In 2004, I was living in London, and decided it was time I had my own little virtual private server somewhere online. As a Debian developer since the start of 2000, it had to be Debian, and it still is…
This was before “cloud” as we know it today. Virtual Private Servers (VPS) was a new industry, providing root login to virtual servers that individuals could rent. And so I started being a client of Bytemark, who in turn offered me a discount as a Debian Gnu/Linux developer. With 1 GB of RAM, the initial VPS was very limited, but I ran my own mail server (with multiple domains), several web site s(all with SNI TLS enabled web sites, my own DNS server, and more.
Several years back I took the move to migrate my domains from being self-hosted on a VPS, to using AWS Route53. It was a small incremental cost, but I had long since stopped playing around and experimenting with DNS, and I wanted something that had high availability then a single virtual machine.
I have run a blog on my web site since the mid 1990’s (30+ years now), and WordPress has been my main platform since the late 2000s. This is WordPress now (2024), however a few years back I slotted AWS CloudFront in front of my origin service, to provide some level of global caching.
Several of the websites I run have also moved off to Amazon CloudFront, in particular all my small MTA STS web sites that serve just one small text file: the Mail Transport Agent Strict Transport Security policy document.
I still run my own mail server, with Exim4, PostgresQL, DoveCot Spamd, ClamD, etc. It lets me experiment with low level stuff that I still enjoy.
I have a few other services I want to move out of my VPS and into individual cloud-hosted platforms, but not everything is ready et. However a recent review of my VPC costings, and a forced migration from ByteMark (ioMart) to a new organisation UK Hosting, forced me to reconsider. So I took the inevitable change and migrated the entire VPS to AWS EC2 in Sydney, closer to where I am most of the time.
And so it comes to pass after 20 years, thank you to the team at Bytemark for my UK VPS.
In 2013 I was presenting to representatives of the South Australian government on the benefits of AWS Cloud. Security was obviously a prime consideration, and my role as the (only) AWS Security Solution Architect for Australia and New Zealand meant that this was a long discussion.
Clearly the shared responsibility model for cloud was a key driver, and continues to be so.
But the question came up: “We’re government, we need our own Region“. At that time, the US had just made its first US GovCloud in August of 2011. I knew then that the cost for a private region then was around US$600M, before you spun up your first (billed) workload.
The best thing about public cloud is, with the safeguards in place around tenant isolation, there are a whole bunch of costs that get shared amongst all users. The more users, the less cost impact per individual. At scale, many things considered costly for one individual, become almost free.
Private AWS Regions are another story: there is not a huge client base to share these costs across. With a single tenant, that tenant pays 100% of the cost. But then that tenant can demand stricter controls, encryption and security protocols, etc.
This difference will perhaps be reflected in the individual unit costs (eg, per EC2 instance per hour, etc).
Numerous secret regions have been created since 2013, such as the Mercury Veil Project for the CIA’s secret AWS Cloud Region.
Today we have two more interesting private regions currently being commissioned: the previously announced European Sovereign Region, and today, the Australian Secret Region at an initial AUD$2B cost.
After 11 years, the cost of a private (dedicated) Region has seemingly increased 333%.
If you thought cloud skills were getting passe, then there’s a top secret world that’s about to take off.
If there is one thing that Cloud customers look for, it is long term availability and stability of the Cloud.
Not only cannot it not go down, but it needs to be long-term sustainable for the provider to operate. And so it comes as some surprise to me that Alibaba has decided to shutter its Regions in India and Australia, according to an article on The Register.
To me this is a clear signal that Alibaba does not want important, long term engagements with customers, anywhere. If they can close these Regions and tell their customers to get out or lose their data, then they can do this in any other Region.
The cost to play the Cloud Provider game is high, and the optics are critical.
This reminds me of the statements made by Google in 2018 , as CNBC reported:
In early 2018, top executives at Alphabet debated whether the company should leave the public cloud business, but eventually set a goal of becoming a top-two player by 2023, according to a report from The Information on Tuesday.
CNBC
Any kinds of indication that the Cloud Provider is not committed long term (multi decade) to being a cloud provider is going to limit the customers trust. of course, the providers then just address the optics by providing statistics slide and diced in such a way as to how them in a favourable light, or including stuff that’s not really cloud in their revenue reporting lines, like software licences.
It’s best to stick to independent industry analysts views of the leaders in the Cloud market place, and to understand the perspective of global versus within a specific country.
If there are any soon-to-be-former Alibaba clients in India or Australia who are now somewhat alarmed at the rug pull from under them, please reach out and I can put you in touch with teams of experts who can help migrate your workloads. See also, my AWS Cloud Migration Consideration series.
Pretty easy to see: time flies pretty quickly if you’re doing what you love. Cloud has been such a change to the IT service delivery industry. For those in the AWS ecosystem, there’s a group of senior experts in the partner (professional & managed services) community, there’s some telling numbers in the statistics, when looking at the AWS Partner Ambassadors.
Universally seen as the original program for the expert engineers in the AWS partners in Australia and New Zealand was called the Cloud Warrior program; this morphed into the Partner Ambassador program in 2017.
Formally, this pre-dates the AWS Community Heroes program by several years.
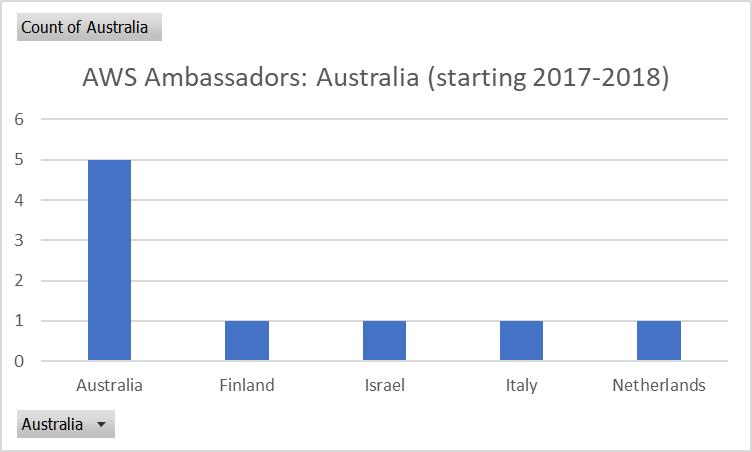
Perusing the participants of this program sorted by date, who in 2024 are still there, we notice that the Australian Ambassadors are still prevalent:
Country of the original and still active AWS Ambassadors, at April 2024
Incidentally, there are three listed with a start date of 2017: Greg Cockburn, Jem Richards and myself — that’s 7 years! And if you expand the view of older Ambassadors to those that joined in 2017 or 2018 and are still active, you see the majority are also from Australia. That’s the core of the AmbassadAussies.
Et ansi? (So what?)
Cloud has a deep history in Australia now, and Australia has a rich history of adopting new technologies and technical expertise. It’s a country where many new technologies are tested, before being “reinvented” in the European or US Markets.
Even though these individuals may work for different organisations during the day, but as engineers, we’re also esteemed peers and friends. We’ve all crossed paths many times in the IT industry over the last few decades.
Greg Cockburn & James Bromberger in Sydney, 2024
Helpfully we have seen some of the Ambassadors having written books, many have written blog posts and articles that have helped guide the industry into the secure and reliable use of AWS Cloud.
All of this helps give knowledge and confidence in to the industry. While my favourite topics are the continuing roll out of IPv6, ever increasing security controls, stronger crypto options, and better managed technical services, the Ambassador group covers nearly all topics, at a level that helps advance the state of the AWS Cloud. And as a community its key to embrace all. No one company has a monopoly on good ideas.
Recently it was that time again in April — the AWS Sydney Summit. This year the client event comprised two days, a Builders Day, and an Innovation Day. For Partners, the prequel is the Partner Summit.
The Partner Summit
Held on the Tuesday from noon onwards at the Hilton Hotel, this event was for the partner communicate to hear the positioning that AWS executives want the partner community to hear.
/
The event was around 400 people, up from 200 in 2023; a common theme we were to see is the return to almost pre-pandemic levels of attendance at this event.
The room seemed quite full, with many standing to the rear (and not just AWS staff standing at the rear!).
Julia Chen showed The regional cloud spend by consumers is, according to Gartners’ Q4 2023 research, still tipped to grow by just under 20%.
Meanwhile, global cloud services spend will hi 1.36 trillion by 2027. One other number that was tossed out was the percentage of workloads currently moved to the cloud: this individual pictured said “10%”, which in contrast to the 2023 messaging of 15% causes some confusion. Have workloads regressed? Or have more workloads been born not on the cloud?
AWS Client Summit: Builders Day
An early 7am start at the International Convention Centre at Darling Harbour.
Darling Harbour in the early morning.
The exhibitor hall floorplan.
What was obvious form the expo hall was the size was back to using the full area of the ICC; the keynotes were not using a partitioned side of the expo floor, and this time, there were more breakout sessions than in 2023 (more than double) – as shown by the purple boxes around the perimeter of the expo floor.
The expo floor had the usual mix of consulting services partners, training partners, and those ISV partners trying to sell tools to complement AWS services or fill the gaps.
It wouldn’t be 2024 without a disproportionate representation of Generative AI in the topics. These high compute, high storage solutions drive revenue, and hype.
Atlassian spoke of their wide usage of AWS, and mass deployment of micro services.
Large $9B invested by Amazon in the Australian region(s) thus far (10 years), and US$13B planned.
Amazon Bedrock, a service to abstract away the operational activities of running LLMs, is now operating and available from the Sydney Region.
The skills shortage in AI and Cloud seems to now be an issue as well, since the entire Gen Ai exploded in the last 12 months., Strap in, as much of this hype will drop off the way that there was no mention of blockchain this year (versus 5 years ago).
Long term employee Dave Brown soke about the various innovations they have done to accelerate the state of the art in Cloud computing.
Dave Brown also highlighted some of the global industries that are leveraging AWS Cloud.
Dave also touched on the community outside of Amazon that are related to the AWS ecosystems. No mention of the AWS Partner Ambassadors.
What was obvious now is that the builders day was aimed at more of the engineers; the presentation sin the keynote had more technical detail, and the audience was a tad under full capacity.
AWS Client Summit: Innovation Day
More mentions of Gen AI
For the Innovation Day, the keynote venue was packed to the rafters: 9,000 people.
Swimming Australia spoke of their performance tracking, analytics, and dashboard applications.
Lots of data of the ambitious approach on sustainability and reaching 100% of Amazon (not just AWS) 5 years earlier than planned, now estimated to happen in 2025, and already covering 90% of Amazon power usage today (April 2024).
A Project Kuiper ground station, with its first launches just having taken place, showed off their three models of receivers, and plans for service readiness.
Dr Carolynn Hogg spoke of storing genetic data in AWS, alongside former NASA CTO Tom Soderstrom (now in an AWS role).
Conclusions…
View of Sydney from the air on departure, April 2024.
So what’s the takeaways from the AWS SUmmit in Sydney for this year.
First, the amount of attendees is back to pre-pandemic levels. The interest is there. The partnership ecosystem has expanded; there’s a lot of organisations looking to help clients who don’t have the skills to do this safely.
I didn’t hear much mention of “shared security models”, or operational activities in the sessions I was in – I think the messaging has now bifurcated along the developer/non-developer line.
GenAI was mentioned in line with the current hype cycle. PoCs are popping up everywhere, and those that are successful are looking at the data lifecycle in GenAI.
Presented case studies from Swimming Australia, UNSW Centre for Genomic Studies, Woodside, 7West media, had previously all had some airtime in the last 12 months, so for those actively listening and processing these, there was nothing ground breaking.
All in all, its another year of evolution: rather than revolution. The steady hand of progress continues.