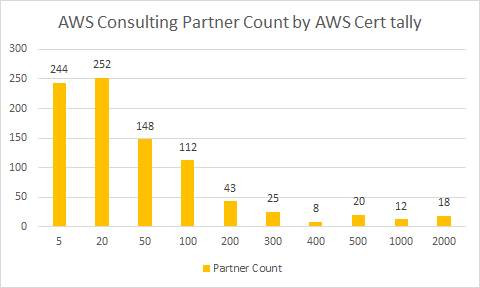
There some 937 partners listed today (25 July 2022) on the AWS Partner Finder who are Consulting Services Partners. Summing together shows around 102,189 AWS Certifications held by there consulting partners (as a minimum), for an average of 115 certifications each.
Some partners show zero certifications, and 244 listed partners have less than 20 AWS certifications in the organisations. 18 organisations are massive with over 2,000 certifications held.
AWS Consulting Partners by AWS Cert tally
As you can see from the graph, after you graduate your Consulting organisation past the 100-199 bucket, the numbers drop off quite markedly; just 126 partners fit in the 200+ certification range.
This is an inexact science, and it will be interesting to review in six months’ time.
In July of 2022, Amazon started to offer some customers the option of a free, physical Multi-Factor Authentication token to help secure AWS Accounts. And (at the time of writing) this is a FIDO2 Multi Factor Authentication (MFA) device.
This is a fantastic step forward.
MFA support for AWS IAM wasintroduced in 2009. Its expanded capability over time included Gemalto key fob devices (off-line, pre-seeded) , SMS text message (with caveats and warnings on using SMS for MFA), and FIDO 2 based devices.
The of-fline key fobs suffered from a few small flaws:
The battery would go flat after some time.
There was no time synchronisation, and time drift would happen to the point of not being able to be corrected if not used for extended periods of time (weeks, months, years).
The SMS approach was fraught with danger due to unauthorised mobile phone subscription take over – whereby someone walks into the retail store and convinces a young assistant that they’ve lost their phone and gets them to vend a replacement SIM card with your number, amongst other approaches.
In 2015, when there was just one AWS training course that wasn’t pre-sales free, Architecting on AWS, I was offering advanced security and operations training on AWS under my training brand, Nephology. Luckily the state of education (and certification) has expanded greatly from AWS (and others), and I no longer need to fill this gap — and my day job has become so busy I don’t get the time (despite missing out on the additional income).
At that time, FIDO2 was not supported by the AWS API and Console.
And thus, every student of Nephology for our AWS Security course from 2015 until I finished delivering my education around 2018, received from me a Gemalto MFA to help secure their master (root) credentials of their primary AWS account. My training also included actually helping enabling the MFA, and the full lifecycle of disabling and re-establishing MFA, as well as what to do when the MFA breaks, is lost, goes flat, or looses time sync.
It was a key enabler, in real terms, to help customers secure their environments better. And clearly, I was 7 years ahead of my time, with AWS now, in limited terms, making a similar offer to some of its customers.
Its amazing today to see the capability usefulness of FIDO2 devices for MFA, and I’ve long since deprecated the physical key fobs in favour of this. So long as the MFA device can be plugged in (USB3, USBC) or connected to (NFC, etc) then they’ll continue to be effective.
The flexibility of being able to use the same FIDO2 MFA device with multiple other services, outside of AWS, means it helps the general security for the individual. No one wants 20 physical MFAs; this really is the one (key) ring to rule them.
I first used a physical VoIP phone when I was living in London, in 2003. It was made by Grandstream, was corded, and registered to a SIP provider in Australia (Simtex, whom I think on longer exist).
It was rock solid. Family and friends in Australia would call our local Perth telephone number, and we’d pick up the ringing phone in London. Calls were untimed, no B-party charging, and calls could last for hours without fear of the cost.
The flexibility of voice over internet was fantastic. At work, I had hard phones in colo cages and office spaces from San Francisco, to New York, Hamburg and London, avoiding international roaming charges completely.
The move to Siemens Gigaset
Sometime around 2008/2009, I swapped the Grandstream set for a Siemens Gigaset DECT wireless system: a VoIP base station, and a set of cordless handsets that used the familiar and reliable DECT protocol. The charging cradle for handsets only required power, meaning the base station could be conveniently stashed right beside the home router – typically with DSL where the phone line was terminated.
It was fantastic; multiple handsets, and the ability to host two simultaneous, independent (parallel) phone calls. In any household, not having to argue for who was hogging the phone, and missed inbound calls was awesome. And those two simultaneous calls were from either the same SIP registration or up to 6 SIP registrations.
Fast forward to 2022, and I still use the exact, same system, some 13 years later. I’ve added additional handsets. I’ve switched calling providers (twice). Yes, we have mobile phones, but sadly, being 8,140 meters from the Perth CBD is too far for my cell phone carrier (Singtel Optus) to have reliable indoor coverage. Yes, I could switch to Telstra, for 3x the price, and 1/3 the data allowance per month (but at least I’d get working mobile IPv6 then).
Gigaset has changed hands a few times, and while I’ve looked at many competitors over the years, I haven’t found any that have wrapped up the multi-DECT handset, answer phone, VOIP capability as well.
Yes, there are some rubbish features. I do not need my star sign displayed on the phone. Gigaset themselves as a SIP registrar has been unnecessary for me (YMMV).
And there are some milder frustrations; like each handset having its own address book, and a clunky Bluetooth sync & import to a laptop, or each handset having its own history of calls made. And, no IPv6 SIP registration.
What they haven’t done (that I have found) is make it clear which model is newer, and which models are superseded. Indeed, just discovering some of the models of base station in the domestic consumer range is difficult.
So the base station: which model is current? A Go Box 100? N 300? Comfort A IP flex? N300? Try finding the N300 on the gigset.com web site!
Can I easily compare base station capabilities/differneces without comparing the handsets – no!
I am looking for a base station that now supports IPv6, and possibly three simultaneous calls (two is good, but three would be better).
I keep returning to gigaset.com to hope they have improved the way they present their product line up, but alas, after 5 years or looking, it’s not got any better. It’s a great product, fantastic engineering, let down by confusing messaging and sales. At least put the release year in the tech spec so we can deduce what is older and what is newer, for both handsets and base station.
I feel that if Gigaset made their procurement of base station and handsets clearer they’d sell far more.
I try and stay as up-to-date with all things Cloud, and have done for the better part of a decade and a bit. But I recently came across a social media post entitled “Is it safe to move to the cloud?“, and with this much experience, I had so many immediate thoughts, that this post thus precipitated.
My immediate reaction was “Is it safe to NOT move to The Cloud?“, but then I thought about the underlying problems with all digital solutions. And the key issue is understanding TCO, and ensuring the right cost is being endured over the operating time of the solution, rather than the least cost as is so typical.
The truth is that with digital systems, things change all the time. And if those systems are facing untrusted networks (such as the Internet), or processing untrusted data (such as came from humans) then there are issues lurking.
Let me take a moment to point out, as an example, any Java implementation that used the very popular Log4J library to handle error messages. Last December (2021) a serious vulnerability arose that meant that if you logged a certain message, then it would trigger an issue. Quite often error messages being raised include the offending input that failed validation or caused an exception, and thus, you could have untrusted data triggering a vulnerability via this (wildly popular and heavily used) library.
It’s not that anyone had done anything bad on purpose. No one had spotted it (and reported it to the developer of the library) earlier.
Of course, the correct thing happened: an updated version of this library was released. And then other vendors of solutions updated their products that included this newer version of the Log4J library. And then your operations team updated your deployment of this application.
Or did they.
There’s a phrase that fills me with fear in IT operations: “Transition to Support“. It indicates we’re punting the operational responsibility of the solution to a team that a did not build it, and do not now how to make major changes to the application. We’re sending to to a team that already look after other digital solutions, and adding one more thing to their work for them to check is operational, and for them to maintain — which, as they are often overwhelmed with multiple solutions, they do the simplest thing: check it is operational, not that it is Well Maintained.
Transition to support: the death knell for Well-Maintained systems
James Bromberger
I’ve seen first hand that critical enterprise systems, line-of-business processing that is the core of the business, is best served when the smart people who built it, stay to operate it in a DevOps approach. This team can make the major surgical changes that happen after deployment, and as business conditions and cyber threats change.
The concern here is cost. Development teams cost more than dumping large numbers of systems on under staffed Support teams. Or support gets sent offshore to external providers who may spend 30 seconds checking the system works, but no time investigating the error messages and their resolution that may require a software update.
It’s a question of cost.
A short-term CIO makes their hero status by cutting costs. Immediately this has only a positive impact on the balance sheet. But as time goes on, the risks of poor maintenance goes up. But after the financial year has ended, and short term EBITDA shows massive growth, and a heroes party is given for the CIO, they then miraculously depart for another job based on the short term success.
Next up, the original company finds that their digital solution needs to be updated, but there is no one who understands it to make such a change.
The smart people were let go of. They were seen as a cost, not part of the business.
So lets rephrase the question: “Is it safe to move to the cloud with your current IT management and maintenance approach?” Possibly not: you probably have to modify the way you do a lot of things, including how you structure your teams and Org Unit. You may need to up-weight training for teams who will now take on full responsibility for workloads, instead of just being “the network guy”. But this is an opportunity; those teams can now feel that THEY are the service team for a workload that supports something more substantial than just rack-and-stack of storage. Moving to separate DevOps teams per critical workload, you can then have them independently innovate – but collaborate on standards and improvements. a friendly competition on addressing technical debt, or number of user feature improvements requested – and satisfied.
So is it safe to move to the Cloud? It depends on who is doing, how much knowledge and experience they have, and what happens next in your operating model.
The Cloud is not just another data centre. And TCO isn’t just cloud costs, and it isn’t just people cost. Sometimes the cost is the compliance failure and fine you get by inadvertently removing the operating model that would have prevented a data breach.
Its been 7 years since I (and my colleagues at Ajilon/Modis, soon to be Akkodis) moved the Land Registry of Western Australia, the critical government registry of property ownership of the state, into the AWS Cloud for Landgate. We’ve kept a DevOps approach for the solution – ensuring it was not just Well-Architected, but Well Maintained. It’s a small DevOps crew now that ensure that Java Updates, 3rd party library updates and more get imported, but also maintenance of the Cloud environment such as load balancing, virtual machine types & images (AMIs) get updated, managed relational database versions get updated, newer TLS versions get supported and — more importantly — older versions get deprecated and disabled. FinOps, DevOps, and collaboration.
One thing is sure, these days every political party has a website to publish their message, and right now its one of their key places to disseminate their content from – often reticulating from the web site to the wider broadcast media.
As a source of truth for each party, how well are they implementing modern web security that’s free to implement and use?
I’ve used a number of tools in the past, but I chose just two to do a straw poll to examine them.
The first is Scott Helm’s SecurityHeaders.com. A simple rating A through F gives the general overview of the way the curators of the various sites have activated browser support to help ensure their content – and the visitors to their sites – are as protected as possible.
Scott does a fantastic job of adjusting the ratings over time, as new capabilities are established as commonplace amongst the major web browser platforms. It’s a free service to check any site, publicly available, and you can check your favourite site (such as your employer, or band) right now!
The second services is Qualys’ SSLLabs.com (originally by Ivan Ristic, who now operates hardenize.com – worth a look too). Instead of looking at the simple text headers, SSLLabs looks at the encryption used over the untrusted Internet, and a few other attributes, and again gives an A through F report, so it is easy to understand who does a good job, and who is not quite there yet.
The Australian Labour Party
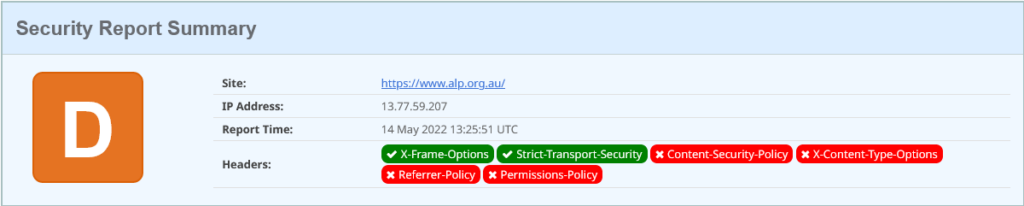
The ALP lives at https://www.alp.org.au/. Let’s start with the simple security headers rating:
D rating for alp.org.au on 14 May 2022
That’ s a pretty poor outing. The first header activated is a legacy security header used to instruct browsers about having content rendered with iframe and frame HTML elements – these days accomplished via a Content Security Policy. Secondly they have indicated to browsers that their site is an HTTPS site and should only ever be contacted using encrypted communications (TLS, or HTTPS), and never over plain-text unencrypted HTTP.
So what?
Content Security Policies (CSPs) are about to become a mandated part of the Payment Card Industry (PCI) Data Security Standard, currently in draft, that any payment page on the Internet (you know, the one you use every day when you buy something online and enter card holder details) will be required to have a CSP to help protect the security of the web page. A CSP doesn’t cost anything, it’s just a text field letting your browser know boundaries from where it can fetch additional content to render the page. And if it’s good enough for a payment page, then its good enough for anything you’re trying to have a strong security reputation on.
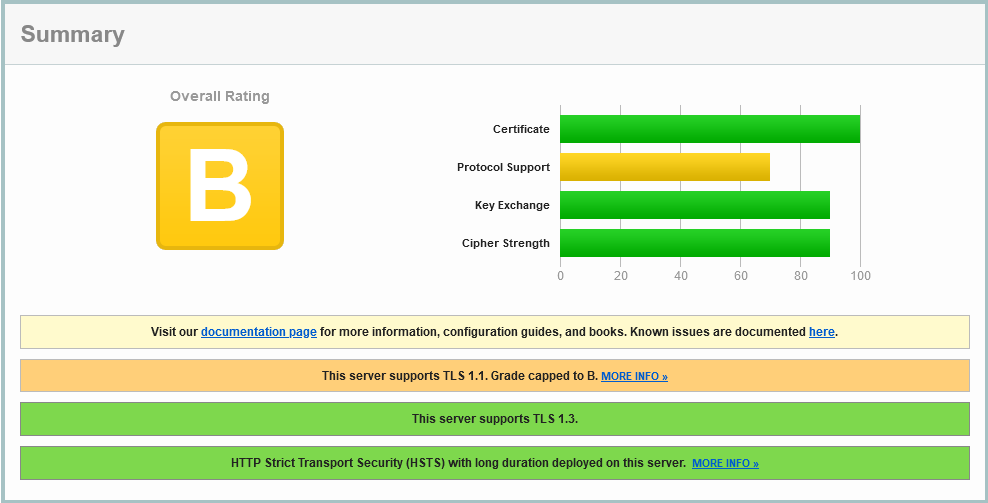
OK, let’s move to the TLS (formerly called SSL) strength, with SSLLabs:
ALP.org.au on SSLLabs on 14 May 2022
Well, they’ve left the older TLS 1.1 protocol enabled. That’s been deprecated since around 2016, so only 6 years out of date. It’ s nice to see the newest TLS 1.3 is enabled here, and the encryption ciphers are ordered with stronger crypto before weaker ciphers (why are those older ones still enabled, as they are likely ever legitimately used?). The test shows that the more efficient HTTP2 has not been enabled, and the simple Certificate Authority Authorization record in DNS has not been set – which helps declare which Certificate Authorities are permitted to issue the trust certificates for alp.org.au.
We notice that there is just one IPv4 address returned when doing this check which raises a few questions:
there is no apparent Content Delivery Network in place
dual-stack support for IPv6 has not been enabled
there’s possibly only one site for this service to run from?
A traceroute for this appears to disappear into MSN.net in Melbourne.
Liberal Party of Australia
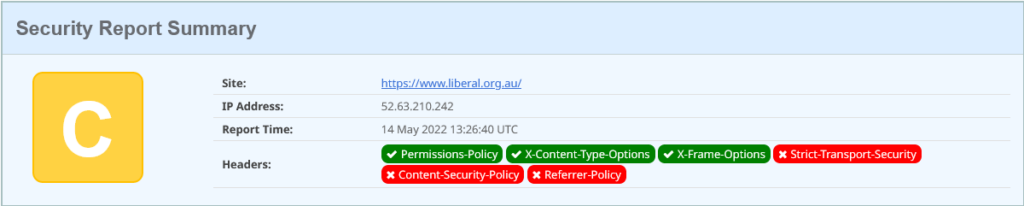
Move to the Liberals who are at https://www.liberal.org.au/. Cranking up Security Headers shows:
liberal.org.au on Security Headers.com on 14 May 2022
This is just marginally better than the Labour Party: they have enabled one extra header: the Permission Policy. This tells the browser what capabilities its allowed to use when rendering your content.
Its a good start: but the policy contains just “interest-cohort=()”. This policy is opting out of Google Analytics cohort analysis. as shown here, but its only supported on the Chrome browser. They’ve missed the chance to disable geo-location and other browser capabilities to protect their viewers.
The configured headers the admin has left enabled declare they have a Varnish Cache, and Apache/2.4.29. I’d recommend turning off as much of this identification as possible (hey admin, look up: ServerTokens PROD).
OK, on to SSLLabs analysis, but as we do, we get a different initial screen compared to our first review:
libaeral.org.au on SSL labs on 14 May 2022
This time, we’ve detected two distinct site locations that this content has been served from. Again we’re only talking IPv4, but the reverse DNS shown gives away where; the AWS Sydney Region (which I helped launch as an AWS staff member in 2013).
This is possibly an AWS managed load balancer, configured across two Availability Zones (for those coming here for the first time, an Availability Zone, or AZ, is a cluster of data centres, so each AZ can be through of as a site: Central North Sydney, South Sydney. Indeed, The Sydney AWS Region has three AZs available as at May 2022, and not using the third AZ when its just sitting there is possibly a missed opportunity for higher fault tolerance.
Of course, both site locations are configured identically so we already know they rate as an A, so we can inspect any of the two in detail:
libaeral.org.au on SSLLabs on 14 May 2022
That’s pretty satisfying to start with.
We still note a missing DNS Certificate Authority Authorization (CAA) entry, as per the Labour Party. But we note that ONLY TLS 1.2 is enabled, and not the current best-in-show, TLS 1.3 (which is slightly optimised in connection establishment).
What is unusual is the ordering of the encryption ciphers here; some weaker ones are priorities over stronger ones:
liberal.org.au on SSL labs on 14 May 2022
Normally you would want your strongest encryption ciphers first before the ones that are known to be weak are selected (or better yet, don’t even support the weak ones).
We note that only HTTP 1.0 is supported, not HTTP/1.1 not HTTP/2.
The Australian Greens
Start with the headers:
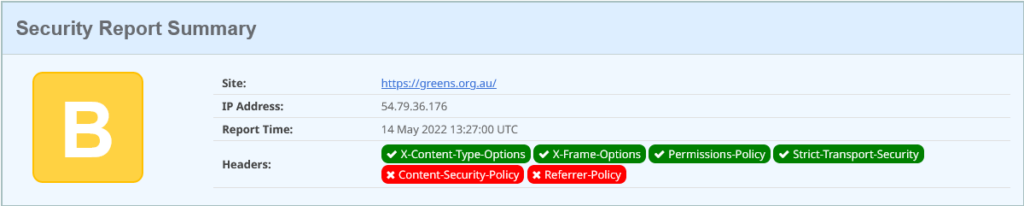
greens.org.au on Securityheaders.com on 14 May 2022
This is looking marginally more polished. It’s a Drupal 9 site (the headers show this – would be good to not advertise it). This time one additional legacy security header is set: x-content-type-options; this tells browsers to trust the mime content-type that is sent with objects, and not try and double-guess them (if the website admin got it wrong). For example, if we try and download an image, and the response is a content-type of image/jpeg, but the payload is JavaScript, then treat it as a broken image! Don’t keep guessing as browsers have in the past, as that guessing may trick the browser into executing some browser code that the admin had not intended.
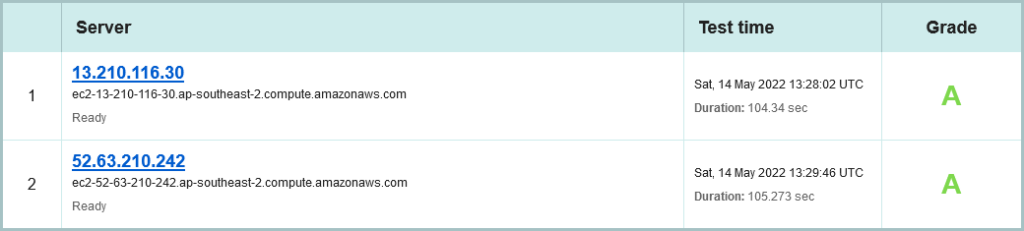
OK, move to the crypto on SSLLabs – and this time we have three sites serving this content:
greens.org.au on SSL Labs on 14 May 2022
Nice, the Greens are also using AWS in Sydney, and are spread across all three Availability zones. (Shout out to an old friend: Grahame Bowland, are you doing this? 😉 ). Its still only IPv4, sadly. But already see see a stellar A+ rating:
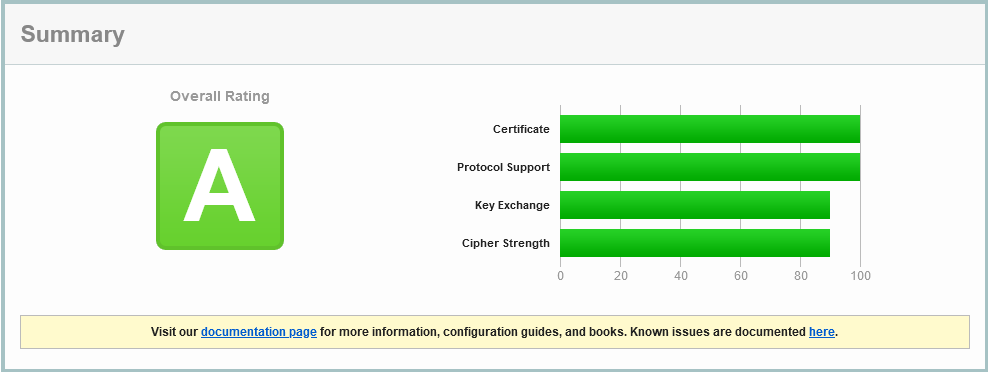
greens.org.au on SSL Labs on 14 May 2022
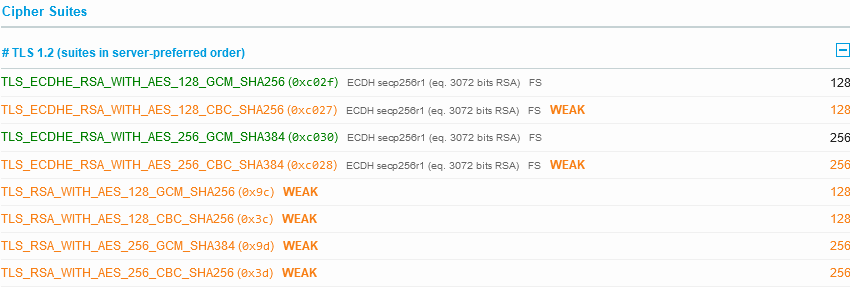
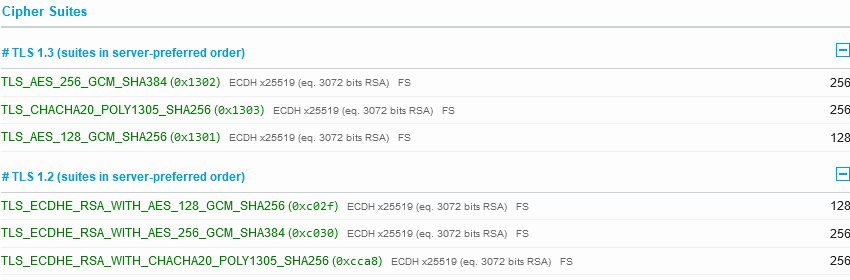
The same DNS CAA record is missing, but we see HTTP/2 is enabled, as well as just TLS 1.2 and 1.3. More over the cipher suite is super strong, with nothing weak supported:
greens.org.au on SSL Lab son 14 May 2022
This is what a site that doesn’t take weak encryption as acceptable is supposed to look like!
The Climate200 Collective
There are a lot of candidates under this umbrella, and instead of reviewing them all independently, I’ll just pop over to https://www.climate200.com.au/. Lets roll with security headers:
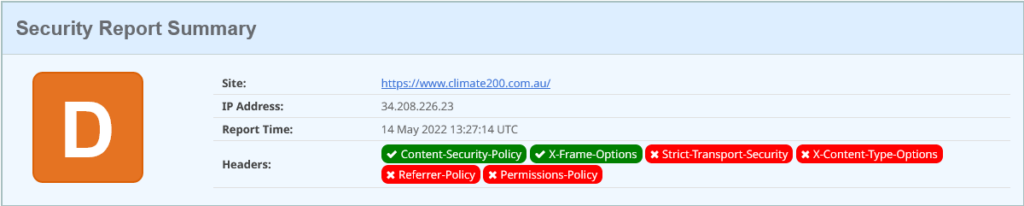
climate200.com.au on SecurityHeaders.com on 14 May 2022
But this is stronger than it looks, because we finally have a Content Security Policy. However the extend of the policy is to limit frames and iframes, with “frame-ancestors ‘self’“. So much more has been missed, like enforcing everything the browser loads comes form the same domain, over HTTPS.
Now, headers are indicating this is an Open Resty server running on Containers (with Kubernetes management) in AWS’s US West 2 Region – also known as the AWS Oregon Region. AWS often speaks of this Region as running from a lot of green energy, which may be the reason for this.
OK, lets scoot to the network transport encryption report from SSL Labs, and again we have the three site presentation choice:
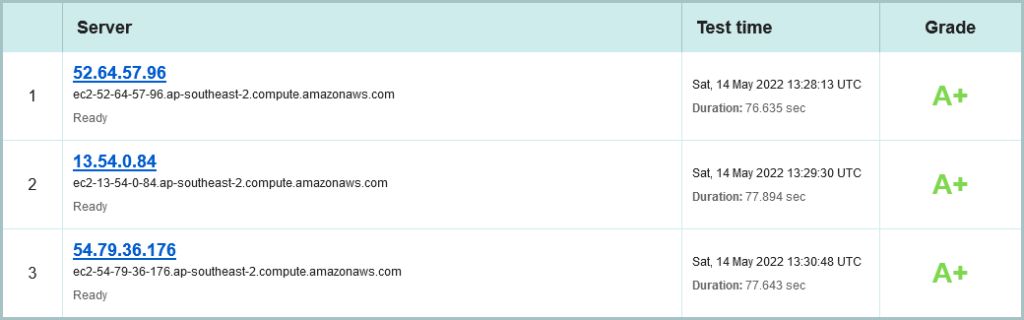
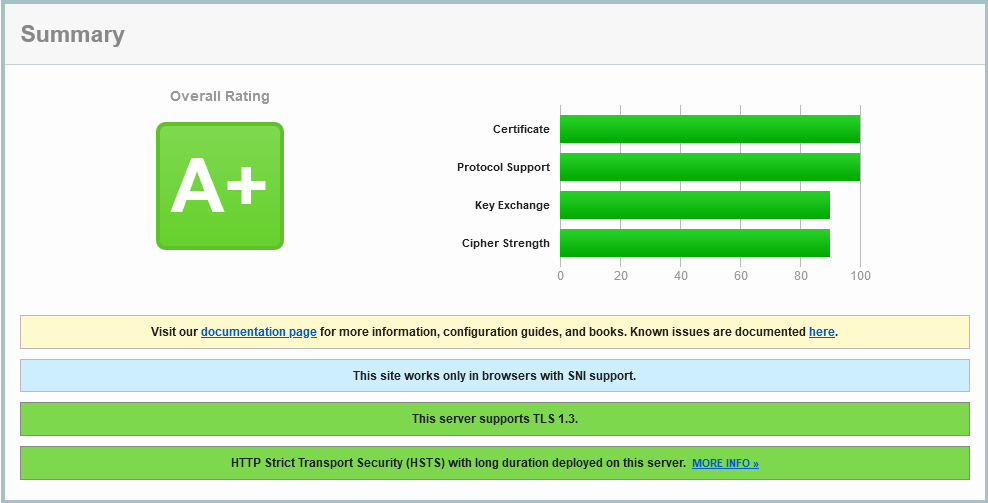
climate200.com.au on SSLLabs on 14 May 2022
As with SecurityHeaders.com, the confirmation of using AWS, this time US-west-2 (Oregon) Region. All sites rating an A, but only using IPv4.
The Australian Election Commission
Now lets look at who is running the election, the AEC. A hat tip to their social media team who have been having a right ripper time with some bon humeur in the lead up to Democracy Sausage day (many polling booths in Australia will have a local, volunteer, non-partisan community group running a barbecue (bbq) with a sausage in a roll, possibly with grilled onion – oh I can smell it now!).
Right, AEC, how are your security headers:
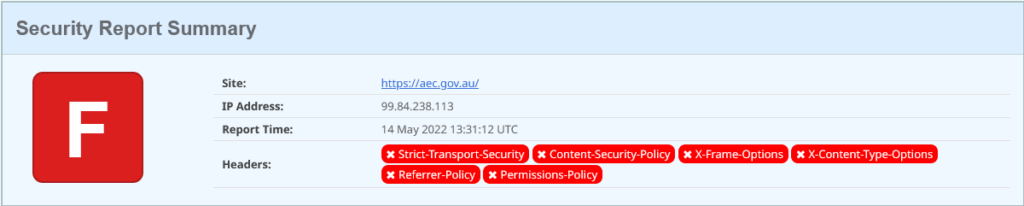
aec.gov.au on Security headers on 14 may 2022
Oh. Erm.
Lets move to your crypto and see if we can recover this:
aec.gov.au on SSLLabs on 14 May 2022
What a save! They are using a Content Delivery Network (CDN) to front their origin web service. That’s the fourth time in this article it’s been an AWS based service as well, but again its IPv4 only. Let’s lean in to the first site:
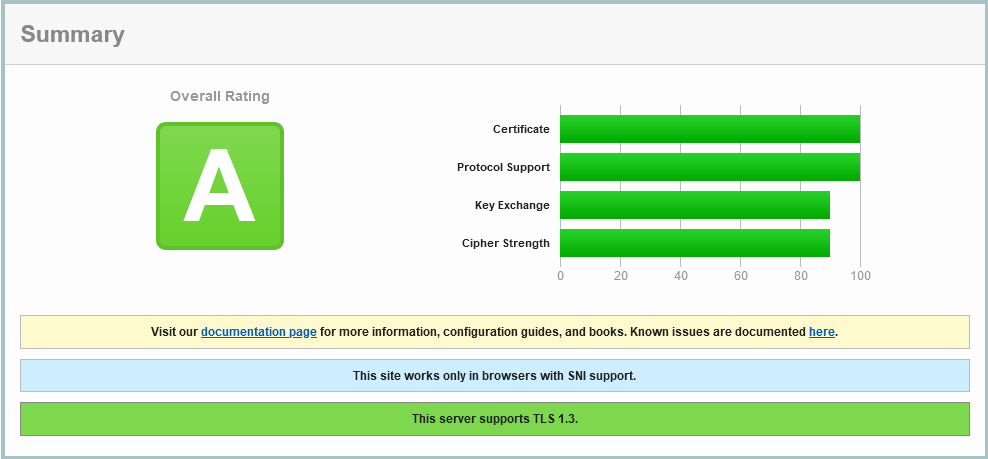
aec.gov.au on SSLLabs.com on 14 May 2022
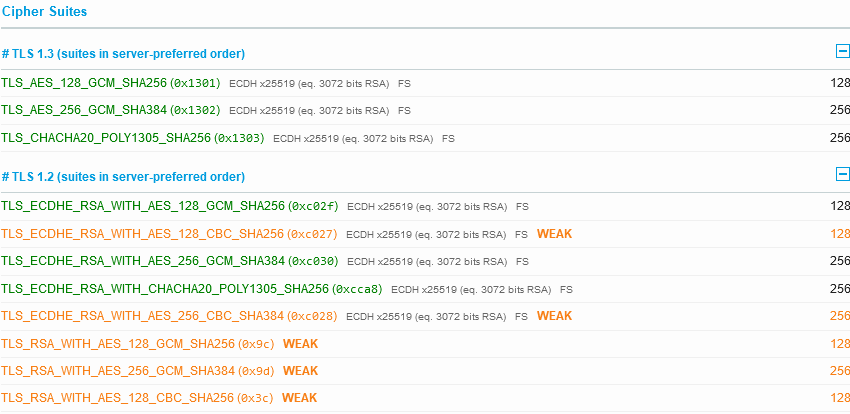
So we have TLS 1.3 enabled, with TLS 1.2 as a backdrop, but none of the older risky protocols. Nice. But the ciphers for TLS 1.2 are a little confused:
aec.gov.au on SSLLabs.com on 14 May 2022
That CBC use of AES in yellow should be either below the other green ones, or removed. However, custom configuration is very limited with Amazon CloudFront; AWS does permit you to chose some good TLS options (I’ve worked for years with them to ensure these choices are available to customers).
Moving down the details shown, we saw HTTP/1.0, 1.1 and 2 are all available, which is also good.
An Overview
Lets put those ratings for the above organisations, and add a few more for good order, into a table:
None of them have populated a DNS CAA record to help ensure only their authorised Certificate Authority is issuing certificates in their name.
Minor parties are using CloudFlare and permitting IPv6; none of the major parties have discovered IPv6!
None of them have strong Content Security Policies
Most major parties and the AEC are AWS Customers.
I didn’t observe any of them implement Network Error Logging (NEL). Now there’s a nice feedback loop to help detect web security incidents as they happen…
So who would I chose as my winner here? It would be… the Greens, with the stronger ratings they have. There’s still room for improvement (like dual-stack IPv6, using CloudFront, a proper CSP), but they are ahead of the rest leading both of these basic assessments.
And the loser? Well, let’s not punch down too much; the explanations here are plain enough for any tech to follow the bouncing ball and enable better security, availability, and speed (at no additional cost!).
Does this make any difference to policies, fairness, environment (well, Australian Greens are using the AWS Oregon Region)? No, not really right now. I doubt any future minister for telecommunications is going to understand if the simple security adjustments shown could help increase security in any cyber attack. I just find this interesting…
As always, my thanks to Scott Helme for Security Headers, Ivan Ristic for SSLLabs, and the people who contribute to web and browser security improvements.