Its late in 2024, and its time to recap the transitions in the technology space for Internet and web security. I’ve been reading the Internet Society’s pulse pages, and it gets me thinking…
HTTPS: generally this is well deployed with 97% of top 1000 web sites. But conversely, some 30 web sites don’t think the integrity (let alone the privacy) of data transfer from/to their web site is worth the effort? Here’s looking at you, Australia BOM, still force redirecting clients to unencrypted HTTP, particularly in light of your security incidents and increased funding for cyber security over the last decade.
TLS 1.3: Introduced in 2018, it only started taking off in 2019, and now sites as being available on 80% of the top 1000 sites. That’s some 200 sites that haven’t had the upgrade from older versions, which is almost exclusively TLS 1.2 (even older versions are gone, luckily).
HTTP/3: Based on a UDP transport instead of TCP, its seen a massive DROP in usage in the top 1000 with sites switching back to HTTP/2.
IPv6: Now sitting around 45%. For me, this is a trivial item to enable on Cloud; but some Internet Access Providers (ISPs, Telcos) are sweating their existing installations instead of moving their engineering forward (hello Optus: is IPv6 still not Yes!).
For me, these four technologies are a baseline implementation that do not add significant additional cost for operations, but provide speed, security, and connectivity enhancements.
I always recommend tools like SSLLabs.com, SecurityHeaders.com, Hardenize.com, and SSL.sh to test your services and help improve your delivery. If your web service misses these items, then you may need to consider upskilling your team or service provider, or switching your telco/carrier.
30 years ago, in 1994, I started studying at The University of Western Australia (UWA). At the start of the semester, an Orientation Day (O-Day) is held, where the various student clubs would try and recruit members.
Starting as a Computer Science student, I gravitated towards the University Computer Club stand, and signed up to become a member for a few dollars. Founded in 1974, it pre-dates and outlasts the famed Homebrew Computer Club (1975 – 1986), and even pre-dates the UWA Department of Computer Science.
This year the club turns 50, and a dinner was held.
Dr Andrew Williams on stage at the UCC 50th, University Club, UWA
Around 90 past and present members met for dinner at The UWA University Club function centre to reminisce, celebrate, and look forward to the future.
One key element to the ongoing success of a student club is having a space to congregate and to store equipment. Without a physical space that can be the club, it becomes very ephemeral, and often organisations disappear. The UWA Student Gild has supported the UCC with space for most of the 50 year history, and since the early 1990s, this has been a large space in the loft of Cameron Hall.
The UCC as seen from above, with Michael Deegan, James Bromberger and Shay Telfer, on the night of the UCC 50th anniversary dinnerThe UCC at UWA, on the night of the 50th anniversary, 21 Sept 2024.
In the above, you can see a green roof space on the left hand side: this is the UCC Machine Room. A few of us built this space around 1996 in order to house some of the servers that we had acquired, and to duct the air-conditioning (hanging from a window) to keep them cool. Nearly 30 years later, this structure is still standing, make from wood purchased from Bunnings, and a pair of frosted glass doors acquired from a recycling center in Bayswater.
On the shelves you can see manuals – lots of them, for things like BeOS, NextStep, various programming languages, Sun hardware, IBM hardware, On the shelfs is various hardware, cables, connectors and adaptors. On the tables are terminals, 3d printers, soldering irons, disk packs, tape reels, half built robot brains — spanning decades of technology changes. Posters from events past and present adorn surfaces, encouraging participation in activities, experimentation in software and hardware, and more.
One thing clear from the pictures shown is the impact technology ha had on our society. In 1994 I had a digital camera, a Kodak DC40. I took, stored and retained many photos, straight to digital, when most people were still using film (and taking that film to their local pharmacist/chemist to process/print???!). Today, everyone uses digital photography, mostly form their phones. Its normalised, ubiquitous, and the incremental cost for an image is practically zero (just the storage costs of the data produced). The quality is good today compared with 30 years ago.
Dr Williams (above) was one of the first in the world to put a CCD camera on the end of a telescope at the WA Observatory to record images, leading to many observations that would have historically been missed (not to mention, the flexibility to be one of the first astronomers to be working from home on cold nights).
Along one wall is a framed colour picture, taken by a West Australian newspaper photographer around 1997 or so. It shows a series of old IBM 360 cabinets – parts of a large mainframe computer, that was being disposed of from the UWA storage facility in the suburb of Shenton Park. Many old computers had names; this one was called Ben. It had been donated to the UCC well before my arrival, but now the time had come that this storage facility was being repurposed, and Ben had to go. Luckily it was being donated to a museum collector, and over the years I believe it made its way to the Living Computer Museum in Seattle.
But sitting on the wall of the UCC for the last 30 years has been my picture. Watching thousands of UCCans arrive fresh faced, and seen them learn, connect and evolve into some of the individuals who have powered organisations like Apple, Google, Amazon, Shell, BHP, Rio Tinto, The Square Kilometer Array, and many more.
I served as UCC President in 1996, and I helped organise the UCC’s 18th anniversary, 21st, and 25th. Now at 50, its clear that having the physical space to meet – and eat pizza, discuss news, share tips and skills – has been a key part of the longevity of the UCC.
A news story broke in the last week about an image shown of a politician in Australia, shown in a still as part of a journalist introducing a story. The story here is irrelevant, it is the image used to start this:
Now it turns out the image of Ms Purcell (the politician in the photo above and below) was extended using Adobe Photoshop and “Generative Fill”, using a smaller image than what was on the right above:
They look at it as ethics. And Ms Purcell called out sexism in social media. All of which may or may not be true. Adobe has naturally defended their tool, which seems reasonable to me.
Indeed, the appeal of Generative AI tooling is clear from Adobe’s own advertising:
The fact remains that the generative fill tool (and perhaps the digital artist using the tool) and the editor felt that this did not change the story but did fill the purpose of the lead into their piece.
However, I want to raise the question of what impact the change made to the viewer, who saw this image, and perhaps jumped to some conclusions based upon what they saw. Pretty quickly you’re coming to the realisation that the images you see from a news media organisation is no 100% factual. It is longer news, but entertainment. This small edit, may alter the viewers perception and pre-disposition to a topic.
People have historically trusted news organisations to show us facts, and inform us. We have inherently taken Social media as being somewhat less trusted. We hear about journalistic integrity. And while this is minor, its that it has been detected, highlighted, and confirmed that is slightly alarming.
DeepFake voice and video has been around for some time now, and we always want to ensure that data we reply upon come from credible sources. Perhaps the use of Generative AI in news media, newspapers, should be frowned upon or forbidden.
Media (entertainment) organisations that wish to sway the political discourse may of course be doing much more of this. Those are the media outlets with a less than stellar reputation, where the astute consumer will understand that what’s presented may be a version of the truth that is enhanced for various purposes.
If it is for satire, then that’s fine (if the platform or source is understood to be satirical).
If it is to undermine society and influence elections and politics, and impact society for personal gain, that’s not what I would like in my society.
Perhaps this is an innocent mistake, with no malice or forethought about how such content fill may change perceptions.
Perhaps some training for journalists (and their supporting image editors), and a statement from these organisation on their use of generated content?
There’s a word in “Gen AI” that I want you to concentrate on: generative.
Next I’d like you to think about areas in your organisation where you can safely generate (and review what’s generated). This is probably not safe in your invoicing, product testing & QA, CRM records, etc. Those systems all use something else: facts. Facts cannot be generated.
The inordinate amount of hype around GenAI, including finance people on the Australian Broadcast Corporation (ABC Australia) talking about the demise of one company because “Gen AI can now do what their product tech was” is well out of proportion.
Have you noticed how the hyper about the Metaverse has dropped off?
And blockchain?
These are all great technologies, but lets face it, in the majority of cases they have very little to do with the core business of what your organisation does – unless you’re in the arts and creative industries.
There are fantastic demos from Adobe where they generate additional image content. There are prose, poems and fiction being generated. All of which is circling around and creating content from existing examples. It may look fresh, but its generated from existing input, but without human intuition, insight, or intelligence.
We see “director of GenAI” as a job title, but I think that will last about as long as “director of blockchain“.
These technologies do have a place – I called out Adobe above, and you may use their software – but remember, the advantage is to Adobe’s product, and probably not yours. You likely don’t work for Adobe (I’m not picking on them, but the data is in: most of the world does not work there). You’re likely to be a few layers down in the value chain. You’ll benefit from it, but I don’t think you’re going to be training your own LLMs. Someone else will, and they’ll charge you for it or figure out a way to recoup the expense by some method.
But remember, its generated. I can use GenAI to give me tonight’s lottery numbers. While plausible, they are unlikely to be correct.
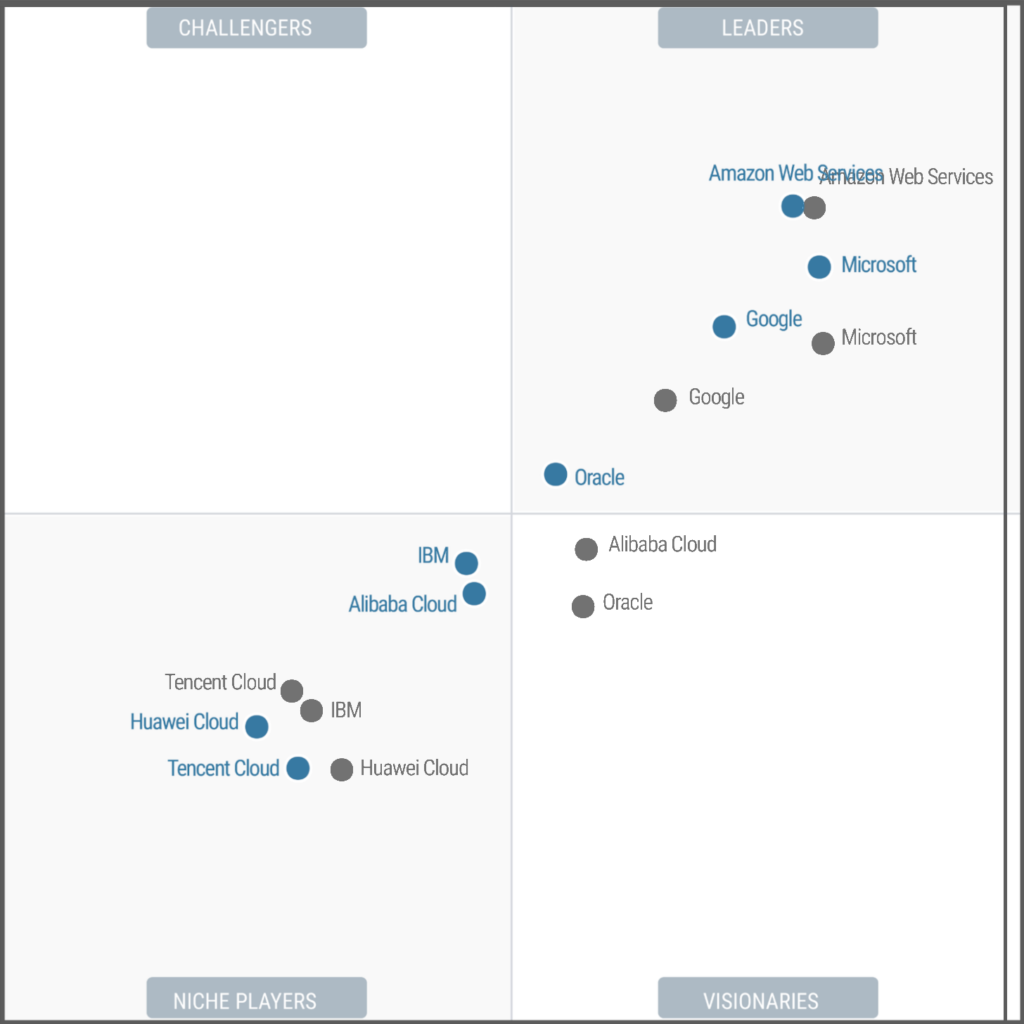
The traditional Gartner tea-leaves view of hyperscalar cloud providers was renamed in 2023, from “Magic Quadrant for Cloud Infrastructure and Platform Services” to “Magic Quadrant for Strategic Cloud Platform Services”. But the players are all the same as in 2022:
In grey are the 2022 results, and in blue is the 2023.
Alibaba slips a whole quadrant, with a large drop in its completeness of vision
Oracle rises a whole quadrant to join the leaders, but only just
Tencent dropped its ability to execute.
IBM picked up substantially, but still a niche player (but they are also the worlds largest AWS Consulting Services Partner when counted by AWS certification numbers (21,207), followed closely by Tata Consulting Services (21,200))
Huawei regressed its completeness of vision, but marginally improved its ability to execute
Google rose to now start approaching AWS and Microsoft.
Microsoft improved its ability to execute
AWS dropped its “completeness of vision” slightly
There’s only really three legitimate global hyperscalar contenders: AWS, Microsoft and Google, in that order. The rest are focused and founded within the great firewall of China, or IBM.