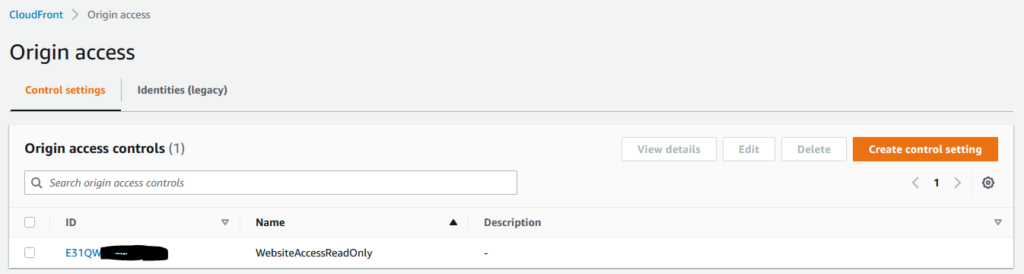
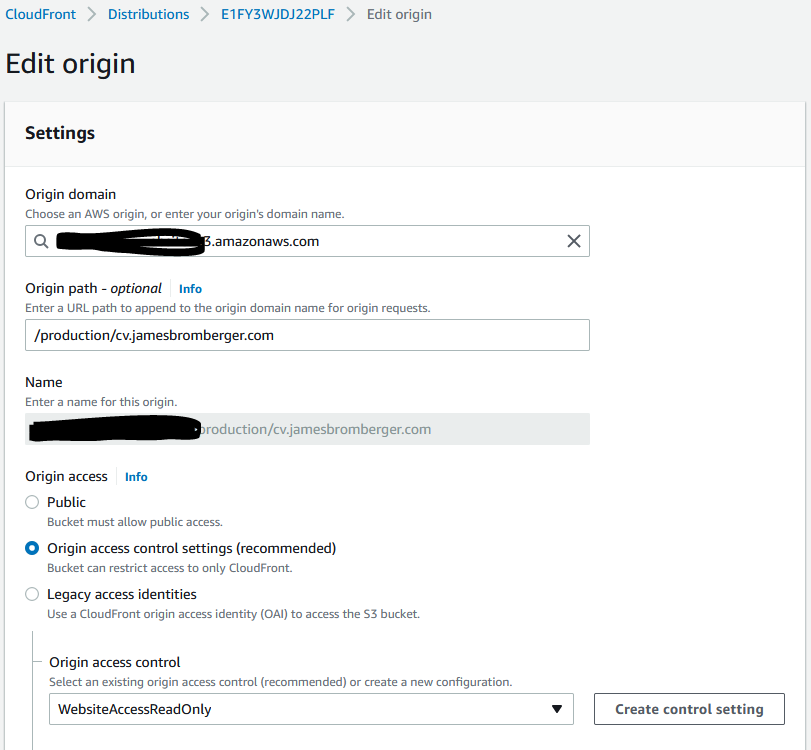
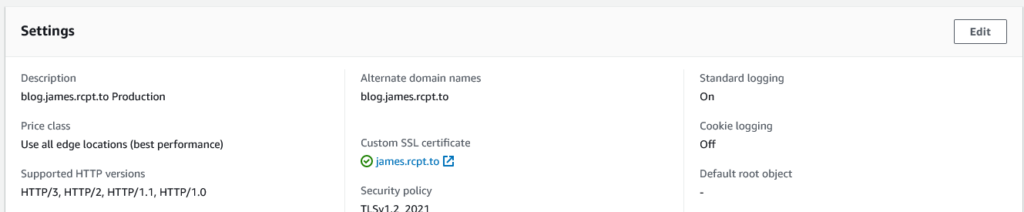
I recently wrote about the change of Amazon CloudFront’s support for accessing content from S3 privately.
It’s bad practice to leave an origin server open to the world; if an attacker can overwhelm your origin server then your CDN cant help to insulate you from that, and the CDN cannot serve any legitimate traffic. There are tricks to this such as having a secret header value injected into origin requests and then have the origin process that, but that’s kind of a static credential. Origin Access Identity was the first approach to move this authentication into the AWS domain, and Origin Access Control is the newer way, supporting the v4 Signature algorithm (at this time).
(If you like web security, read up on the v4 Signature, look at why we don’t use v1/2/3, and think about a time if/when this gets bumped – we’ve already seen v4a)
CloudFormation Support
When Origin Access Control launched last month, it was announced with CloudFormation support! Unfortunately, that CloudFormation support was “in documentation only” by the time I saw & tried it, and thus didn’t actually work for a while (the resource type was not recognised). CloudFormation OAC documentation was rolled back, and has now been published again, along with the actual implementation in the CloudFormation service.
It’s interesting to note that the original documentation for AWS::CloudFront::OriginAccessControl had some changes between the two releases: DisplayName became Name, for example.
Why use CloudFormation for these changes?
CloudFormation is an Infrastructure as Code (IaC) way of deploying resources on the cloud. It’s not the only IaC approach, another being Terraform, or the AWS CDK. All of these approaches gives the operator an artefact (document/code) that itself can be checked in to revision control, giving us the ability to easily track differences over time and compare the current deployment to what is in revision control.
Using IaC also gives us the ability to deploy to multiple environments (Dev, Test, … Prod) with repeatability, consistency, and as minimal manual effort as possible.
IaC itself can also be automated, further reducing the human effort. With CloudFormation as our IaC, we also have the concept of Drift Detection within the deployed Stack resources as part of the CloudFormation service, so we can validate if any local (e.g., console) changes have been introduced as a deviation from the prescribed template configuration.
Migrating from Origin ID to OAC with CloudFormation
In using CloudFormation changes to migrate between the old and the new ways of securely accessing content in S3, you need to do a few steps to implement and then tidy up.
1. Create the new Origin Access Control Identity:
OriginAccessControlConfig:
Name: !Ref OriginAccessControlName
Description: "Access to S3"
OriginAccessControlOriginType: s3
SigningBehavior: always
SigningProtocol: sigv4If you had a template that created the old OriginAccessId, then you could put this new resource along side that (and later, come back and remove the OID resource).
2. Update your S3 Bucket to trust both the old Origin Access ID, and the new Origin Access Control.
PolicyDocument:
Statement:
-
Action:
- s3:GetObject
Effect: Allow
Resource:
- !Sub arn:aws:s3:::${S3Bucket}/*
Principal:
"AWS": !Sub 'arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ${OriginAccessIdentity}'
"Service": "cloudfront.amazonaws.com"If you wish, you can split that new Principal (cloudfront.amazonaws.com) into a separate statement, and be more specific as to which CloudFront distribution Id is permitted to this S3 bucket/prefix.
In my case, I am using one Origin Access Control for all my distributions to access different prefixes in the same S3 bucket, but if I wanted to raise the bar I’d split that with one OAC per distribution, and a unique mapping of Distribution Id to S3 bucket/prefix.
3. Update the Distribution to use OAC, per Origin:
Origins:
- Id: S3WebBucket
OriginAccessControlId: !Ref OriginAccessControl
ConnectionAttempts: 2
ConnectionTimeout: 5
DomainName: !Join
- ""
- - !Ref ContentBucket
- ".s3.amazonaws.com"
S3OriginConfig:
OriginAccessIdentity: ""
OriginPath: !Ref OriginPathYou’ll note above we still have the S3OriginConfig defined, with an OriginAccessIdentity that is empty. That took a few hours to figure out that empty string; without it, the S3OriginConfig element is invalid, and a CustomOriginConfig is not for accessing S3. At least at this time.
If you’re adopting this, be sure to also look at your CloudFront distributions’ HttpVersion setting; you may want to adopt http2and3 to turn on HTTP3.
4. Remove the existing S3 Bucket Policy line that permitted the old OID
“AWS”: !Sub ‘arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ${OriginAccessIdentity}’ is no longer needed:
PolicyDocument:
Statement:
-
Action:
- s3:GetObject
Effect: Allow
Resource:
- !Sub arn:aws:s3:::${S3Bucket}/*
Principal:
"Service": "cloudfront.amazonaws.com"5. Delete the now unused OID from CloudFront
Back in part 1 where you created the new OriginAccessControl, remove the OriginAccessIdentity resource and update your stack to delete it.
Summary
Of course, run this in your development environment first, and roll steps out to higher environments in an orderly fashion.