Last week I was fortunate enough to attend the AWS Sydney Summit 2023, along with my colleague and friend, Elliot Segler, on behalf of Akkodis.
A Partner Day was arranged that ran on Monday 3rd April – I’ll avoid details on that here at this time to focus on the main Customer Summit – the Big Event.
This was really the first major in-country Summit since the “end” of the Covid-19 pandemic – the 2022 version was much smaller, and that was only announced as a small in-person event just a few weeks before it was held. Thus in 2022 this event only had a small crowd; this year, attendance tickets were capped at 5,000.
In 2019, some 19,000 people attended over two days.
I’ve been fortunate to never miss an AWS Summit in Australia, and it gives me insight into the state of the Cloud when comparing year-on-year.



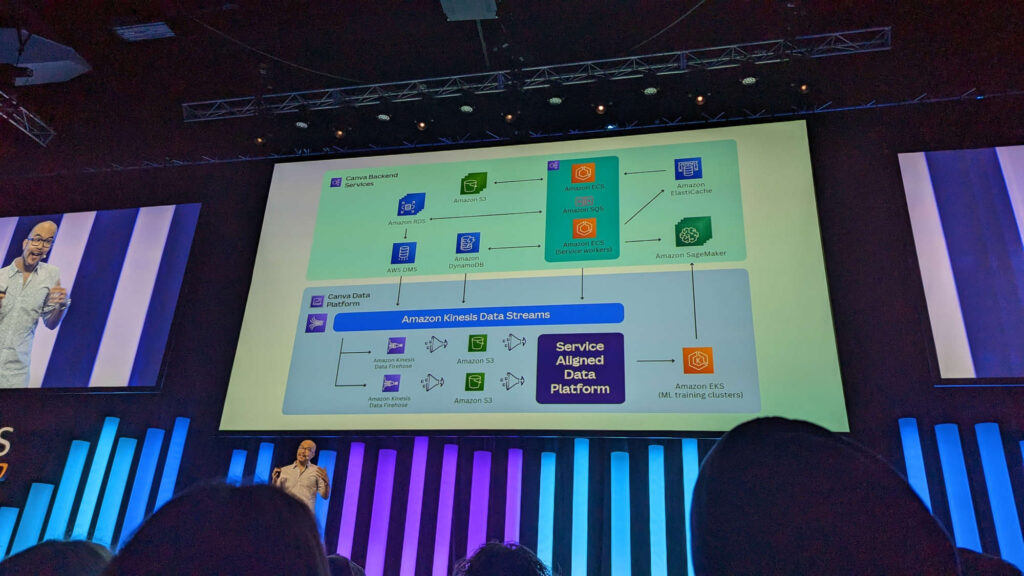
Cameron also spoke about the move to sustainable computing, Canva signing The Climate Pledge, and Canva racing to integrate AI models into their service offering, such as magic erase.
We also saw Nicole Sheffield from Wesfarmers “One Digital” service who spoke about the implementation of their digital platform that offers customer-facing digital services across the Wesfarmers portfolio. This is significant, as Wesfarmers had, in 2014, been quite alarmed at Amazon entering Australia.
The exhibitors were split between Consulting Services partners, and ISV partners. Those ISVs had a distinct developer tooling flavour to them, but we also saw Canva talking to end customers about their product, and both Bespoke and Lumnify (formerly DDLS) training providers discussing their educational schedules and offerings.
Early in the morning I took a photo of the Builder lab, set up for individuals to undertake self-paced digital training – which was full for the rest of the day:

In Financial Services, Australian bank (and one of the Big Four) Westpac provided their take on some of the cloud security approaches. This is notable to me as one of their staff in 2013 said they would “never use Public Cloud”; they seem to be doing well putting Public Cloud to good use.
Suncorp (finance, insurance and banking) also spoke about their exit strategy from their existing data centers using AWs as a target platform.
This year there were no major service announcements or releases at this Summit, but then these days the major announcements happen almost every few days anyway! In previous years, the Summit has always had a sort of “revolution” (when major new concepts or services were released, such as AI services) or “evolution” (incremental updates announced for existing services). This year the theme was more “steady-as-she goes” and stable.
What’s clear is that commentary around Lift & Shift migrations are now evolving to Migrate & Modernise (which is what I have always focused on – deeper expertise and a better short and long term outcome). This isn’t surprising, as often naïve Lift & Shift has left customers with workloads costing more and unable to take advantage of key cloud attributes, such as scalability or cloud-platform-managed-services to reduce TCO.
Of course, those who implemented cloud-native solutions, and paid close attention to Cloud Operating Models (and tech team org structures) with an eye to the Well-Architected Framework have enjoyed optimised and reliable operation.
AWS claimed that perhaps only 15% of all workloads that will eventually run in the cloud, is now doing so. Of course, that 15% requires the maintenance, care and attention to ensure it remains operational, and optimal.
So where are we in the Cloud evolution timeline? I suspect we’re in the middle of furious catch-up by software providers who now are focusing on adopting IaaS and PaaS to take their legacy solutions, and reimplement them as cloud-native SaaS. More vertical-specific SaaS products are coming to market.
The individual services within the cloud are maturing. ARM-based Graviton chips continue to uphold Moore’s Law (RIP Gordon Moore, 2023). IPv6 is progressing, but as noted by one of my fellow Partner Ambassadors and long term friend, Greg Cockburn, the rate of change in modern IPv6 networking appears to be slowing (with notable exception, VPC Network Firewall now supporting IPv6 only subnets). I suspect the major requests are now satisfied; workloads that want to be dual-stacked to the outside world are fully supported. Of course, many ISPs, telcos and carriers are continuing to slowly adopt IPv6 for their consumers; some advanced end user providers in Australia have been Telstra, Internode (ironically part of iiNet who dropped the IPv6 ball in 2013, and thus part of Vodafone), and Aussie Broadband.
From speaking to people, it did appear that a 5,000 person cap had limited many people from attending, particualy those who live in the same Australian state of New South Wales who may have left booking a ticket too late, and missed out. Perhaps in 2024 we’ll see another increase (and who knows).
Meanwhile, outside around Darling Harbour, much construction happens, watched over by warships and tall ships.

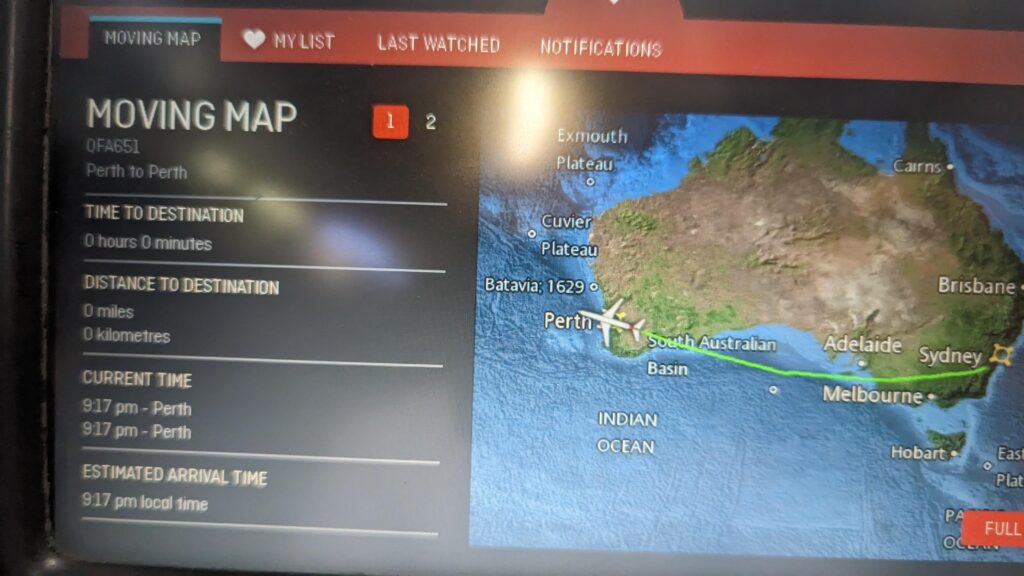
And in case you’re wondering, its a long way from Perth (where I live) to Sydney, and the Great Circle line directly between the two cities takes us far over the Southern Ocean: