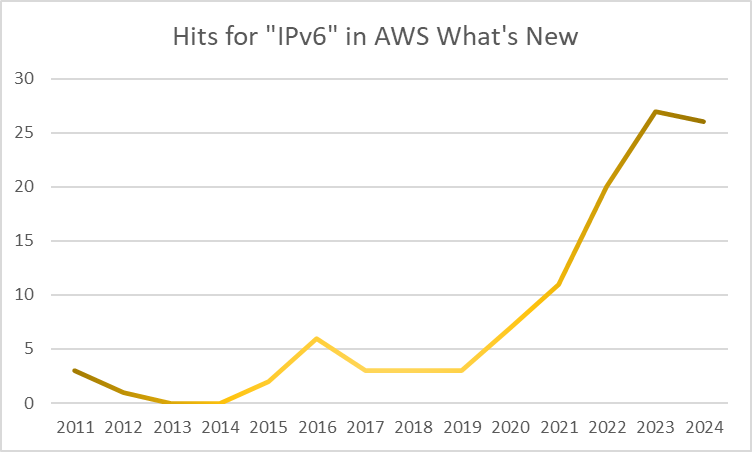
At first glance, this seems like a strange thing to be even mildly excited about.
AWS has been added “dual stack” (having both IPv4 and IPv6 addresses) for their services for some time, and I have blogged about this many times over.
First, lets just go read the brief release, from April 21 of 2025 https://aws.amazon.com/about-aws/whats-new/2025/04/amazon-sqs-internet-protocol-version-6/.
OK, you’re back. First up, how is this working?
Well, the existing API endpoints, such as service.region.amazonaws.com have been extended with a new TLD. While amazonaws.com still exists in documentation, I discovered that dual-stack endpoints are on a different domain (docs), “api.aws”:
{protocol}://{service-code}.{region-code}.api.awsWhile most services do not respond to ping, its a handy way of doing a DNS resolution:
> ping -6 sqs.ap-southeast-2.api.aws
Pinging sqs.ap-southeast-2.api.aws [2406:da70:c000:40:e3db:e3b2:7e93:ef41]
Your library (eg, boto) may not be up to date with this change, and even then, this new endpoint may not be in use.
Pro Tip: always update your boto library.
So why is this useful?
Let’s say you have a workload that uses SQS, running from your existing data centre, on a traditional IPv4-only network. Your application uses SQS as a fan out mechanism to despatch jobs to a fleet of worker nodes. Historically, this set of worker nodes, when listening to SQS for messages, would have had to all used IPv4; now they can exist on IPv6 only networks, and still receive their messages.
In effect, SQS as a control mechanism can now also be a bridge between hosts on either IPv4 or IPv6.
I’ve been championing the use of IPv6 with, in and on AWS since 2012; this year (2025) has continued to see additional services – like this – step up to include seamless dual-stack capability. At some stage, this will become table-stakes, required on service launch, and not a future service innovation.