In 2010 my family returned to Australia to raise our child (now children) from the UK. I needed a local mobile phone service, and I selected Optus, as their pricing and offering (included data) was about right.
After a few years, I settled in to a $39/month, 30 GB plan. Around 2024, Optus advised me that the $39/month plan was becoming $49/month, with the same inclusions.
This week, another update from Optus advised this was now going to be $55/month, but the included data would increase to 70GB/month.
These days, I barely use more than 2 GB /month when I am not either at home or in one of my company’s offices… on the WiFi.
Enough.
There’s been very little visible improvement to the Optus network in the 21 years I have been on it. It’s over a decade since their competitor, Telstra, introduced IPv6 for their subscribers, and Optus has done… nothing.
The porting process took less than 30 minutes, and to be fair, the provider I have swapped to doesn’t do IPv6. But they are $25/month for 20 GB of traffic.
So I have just saved $360/year for what is approximately the same service. From complacent customer to ported away in four days end-to-end.
It’s taken a long time, but the top of the chart of AWS Cloud consulting services partners has had a shake up on the leader board.
It’s not scientific, and could mean nothing, but I have been tracking the reported number of AWS Cloud certifications across the AWS Partner Community for a while now. It is a limited view into the commitment of these organisations to get their staff knowledge validated, at some level. That level could be Foundational (and thus non-technical), or it could be through to specialist. And for the last few years, the worlds largest partner by this metric has been Accenture.
But not today.
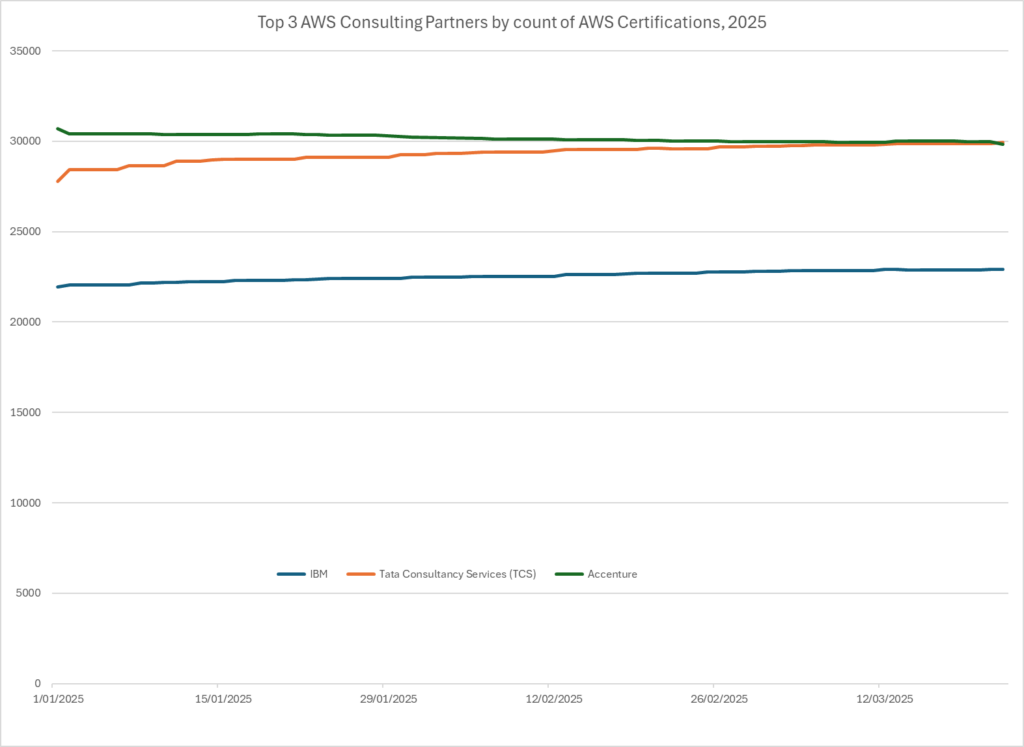
Today, Tata Consulting (TCS) overtook Accenture. Here’s the plot per day since the start of 2025, and the orange line (TCS) has just poked through the green line (Accenture):
TCS now stands in 1st spot with 29, 947, compared to 29,845 for Accenture, a gap of 102 AWS Cloud certifications.
Yesterday, Accenture was still in front on 29,983, and TCS was just 113 behind.
At it’s peak, Accenture could talk of more than 36,000 AWS Certifications. But in the recent past, this number has been steadily declining, while TCS and the rest of the providers have generally been ascending.
I have not seen any indication why Accenture’s total attributed AWS Certifications have been dropping. Perhaps a policy on paying the charges for their staff for re-certifications, perhaps staff attrition, mergers and de-merges. Perhaps a bunch of people who achieved the Cloud Practitioner (non-technical) 3 years ago as some initiative changed focus and let them expire.
Either way, it seems that the focus and drive that Accenture had shown, is not matched by the focus of TCS.
Does this matter in the AWS Cloud partner ecosystem? Perhaps not. But I find it interesting to consider.
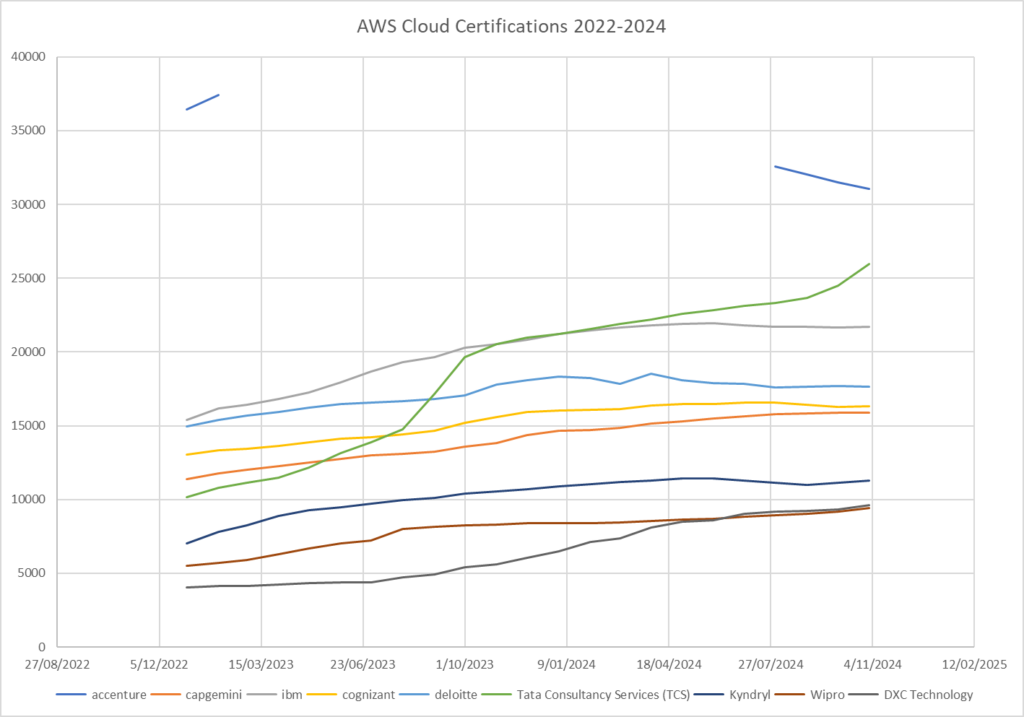
I track the capability of the consulting services partners by a number of attributes. Here is what the top 9 look like, by count of AWS Certifications, for the last two years until November 2024:
A bit of a gap on Accenture data, but still interesting
It appears that Accenture is ín danger of losing its dominant position as the worlds largest AWS Cloud consulting services partner, perhaps sometime in the next three to six months; TCS is accelerating up from what was 6th position in 2022, currently in 2nd position.
It appears that DXC was lagging the others, but has now caught back up.
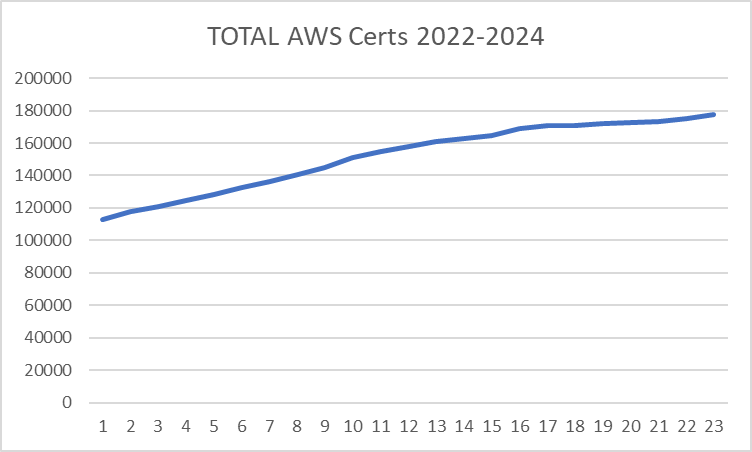
Now lets look at an aggregate total of the top 20 partners’ certifications, excluding Accenture (due to missing data), and see what the ecosystem growth is like:
This looks like there is continuing growth of the number of certs held, growing 57.3% over two years.
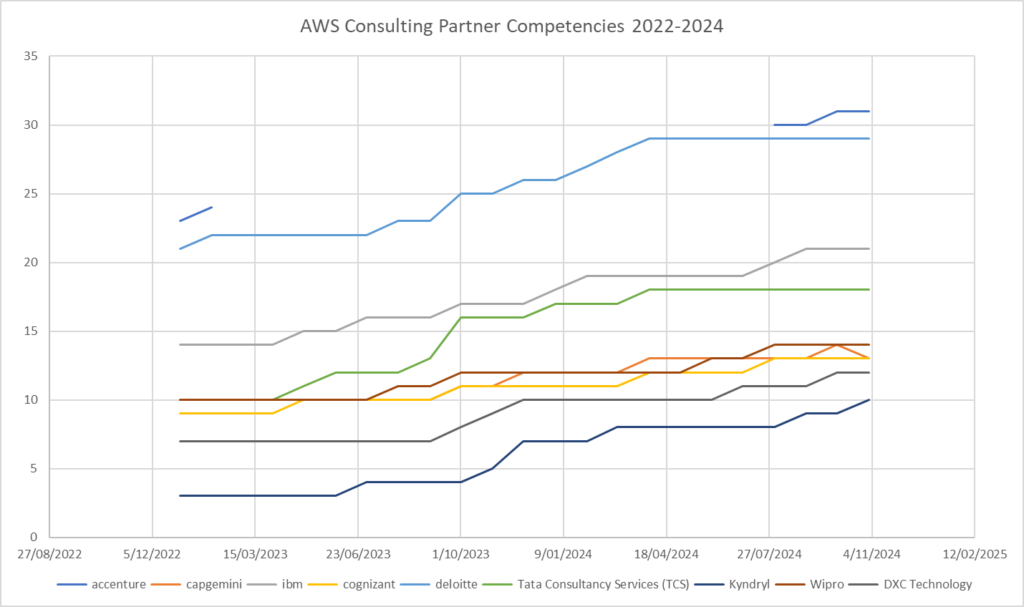
Looking at the AWS Partner Competencies achieved for those top 9 (by certifications held) :
Accenture continues to lead
I find it interesting to derive the focus and attention these organisations are placing on their AWS Cloud skills validation in their workforce.
For many of these, the long trail is the set of individuals who only hold the one certification, which often is the Cloud Practitioner – Foundational cert. This level of validation is aimed at being non-technical, often achieved by sales, marketing, and management folk who do not have the delivery capability to competently deploy a Lambda function or set a security group! However, its beyond my visibility to be able to remove this cert from the totals I can see. This means that the true delivery capability may be very different for these organisations.
When I worked at AWS in 2012-2014, I championed the adoption of IPv6. I’ve spoken about Ipv6 many times on this blog, at AWS User Group Meetings, and with my colleagues at work. We’ve deployed solutions dual-stack for clients where there hasn’t been any cost implications in doing so.
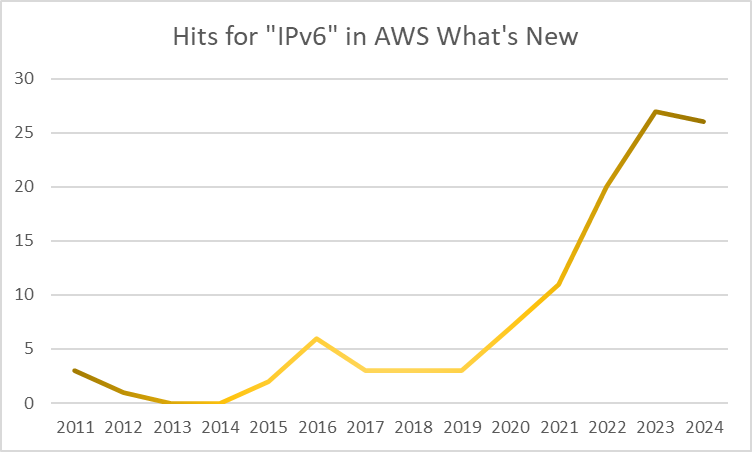
Over time, a number of “What’s new” posts have shown where IPv6 capability has been added. Now after 10 years since I departed AWS, I though I would look at the rate of IPv6 announcements and see =how it stacked up over time.
Clearly we can see an uptick in announcements from 2021 onwards. Additional managed services are still adopting; perhaps the rate of change is leveling out now.
I spent much of the pandemic, from late 2020 until December 2023, building a new family home. In Australia power efficiency for cooling (and heating) are critical. We minimised the size of north-facing windows, and ensured that thermal insulation was installed in the double-brick exterior walls, as well as sisal insulation under the roof tiles and Colorbond sheets, and then standard insulation above the ceilings. Lighting is almost exclusively LEDs.
Exterior (garden) smart lighting is configured to come on at sunset, then dim to 50% brightness at 10pm, and then further dim to 3% at 11pm, turning off at sunrise.
One key point was using our roof space for solar power, and so we commissioned a 10 KW inverter, and a single Tesla Powerwall 2, which was installed post-handover of the property in mid December 2023.
In January of 2024, we saw around 68% of our power usage was from the installed power system. The air conditioner was the biggest draw, on hot days it would run at a draw of 10 – 11 KW, and despite there being energy in the Powerwall, its limit was 5KW in and out (this is now increased in the PowerWall 3).
Even without the air conditioner, most days the PowerWall would be exhausted by around midnight, leaving just the grid supplying until the sun came up the next day.
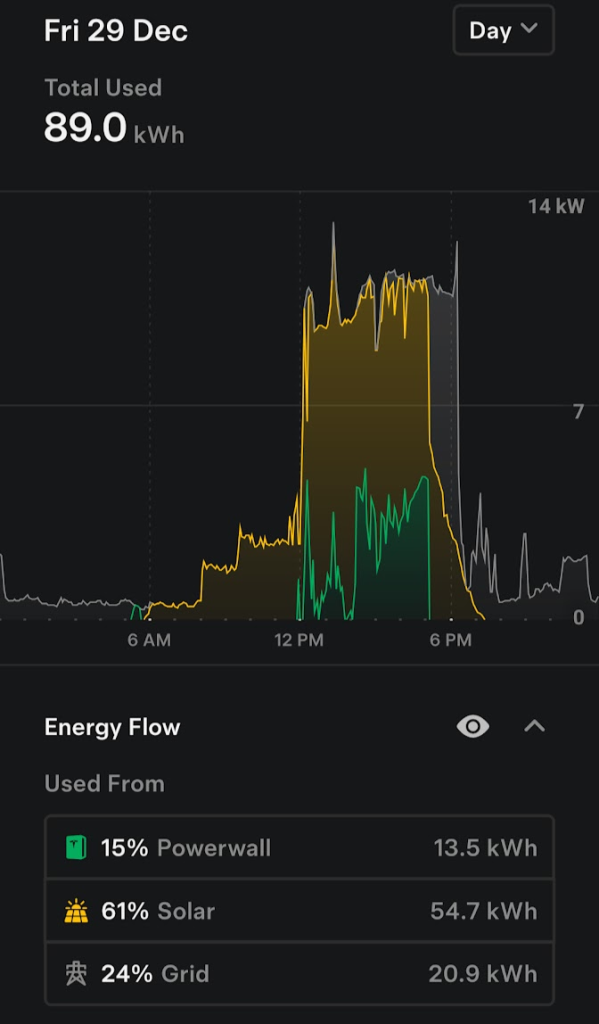
Here’s what December 29th looked like for me:
To further reduce power from the grid, I added a second set of panels on an additional 5KW inverter in May 2024.
By October 2024, the days in the southern hemisphere are getting longer, and the two inverters were at 100% load from mid-morning until 5pm or later, and we hit 90% of power coming from solar + battery for the month.
At this time, the Powerwall 2 was being discontinued, and existing PowerWall 2 installs cannot be expanded with PowerWall 3 units, so we divde in one more time and installed a second PowerWall in late October.
Since that second, we have not purchased any power from the grid.
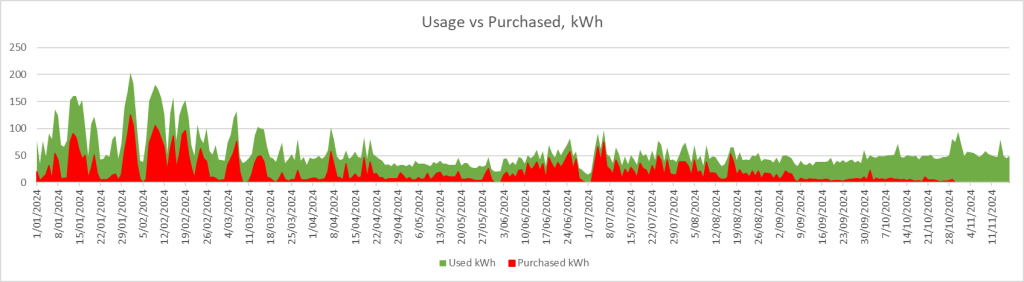
The red is power purchased from the grid; the green is total power consumed.
Of course, we have yet to see the intense heat (and thus air conditioning draw) that February and March shows in my area.
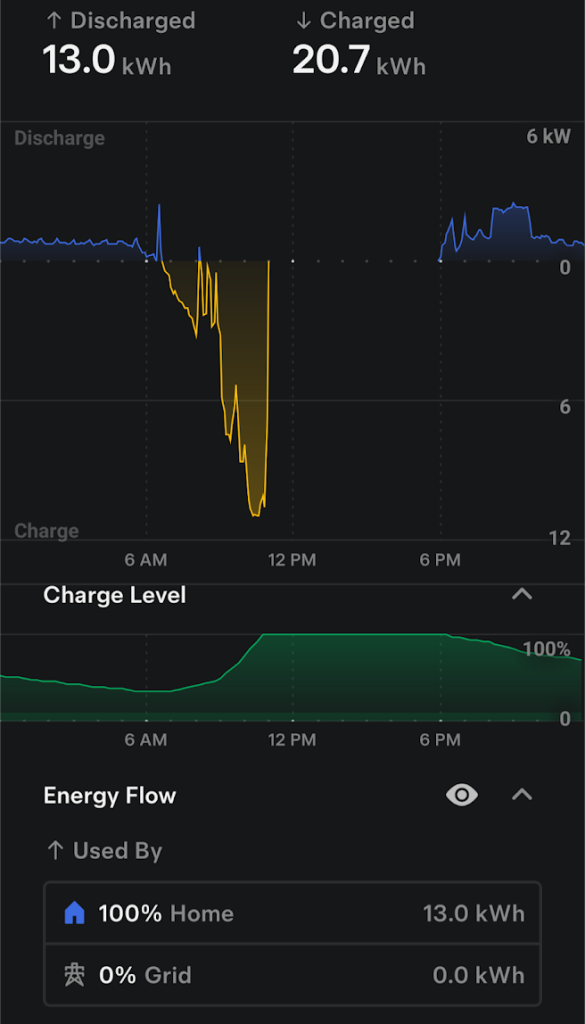
You’ll also note that most of our power usage is in the afternoon and evening, meaning the mornings are great time to charge batteries up:
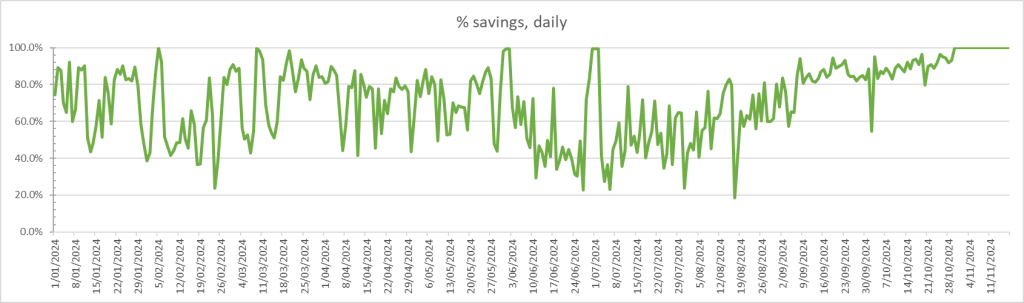
So what does that look like as a percentage saving per day:
The flatline at 100% is since the 2nd PowerWall went in.
I typically work from home these days (a global role that kicks in and out from9am until 10pm or later depending on the teams I am working with), but in an IT role means my work is mostly having my laptop (and screens) on.
One key question is the break even on this. If I use the last 3 weeks worth of data then it works out at a break even time of 7 years and 2 months. The last 300 days shows a 11 year break-even, but most of those 300 days did not have the 2nd PowerWall, nor the additional 5KW of solar generation. I imagine this will end up around an 8 years break even, within the 10 years warranty period of the battery, solar panels and inverters.
Two other points I get asked about:
we put in a total of 15 KW of inverters as we have three phase power to the property; in our area the power company limits the size of inverter(s) you can installed depending upon 3 phase or single phase supply
Having installed more than 5KW, the buy back for power fed back into the grid is $0.00. Nothing. Hence my system is set to reduce the amount fed to the grid, instead of sending as much as possible. If that was even $0.01 I’d remove that limit.
The cost of power from my provider, Synergy, increased on 1 July 2024 from 30.812c/KWH to 31.5823, or 2.5%. The connection fee (without consumption), went up from $1.1046/day, to $1.1322/day (just shy of 2.5%). This means I am still paying $413 per year (and increasing) to be connected to the grid, in case I run out of juice.
While I am no fan of the Tesla owner (and now government appointee?!), the technology appears to be sound, thus far. I’m pleased to have reduced my use of grid power to zero.
Lets see what the next 12 months of data produces.