Today (Monday 27th of November) is the first day of a new AWS Certification: The AWS Certified Data Engineer —Associate. This is in a beta period now, and as such, any candidates who sit this certification won’t get a result until up to 13 weeks after the end of the beta period.
That beta period is November 27, 2023 – January 12, 2024; so in some time in February or March candidates will find out how they went. During that period, AWS will be assessing where the pass mark should be.
I’ve been pretty forthright in attempting most AWS certifications; I’ve always like to lead from the front to help demonstrate even an aging open source tech geek sys admin like myself can do this. And to that end, I reserved a quiet meeting room at 0200 UTC today (10am AWST) to do the online-proctored exam for this certification.
As always there are terms & conditions on disclosure, so I can only speak at high level. It was 85 questions, the vast majority where to select one correct answer (key) from four possibilities; only a handful had the “select any TWO” option.
The questions I received focuses on Glue, Redshift, Athena, Kinesis, and in passing, S3 and IAM. I say “I received“, as there is a pool of questions, and I would have only had 85 from a larger pool; your assessment would likely be different questions.
It took me around ne hour fifteen minutes, and I went back to review just 2 questrions.
Overall I found this was perhaps a little more detailed and domain based than the existing Associate level certifications. There were use cases for Redshift that I’ve not used that stumped me. There were Glue and Databrew use cases I haven’t used in production.
All in all I think its well placed to ensure that candidates have a solid understanding of data engineering, fault tolerance, cost, and durability of data. For those that are doing cloud native data analytics pipelines, then I would say this should be on your list of certs to get.
We’ll find out in Q1 if I am up to speed on this. 😉
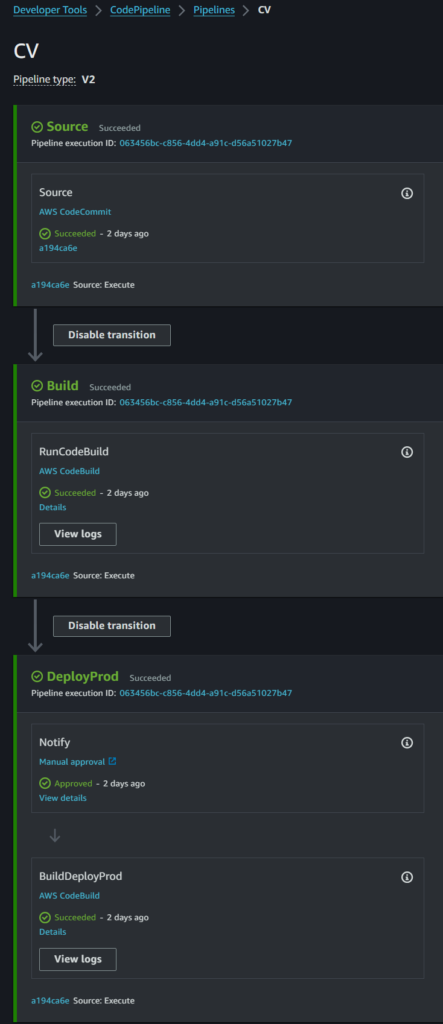
Code build sits amongst a slew of Code* services, which developers can pick and chose from to get their jobs done. I’m going to concentrate on just three of them:
Code Commit: a managed Git repository
Code Build: a service to launch compute* to execute software compile/built/test services
Code Pipeline: a CI/CD pipeline that helps orchestrate the pattern of build and release actions, across different environments
My common use case is for publishing (mostly) static web sites. Being a web developer since the early 1990s, I’m pretty comfortable with importing some web frameworks, writing some HTML and additional CSS, grabbing some images, and then publishing the content.
That content is typically deployed to an S3 Bucket, with CloudFront sitting in front of it, and Route53 doing its duty for DNS resolution… times two or three environments (dev, test, prod).
CodePipeline can be automatically kicked off when a developer pushes a commit to the repo. For several years I have used the native Code Pipeline service to deploy this artifact, but there’s always been a few niggles.
As a developer, I also like having some pre-commit hooks. I like to ensure my HTML is reasonable, that I haven’t put any credentials in my code, etc. For this I use the pre-commit hooks.
Here’s my “.pre-commit-config.yaml” file, that sits in the base of my content repo:
There’s a few more “dot” files such as “.htmllintrc” that also get created and persisted to the repo, but here’s the catch: I want them there for the developers, but I want them purged when being published.
Using the original CodePipeline with the native S3 Deployer was simple, but didn’t give the opportunity to tidy up. That would require Code Build.
However, until this new announcement, using code build meant defining a whole EC2 instance (and VPC for it to live in) and waiting the 20 – 60 seconds for it to start before running your code. The time, and cost, wasn’t worth it in my opinion.
Until now, with Lambda.
I defined (and committed to the repo) a buildspec.yml file, and the commands in the build section show what I am tidying up:
Yes, the buildspec.yml file is one of the files I don’t want to publish.
Time to change the Pipeline order, and include a Build stage that created a new output artifact based upon that. The above buildspec.yml file then has an additional section at the end:
artifacts:
files:
- '**/*'
This the code Build job config, we define a new name for the output artifacts, int his case I called it “TidySource”.However there was an issue with the output artifact from this.
When CodeCommit triggers a build, it makes a single artifact available to the pipeline: the ZIP contents from the repo, in an S3 Bucket for the pipeline. The format of this object’s key (name) is:
The original S3 Deployer in CodePipeline understood that, and gave you the option to decompress the object (zip file) when it put it in the configured destination bucket.
CodeBuild supports multiple artifacts, and its format for the output object defined from the buildspec is:
As such, S3 Deployer would then look for the object that should match the first syntax, and fails.
Hmmm.
OK, I had one more niggle about the s3 deployer: it doesn’t tidy up. If you delete something from your repo, the S3 deploy does not delete from the deployment location – it just unpacks over the top, leaving previously deployed files in place.
So my last change was to ditch both the output artifact from code build, and the original S3 deployer itself, and use the trusty aws s3 sync command, and a few variables in the code pipeline:
You can view the resulting web site at https://cv.jamesbromberger.com/. If you read the footnotes here it will tell you about some of the pipeline. Now I have a new place to play in – automating some of the framework management via NPM during the build phase, and running a few sed commands to update resulting paths in HTML content.
But my big wins are:
You can’t hit https://cv.jamesbromberger.com/.htmllintrc any more (not that there was anything secure in there, but I like to be… tidy)
Older versions of frameworks (bootstrap) are no longer lying around in /assets/bootstrap-${version}/.
Its not costing me more timer or money when doing this tidy up, thanks to Lambda.