It’s been a reasonably busy few weeks for me; here’s a recount of the AWS Public Sector Summit in Canberra…
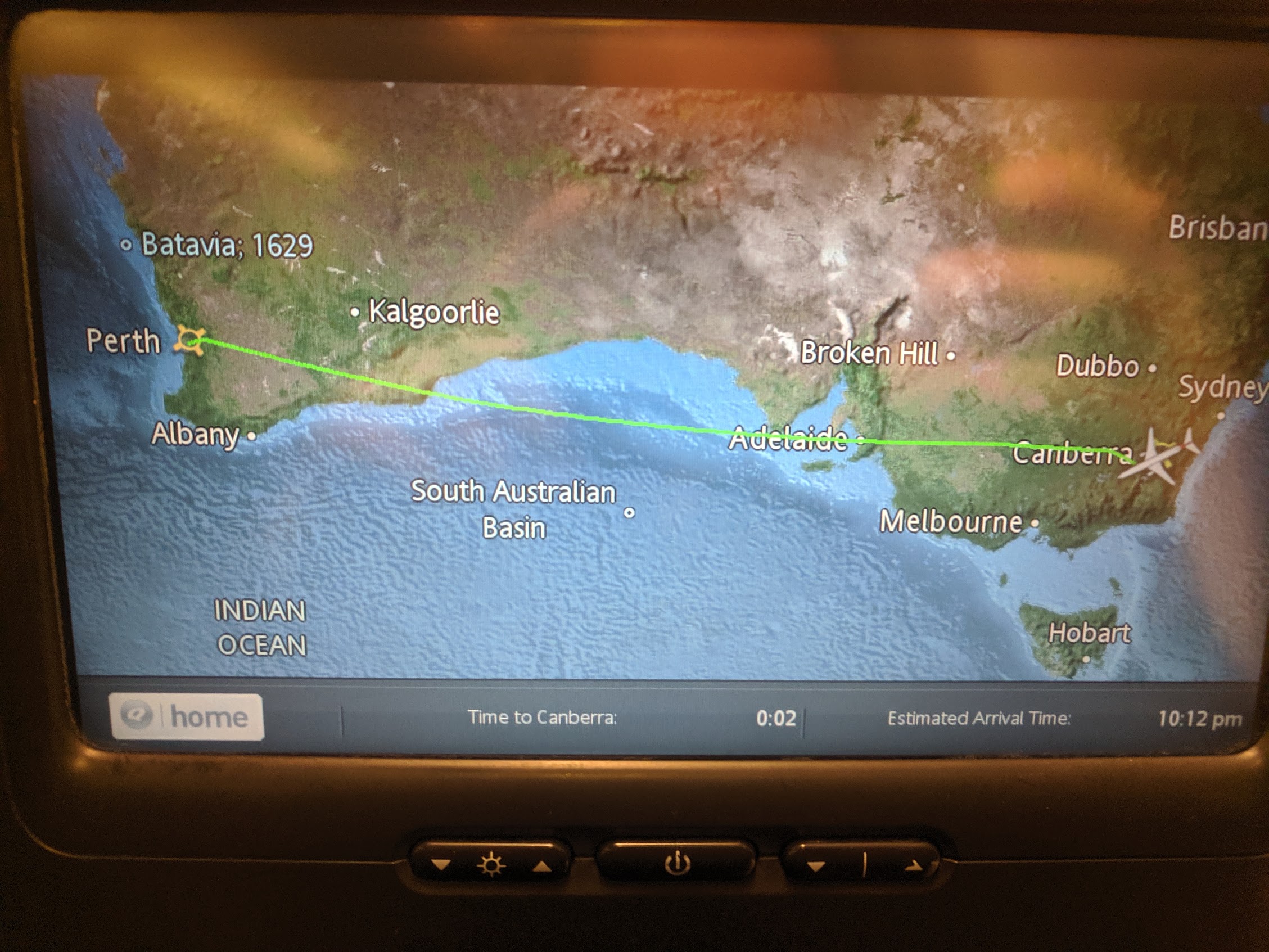
PER to CBR: 4 hours, 3,700 kms (2,300 miles for the old world)
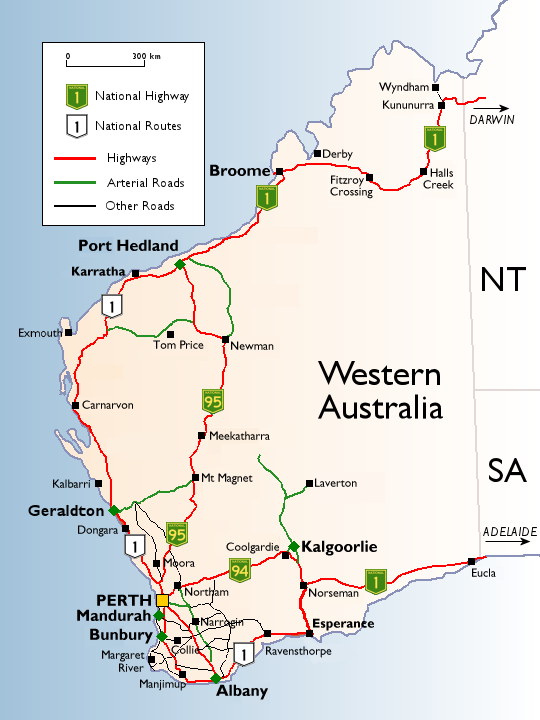
On Monday 19th July, I went to Canberra for the AWS Public Sector summit, held at the National Convention Centre, with some 1,200 people in attendance this time. I recall the first AWS Canberra Public Sector Summit of 2013, with a few hundred going to the Realm Hotel: NCC is now starting to look reasonably full.

It’s always nice running into old friends, and this time, long time Linux.conf.au and Australian Open Source community personality Michael Still. Michael ran LCA 2013 in Canberra, when Sir Tim Berners-Lee was one of the keynotes (and Bunnie Huang, Bdale, and Radia Perlman). I helped the video team that year – and recall chatting with Robert Llewellyn…

Later, I ran into Matt Fitzgerald, whom I first met when I worked for AWS – and was the only other person at that time (circa 2013) from Perth in Seattle with AWS.
Of course, multiple current and former colleagues, other AWS Ambassadors from the region, other folk in the cloud space with other vendors.

And then, in the foyer while chatting, I suddenly find Pia, well known for her work inside the halls of government from Australia to New Zealand, but 17 years ago, helping establish the fledgling Linux.conf.au conference and helping the Australian open source community find its platform and voice.
Of course, its not all about catching up with friends.

The masses packed into the main theatre to hear the set of lighthouse case studies, new capabilities, and opportunities that can be reached on the AWS platform.

This time, the baton of AWS PS Country Manager and MC responsibilities had passed to Iain Rouse, formerly of Technology One. Modis has been an AWS partner since 2013 (as former brand Ajilon), with many Public Sector customers since then, it was nice to see our logo amongst a healthy ecosystem of capability.

Even nicer than seeing our logo, is our customers and those I have worked with. At the first PS Summit in 2013, I asked and had ICRAR attend; I used to work for UWA (as chief webmaster in the last millennium); when I was at AWS I worked with CFS SA and Moodle, and of course, Landgate – which is now over four years of running on the AWS Cloud.
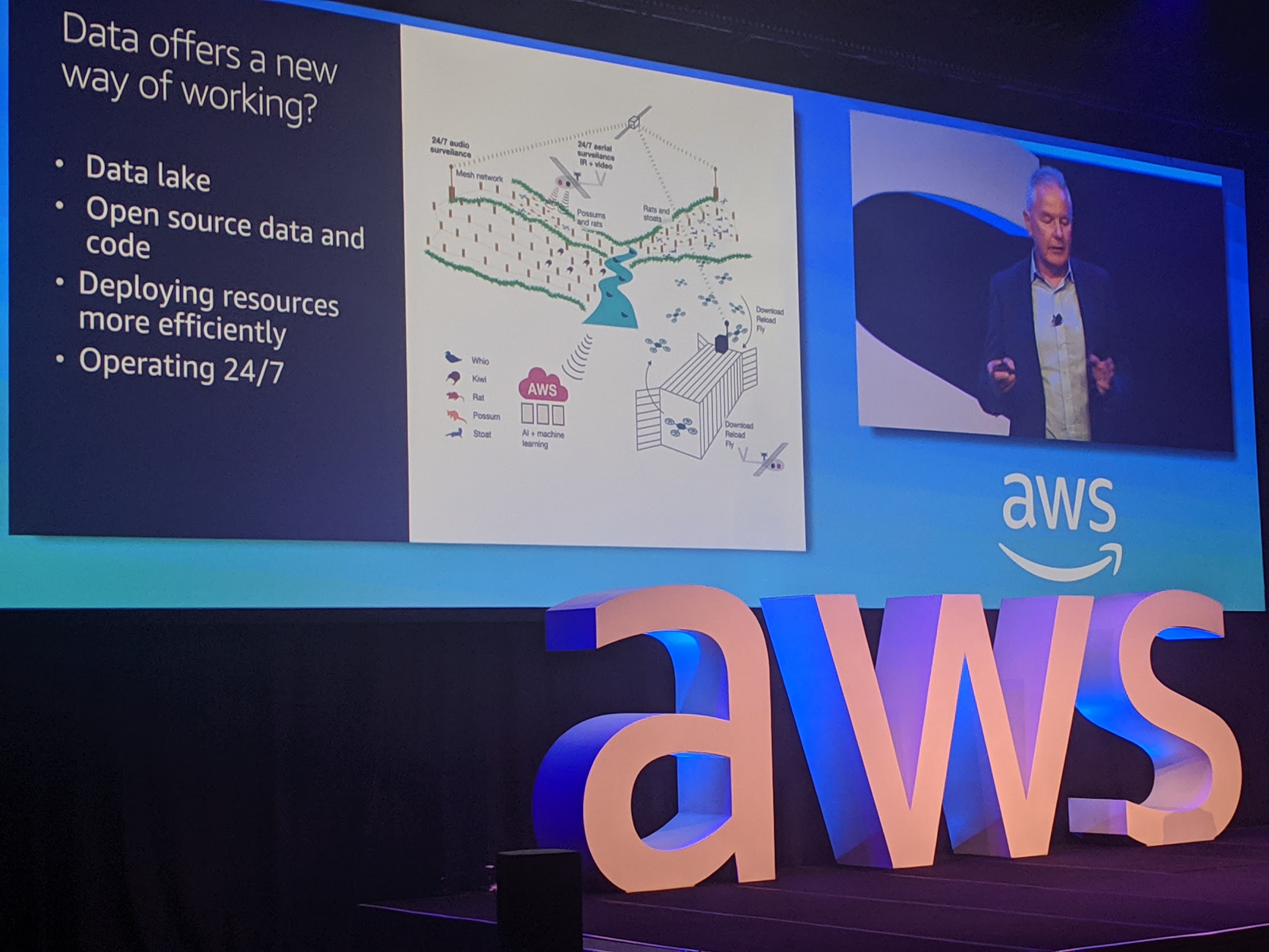
New Zealand’s Conservation’s CIO, Mike Edginton spoke of the digital twinning they have been doing for the environments that their endangered species are in, and of having to set traps for introduced species but IoT enabling them. They cover a vast area of NZ, but the collection of data and analytics and visualisation makes their management more efficient. They’ve also managed to decode Kiwi calls (the bird, not the people).

Former colleague Simon Elisha continued with a strong positioning of the further efforts around the efforts that the AWS engineering teams have been deploying on resilience, multi-layered security, hardware design, physical security, video CCTV archiving; and then into the customer accessible security services for Data Protection, Identity Directory & Access, Detective Controls & Management, and Networking & Infrastructure.

He then dived into a customer controlled capability for S3 (Object Storage) that was surfaced at the global re:Invent service in 2018: Block Public Access. This capability can be leveraged at a per-bucket level, as well as at an AWS-account-wide level (which would be effective for any new S3 Buckets created, regardless of their per-bucket settings)
S3 has been around for many years, and has expanded from a small set of micro services, to over 200 today (as disclosed at AWS Sydney Summit 2019). It can by itself act as a public web server for the content in a bucket; can have public anonymous access.; can encrypt in flight and at rest; storage tiering; life-cycle, logging, and much more. These days, I don’t encouraged teams to serve content to the web directly via S3, but via the CloudFront global CDN (today: 189 points of presence – see this). And with the ability for CloudFront to access S3 buckets using an Origin Access identity, its possible to remove all anonymous access from S3, and enable the Block Public Access – something we have done for many of our customers. This pattern forces that access to the data from the Internet will come from an endpoint set to my desired TLS policy, with a custom named TLS Certificate, and with a bonus, I can set (inject) my specific security headers on the content being served. For example, check out securityheaders.com (hi Scott) and test www.advara.com.
Simon also spoke about the technology stack (not quite the full OSI stack, for those that recall):
- Physical Layer: secure facilities with optical encryption using AES 256
- Data Link Layer: MACsec IEE 802.1AE
- Network Layer: VPN, Peering
- Transport Layer: s2n, NLB-TLS, ALB, CloudFront and ACM
- Application Layer: Crypto SDK, Server Side Encryption
After a quick tour of Security Hub, and then Ian speaking about some of the training and reskilling initiatives, it was time for another customer.

This was the second time I had seen this, with the drone having been shown at the AWS Commercial Summit in Sydney in July. However, Dr Scully-Power’s presentation was, to be honest, very powerful. Watch the video and hear for yourself about rescuing kids from rips, spotting sharks, crocs and more.


The AWS DeepRacer (reinforcement learning autonomous vehicles) was set up and competing again, part of the effort to lower the barrier of entry for customer into machine learning. The exhibitor hall continued to have technology and consulting partners showcasing their achievements and capabilities, as well as the various AWS customer-facing teams such as the certification teams, concierge team, Solution Architects (now split further by services and specialisations).
In the break-out sessions (actually held on the Tuesday), was a track dedicated to Healthcare, a track for High Performance Compute, and more. Presentations for the fledgling Australian space community (see Ground Station), decoupling workloads, connectivity, etc.
Once again a group of local school children were given the opportunity to attend and see the innovation being discussed, and a stream of activities aimed at helping show them career pathways.
Of course, in specific break out streams were media analyst briefings, executive briefings, Public Sector partner forums and workshops.

I also had the opportunity to stop by the Modis Canberra office, and with Mark Smith (with whom I have worked for nearly half a decade) and I spoke at length to the local team on the challenges and successes of our engagements with customers, delivering advanced, managed Cloud services and solutions.
That night, I returned to Perth for a day at work and a few hours with my family… before heading for the next adventure, the AWS Ambassador Global meetup in Seattle (next post).