want to place further restrictions on access to your S3 Bucket, possibly like:
"Condition": {
"StringEquals": {
"AWS:SourceArn": "arn:aws:cloudfront::111122223333:distribution/*"
}
}(where the 1111… number in red is your AWS account number).
AWS has been key to say that:
Any distributions using Origin Access Identity will continue to work and you can continue to use Origin Access Identity for new distributions.
AWS
However, that position may change in future, and given this has already marked the existing OID approach as “legacy“, it’s time to start evaluating your configuration changes.