November 2021: Note there is a new way to do this natively within CloudFront, and it wont cost you a Lambda@Edge invocation.
For a long time, I’ve been using Lambda@Edge to inject various HTTP security-related headers to help browsers improve the security model of the content that they fetch and render.
I’ve been doing this as I have been using S3 as the origin (accessed via a CloudFront Origin Access Identity). S3 itself cannot add/inject many of the common security headers when it passes
These Functions execute when the origin returns the content to the CloudFront regional edge; the returned content then gets cached with the injected headers included.
The end result is getting a good rating on securityheaders.com, hardenize.com, and other public security evaluation services.
An alternate in the Lanbda@Edge execution lifecycle is to trigger on Viewer Response; in which case the cached version doesn’t have the headers injected, and every viewer request triggers the code execution. Clearly, if every viewer has the same set of headers, there’s no need to execute each view response and pay for the additional Lambda@Edge executions.
Now there’s a new option – CloudFront Functions (AWS blog post). Written entirely in JavaScript, it executes only at Viewer Request, or Viewer Response. There is no Origin Request or Origin Response option. It also executes at the CloudFront Edge, not the Regional Edge.
Thie example injects a number of headers, and would need only minor potential customisation on the Content Security Policy (and possibly Permissions Policy) to work for most sites:
You may want to evaluate the cost of both Lambda@Edge and CloudFront Functions. After the first year, Functions is charged at US$0.10 per million functions. As an equivalent, Lambda@Edge for a similar Node.JS function that executes in one millisecond with 128 MB of memory would be US$0.2021 per million requests.
However, given a busy website, you may want to look at the efficiency differences between Viewer Response execution for CloudFront Functions, and Origin Response and the caching for Lambda@Edge (multiplied by the number of Edge Cache locations (13), and the cache retention rate).
If you have only a few unique URLs, and content that can be cached for a long period, and large volumes of requests, then Lambda@Edge may result in near free execution.
Lambda@Edge
CloudFront Functions
Unique URLs
100
100
HTTP viewer Requests
10M/month
10M/month
Execution time
1ms
N/A
Number of Regional Edges
13
N/A
Memory/execution
128MB
N/A
Execution time
Origin Response
Viewer Response
Number of code invocations
1300 (once per Regional Edge, Per Unique URL, and possibly cached for a month – depending on Edge cache expiry)
CloudFront Functions cost uplift compared to Lambda@Edge
3,806 times more expensive
If we were using Lambda@Edge on ViewerResponse, and not caching the object with headers injected, then CloudFront Functions would be cheaper; or if the content being sent was dynamic from the origin and not suitable to be cached, in which case we wouldn’t get the efficiency savings of fewer executions.
Even if we are using Origin Response with Lambda@Edge, we can’t determine the cache expiry of the Lambda@Edge cached responses (we can influence it); the cached objects could expire and re-execute every day, so the Lambda@Edge costs could go up 30x (which would only make CloudFront functions 126 times more expensive). YMMV. TIMTOWTDI.
As Hanno Böck noted in the recent Bulletproof TLS Newsletter, FTP Support in Firefox 90 has been removed. We’ve seen similar messaging from most major browser vendors over the last few years.
I’m going to make a bold prediction, and say in 10 years time we’ll be seeing the removal of (plain text) HTTP support as well. Regardless of internal or external networks (an out-dated concept aligned to the Crunch Shell of network security), the move to stronger security for all communications, backed by free TLS Certificate Authorities (such as Let’s Encrypt) means we should be doing end-to-end encryption for everything the common web browser fetches.
For some time, Firefox has had an HTTPS-only mode, with warnings when services try and dip back to unencrypted access. I’ve typically found this warning pops up when various link-shortening services are chained together, and I’m grateful for the awareness that a jump in that chain is poorly implemented.
In the meantime, the distribution of files using FTP needs to stop. If you run an FTP service then you need to think about transitioning to something that permits access using HTTPS as the transport protocol.
Another sunset in the circle of life of a protocol.
I recently posted about using AWS to provide very cost-effective, Scalable, Secure Static websites. In this post, here’s a valid reason you should do this now, to publish a new website on your domain that has one, simple file on it.
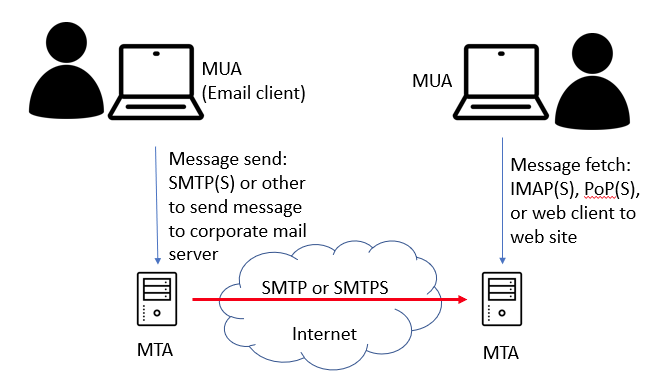
Email on the Internet has used SMTP for transferring email between mail transport agents (MTAs) since 1982, on TCP port 25. The initial implementation offered only unencrypted transport of plain text messages.
It’s worth noting that people, as clients to the system, generally will send their email to their corporate mail server, not directly from their workstation to the recipient; the software on your desktop or phone is a Mail User Agent (MUA), and your MUA (client) transfers your outbound message to your MTA (mail server), which then sends the message using SMTP to your recipients MTA, and then when the user is read they sign in and read their mail with their MUA.
The focus of this article is that middle hop above – MTA to MTA, across the untrusted Internet.
SMTPS added encryption in 1997, wrapping SMTP in a TLS layer, similar to how HTTPS is HTTP in a TLS wrapper, with certificates as many are familiar with, issued by Certificate Authorities. This commonly uses TCP port 465. And while modern MTAs support both encrypted and unencrypted protocols, it’s the order and fail-over that’s important to note.
Modern Mail Servers will generally try and do an encrypted mail transfer to the target MTA, but they will seamlessly fall back to the original unencrypted SMTP if that is not available. This step is invisible to the actual person who sent the message – they’ve wandered off with their MUA, leaving the mail server the job to forward the message.
Sending an email, from left user, to right, via two MTA servers.
Now imagine an unscrupulous network provider somewhere in the path between the two mail servers, who just drop the port 465 traffic; the end result is the email server will assume that the destination does not support encrypted transfer, and will then fall back to plain text SMTP. Tat same attacker then reads your email. Easy!
If only there was a way the recipient could express a preference to not have email fall back to unencrypted SMTP for its inbound messages.
Indeed, there’s a similar situation with web sites; if how to we express that a web site should only be HTTPS and not down graded to HTTP. The answer here is the Hypertext Strict Transport Security header, which tells web browsers not to go back to unencrypted web traffic.
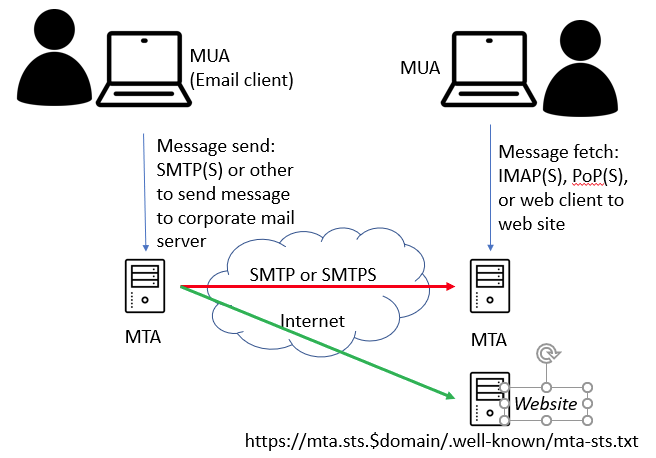
Well, mail systems have a similar concept, called the Mail Transport Application Strict Transport Security, or MTA-STS defined in RFC8461.
MTA-STS has a policy document, which allows the preference for how remote clients should handle connections to the mail server. It’s a simple text file, published to a well-known location on a domain. Remote mail servers may retrieve this file, and cache it for extended periods (such as a year).
In addition, there is a DNS text record (TXT), named _mta-sts.$yourdomain. The value of this for me is “v=STSv1; id=2019042901“, where the ID is effectively used as a timestamp of when the policy document was set. I can update the policy text file on the MTA-STS website, and then update the DNS id, and it should refresh on clients who talk to my mail server.
The well-known location is on a specific hostname in your domain – a new website if you will – that only has this one file being served. The site is mta-sts.$yourdomain, and the path and filename are “.well-known/mta-sts.txt‘. The document must be served from an HTTPS site, with a valid HTTPS certificate.
So an excellent place to host this MTA-STS static website, with a valid TLS certificate, that is extremely cost-effective (and possibly even cost you nothing) is the AWS Serverless approach previously posted.
You can also check for this with Hardenize.com: if you get a grey box next to MTA-STS for your domain, then you don’t have it set up.
Of course, not all MTAs out there may support MTA-STS, but for those that do, they can stop sending plain text email. Even still, don’t send sensitive information via email, like passwords or credit card information.
The MTA trying to send the message may cache the STS policy for a while (seconds as indicated in the file), so as long as TCP 443 is available at some time, and has a valid certificate (from a trusted public certificate authority), then that policy can persist even if the HTTPS MTA-STS site is unavailable later (eg, changed network).
Its worth noting that your actual email server can stay exactly where it is – on site, mass hosted elsewhere; we’re just talking about the MTA STS website and policy document being on a very simple, static web site in Amazon S3 and CloudFront.
Hosting web content has a mainstay of AWS for many years. From running your own Virtual Machine, with your favourite web software, to load balancing web traffic, DNS from Route53 and CDN from CloudFront, it’s been one of the world’s preferred ways to publish content for over a decade.
But these days, it’s the Serverless suite of services that help make this much cheaper, faster, more scalable, and repeatable. In this article, we’ll show how we can host a vast number of websites. We’ll also set a series of security features to try to get as secure and available as possible, even though we’ll be allowing anonymous access.
In a future post, we’ll dive through setting up a complete CI/CD pipeline for the content of your websites, with Production and non-production URLs for workflow review and acceptance.
High Level Features
No application servers to manage/patch/scale
Highly scalable
Globally available (cached)
IPv4 and IPv6 (dual-stack)
HTTP/2 (request multiplexing, and compressed request headers)
Brotli compression, alongside gzip/deflate
TLS 1.2 minimum; strong rating on SSLLabs.com
Modern security headers: strong rating on securityheaders.com
Basic Architecture
The basic architecture of the content is:
An S3 bucket to host our S3 Access Logs (from the below content bucket) and the CloudFront Access Logs we will be making
An S3 Bucket to host the file (object) content
A CloudFront distribution, with an Origin Access Identity to securely fetch content from S3.
A TLS certificate, issued from Amazon Certificate Manager with DNS validation
DNS in Route53 (not strictly necessary, but it makes things easier if we have control of our own domain immediately, and we can handle CloudFront at the APEX of a DNS domain (ie, foo.com) with ALIAS records)
While there is a lot to configure here there are no Servers to administer, per sé. This means the scaling, OS patching, and all other maintenance activities are managed – so we can get on with the content.
A Canonical URL
It is strongly recommended to have one hostname for your website. While you can have multiple names in a TLS certificate and serve the same content, you’ll get down-weighted in search engines for doing so, and it’s confusing to users.
In particular, you need to decide if the URL your users should get your content from is www.example.com, or just example.com. Choose one, and stick to it; the other should be a redirect if you need to (as a separate, almost empty, website). Indeed, there’s a CloudFront Function or Lambda@edge function you can write to do your redirects.
Don’t be tempted to use an S3 Bucket for your web redirections, as there’s a limit on the number of S3 Buckets you can have, and you can’t customise the TLS certificate or TLS profile (protocols, ciphers) on S3 website endpoints directly.
S3 Logging Bucket
This is the destination of all our logs. The key element is the automated retention (S3 lifecycle) policy – we want logs, but we don’t want them forever! Some keys points:
S3 Versioning enabled
S3 Lifecycle policy, delete current objects after 365 days, and previous revisions after 7 days (just in case we have to undelete).
Default encryption, Amazon S3 master-key (SSE-S3)
Ironically, probably no server access logging for this Bucket; otherwise if we log server access to the same bucket, we end up with an infinite event trigger loop
Permissions: Block Public Access
Object ownership: Bucket Owner preferred
Permit CloudFront to log, using the canonical ID shown here
Permit S3 logging for the Log Delivery permission
S3 Content Bucket
Again we want to Block Public Access. While that may sound counter-intuitive for a public-facing anonymously accessible website, we do not want external visitors poking around in our S3 Bucket directly – they have to go via the CloudFront Distribution.
S3 does have a (legacy, IMHO) website hosting option, but it hasn’t traditionally given you access to have a custom TLS certificate with your own hostname, nor permitted you to restrict various compression and TLS options – that’s what CloudFront lets us customise.
The basic configuration of the Content S3 Bucket is:
S3 Versioning enabled (hey, it’s pretty much a standard pattern)
S3 Lifecycle Policy, to only delete Previous revisions after a period we’d use for undelete (7 days)
Default encryption, Amazon S3 master-key (SSE-S3)
Access logs sent to the above Logging Bucket, with a prefix of /S3/content-bucket-name/. Note to include the trailing slash in the prefix name, otherwise, you’ll have a horrible mess of object names
Permissions: Block Public Access (CloudFront Origin ID will take care of this)
We’ll come back later for the Bucket Policy…
ACM Certificate
The next component we need to start with is a TLS Certificate; we’ll need to be already available when we set up a CloudFront distribution.
ACM is pretty simple: tell it the name (or names) you want on a certificate, and then ensure the validation steps happen.
My preference is DNS validation: once the secret is stored in DNS, then subsequent re-issues of the certificate get automatically approved, and then automatically deployed.
Ideally, your website will have one, and only one, authoritative (canonical) DNS hostname. And for that service, you may want to have just one name in the certificate. It’s up to you if you want the name to be “www.domain.com”, or just “domain.com”. I would avoid having certificates with too many alternate names, as any one of those names having its DNS secret removed will block the re-issuance of your certificate.
Lambda@Edge
There are two major functions we’ll use Lambda@Edge: one to transform some incoming requests, and one to inject some additional HTTP headers into the response.
All Lambda@Edge functions need to be created in us-east-1; and the CloudFront service needs access to invoke them.
Handling the default document in sub-prefixes
CloudFront as a CDN has the concept of a default object, a file name that can be fetched when no filename is supplied. Historically (as in, before IIS existed), this was index.html (if you’re wondering index.htm came about, then you probably don’t recall Microsoft DOS and Windows with its 8.3 filename limits). However, the configuration setting only applies to one request URL: the root object, or “/”. It does not cater for “subdirectories” or folders, which is often not what’s needed; in which case, when a path of “/foo/”. is requested, then we want to update the request that will hit the origin (S3) to “/foo/index.html”., and mask the fact we’ve done this.
As of May 2021, CloudFront also has a new code execution service, CloudFront Functions. This would be suitable for this purpose as well.
The second function we will want is to inject additional HTTP headers to help web clients (browsers) to enforce stricter security. There’s a set of headers that do this, some of which need customising to your site and code:
The exact headers that are recommended changeover time, as the state of capability in the commonly deployed (and updated) browsers change.
The most important header is the HSTS, or Hypertext Strict Transport Security, which informs clients that your service on this hostname should always (for the time period specified) be considered HTTPS only.
Next on my list of security headers is the Permissions Policy, formerly the Feature Policy. This administratively disables some capability that browsers can surface to web applications, such as the ability to fetch fine-grained location or use a device’s camera. Typically we don’t want any of this, and we probably wouldn’t want any introduced JavaScript (possibly coming from a 3rd party site) to try this.
The most specific header, which truly needs customising to your site’s content and structure, is the Content Security Policy, or CSP. This permits you to express in great detail the permitted sources for content to be loaded from, as well as where your content can be embedded into (as iframe content in another page), or what it can embed (as iframe content within your page).
As of May 2021, CloudFront also has a new code execution service, CloudFront Functions. However, this would have to be executed every time an object is served to a client, as at this time, CloudFront Functions can not hook into the request life cycle at the Origin Response phase. The difference is important: these static headers can be executed once and attached to a cached object, and then served an infinite number of times.
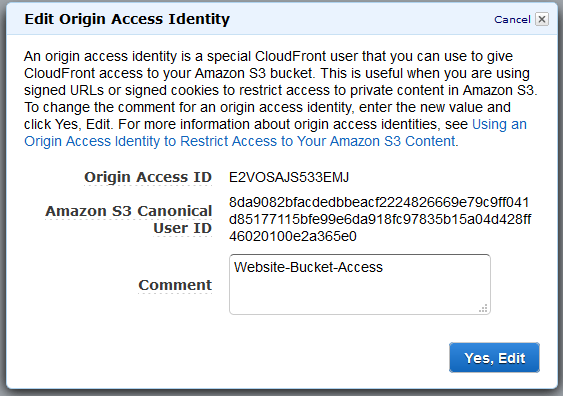
An Origin Access Identity is a way to permit CloudFront edge locations to make authenticated calls against an S3 Bucket, using credentials that are fully managed, dynamic, and secure.
An Origin Access Identity has one attribute, a “comment”., which we’ll call “Website-Bucket-Access”. In response, we’ll get an ID, as shown here:
We can now go back to the S3 console, and update our Content Bucket with a Policy that permits this ID to be able to Get objects (it only needs Get, not List, Put or anything else).
Each web site requires its own CloudFront distribution, with a unique origin path within our S3 Content Bucket that it will fetch its content from. It will also have a unique Hostname, and a TLS certificate.
In order to facilitate some testing, we’re going to define two Distributions per web site we want: one for Production, and one for Testing. That way we can push content to the first S3 Bucket, ensure that it is correct, and then duplicate this to the second (production) location.
To make this easier, we’re going to use the following prefixes in our Content S3 Bucket:
/testing/${sitename}
/production/${sitename}
For the two distributions, we’ll create one of test.sitename, and the production one with just the target sitename we’re after.
In this case, we’re using the same AWS account for both the non-production and production URLs; we could also split this into separate AWS accounts (and thus duplicate a separate S3 bucket to hold content, etc). We can also add additional phases: development, testing, UAT, production. One deciding factor is how big a team is working on this: if it is just one individual, two levels (testing, production) is probably enough; if a separate team will review and approve, then you probably need an additional development environment to keep working while a test team reviews the last push.
Here’s the high level configuration of the CloudFront distribution configuration:
Enable all locations – we want this to be fast everywhere.
Enable HTTP/2 – this compresses the headers in the request, and permits multiplexing of multiple requests over the one TCP connection
Enable IPv6 as well as IPv4 – significant traffic silently falls back to IPv4, and the deployment is easy, fast, and doesn’t cost anything. Note that you need to create both an A record in DNS, and an AAAA record (ALIAS in Route53) for this; just ticking the IPv6 option here (or in the template) does not make this work by itself.
For the default behaviour, set up an View Request handler for the default document rewrite lambda in US East, and the Security Header injection on Origin Response.
Set logging to the S3 log bucket, in a prefix of “CloudFront/${environment}/${sitename}
Enable compression
Redirect all requests to HTTPS; one day in a few years time this wont be necessary, but for now….
Only permit GET and HEAD operations
Set the Alternate Domain name to the one in your ACM certificate, and assign the ACM certificate to this distribution
Template the steps
In order to make this as efficient as possible, and support maintenance in a scalable way, we’re going to template these. Lets start with these template ideas:
Shared Templates (only one instantiation)
CloudFront Origin Identity – used by all CloudFront distributions to securely access the S3 Bucket holding the content
Lambda@Edge Default Document Function, to map prefixes to a default document under each prefix.
Lambda CloudFront Invalidate (flush) function (so we can test updates quickly) – very useful with CI/CD pipelines!
Logging S3 Bucket
Content S3 Bucket
Templates per distribution (per web site)
Lambda@Edge Security Headers; with unique values per site, to fit security like a glove around the content
ACM certificate
CloudFront distribution (depends on the above two)
Download templates
These may need some customisation, but are a reasonable start:
Now you have a way to deploy a number of web sites, it’s worth looking at the costs, and administration overhead.
Bandwidth is always a cost no matter what the rate is, so optimising your service to reduce the size of downloads is key; not only will cost decrease, but its also going to make your service ever so slightly faster.
Serving images in current-generation formats, such as webp (instead of jpeg) may give an improvement; but you need to be confident that only modern clients are using your service. Of course, if you’re restricting TLS protocols for security requirements, then you probably already have mostly modern clients!
Even if you can’t use contemporary image formats, you can ensure that images are used in the browser at the resolution they are; we’ve seen people take the image they took with their phone at 2 MB and thousands of pixels wide and high, only to implement width and height of 50 pixels! If nothing else, ensure you’re compression of JPEGs is reasonably (you probably have a default of 90%, when 60% may do).
In a subsequent post, we’ll look at having Production, UAT and Development copies of our sites, as well as using CodeCommit to store the content, and CodePipeline to check it out into the various environments.
The Australian Signals Directorate, part of the Australian Department of Defence, has been issuing guidance to organisations to help secure their digital systems for several years. Known as the Essential Eight, it defines eight activities that help mitigate exposure to compromise or exploit.
Some of the most basic items are around patching the tech stack:
operating systems
programming runtime environments like Java, .Net, Python and more
software solutions that run on those run-times
Of course Multi-Factor Authentication (MFA) is a key one; and slowly our service providers are coming around to offering MFA pas part of their login services – or better yet, federation of identity to other online services hat already do this, such as Facebook, Google, etc.
But how much of this applies to your technology stack in the Serverless world of AWS? Let us begin, following the AWS guide
1. Application Control
ASD recommends organisations “prevent execution of unapproved/malicious programs including .exe, DLL, scripts (e.g. Windows Script Host, PowerShell and HTA) and installers“.
In the world of AWS Lambda, the only code that is present is our bespoke code and any libraries (layers) we’ve possibly added in. What we want to do is ensure that the code we upload is the code executing, and Lambda now allows signed code bundles (Configuring, Best Practices).
If we’re running a Serverless static web site (using S3, CloudFront, etc), then we have no executing code; only content (note you may have some Lambda@Edge or CloudFront functions to inject various Security related HTTP headers, such as HSTS, CSP, and more: see Scott Helme’s excellent securityheaders.com).
However, there are no other applications as… there is no application server per sé.
2. Patch Applications
Well, in AWS Lambda, this is where we have to update out own applications (and those layers/libraries) to ensure they are up to date. If you have abstracted those libraries and imports into Layers, then manage them and update.
Again, in a static web site deployed Serverlessly, we have no application serves to patch (again, except for any Lambda@Edge or CloudFront functions that need maintenance).
3. Configure Microsoft Office Macro Settings
Er, well, no Microsoft Office installed in Serverless, so this is a no-op. Nothing to do here, move along…
4. User Application Hardening
ASD says “Configure web browsers to block Flash (ideally uninstall it), ads and Java on the internet. Disable unneeded features in Microsoft Office (e.g. OLE), web browsers and PDF viewers.“.
We have none of this in our Serverless environments. However we should be delivering updated applications with everything we can do to support the most modern and up to date browsers; the rest of the world is auto-updating these browsers very rapidly.
For corporate environments that lock down browser updates; question why the rest of the world has better security than your corporate users you’re trying to protect!
5. Restrict Admin Privileges
Using AWS IAM, restrict who can deploy, particularly to production environments. Using CI/CD pipelines and approvals, developers should be able to write and update code and then have it deploy immediately to non-production environments, but it should require a second sign off from a separate individual (or team or people) before it gets near production. Indeed, consider that commits to a revision control repository of code being the source of truth, and that repository needs review before changes are staged ready for a CI/CD pipeline to do its delivery job.
6. Patch Operating Systems
No servers, no Operating systems. OK, Lambda will apply minor version updates to run-times to address security requirements, but its also worth updating major versions of run-times as well. Newer runtime versions have a great chance of supporting newer TLS protocols, ciphers, key exchange methods and checksums.
7. Multi-Factor Authentication
There should never be an interactive user with access that doesn’t use MFA. Not only should your access to AWS be MFA based, it should probably be federated via AWS SSO, using MFA back on your identity provider (IdP).
However, your users of your Serverless solutions may also want the option of using federated identity (SAML, etc), and with MFA implemented on their IdP as well (if you have authenticated access). Or perhaps mutual certificate authentication. If you have an open system with no authentication (publicly, anonymously available) then perhaps that’s fine too. Most web sites are, after all, publicly, anonymously available for their home page and other public content; but the ability to change that content is heavily protected.
8. Backups.
You should have Backups. You should know where your data is. If you’re using DynamoDB, then at least turn on Point In Time Recovery, and a backup schedule. Consider dumping those backups to a separate account in escrow: check out the S3 options around versioning, and retention (Life Cycle) of older versions. Consider the concept from the point of an AWS account being compromised; can an attacker than delete the backups across-account to another environment.
For your code base – is it in a revision control repository – separate to the operational runtime environment. What happens if bad code is put into your repository, and pushed through your environments – can you go back. Do you consider the code repository as a Production service, accessible for commits from developers, but managed as a Production service for them.
Summary
In summary, much – but not all – of the ASD Essential Eight evaporates from being the operator/developers responsibility, leaving you more time to concentrate on the effective implementation of the rest of those items that do remain.
This is all excellent advise, and the more that it is clearly demonstrated with easy adoption for organisations, the better we are across all sizes and types of organisations.
Going further, I am keen on is to remove the use of any unencrypted protocols, particularly HTTP. With free, globally trusted TLS certificates available, moving to HTTPS should be straight forward.
However, that’s not the end of the journey, as TLS has versions. Older versions – less than TLS 1.2 as of this time of writing – should not be used – and most browsers and crypto libraries have removed these from their technology stack to prevent them being used.
Your application – even in a Serverless environment – should verify when it establishes an outbound HTTPS connection that the details of that connection meet your minimum TLS requirements – and you should be ready to up your requirements in future. As mentioned above, sometimes that requires a newer runtime, but newer run-times often still support older TLS protocols – even if you don’t want to (or shouldn’t).
I have been recommending to organisations for some time is to start blocking corporate users from using unencrypted HTTP from their workstations. Firefox has a setting to soft-disable unencrypted HTTP as well (a warning is presented to the user). This may seem inconvenient, but its a huge step up in the security for your workers, which is a key vector into your systems.
Furthermore, stop providing convenience redirects on your services from unencrypted HTTP on port 80 to HTTPS on port 443 – for anything other than your organisations home page. Any other redirection via an unencrypted port should be a hard fail, and fixed at the source.