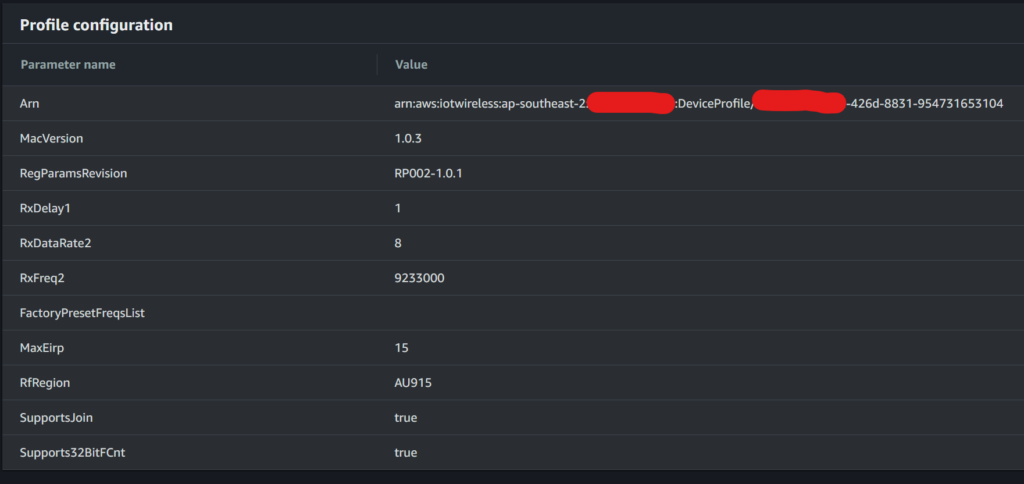
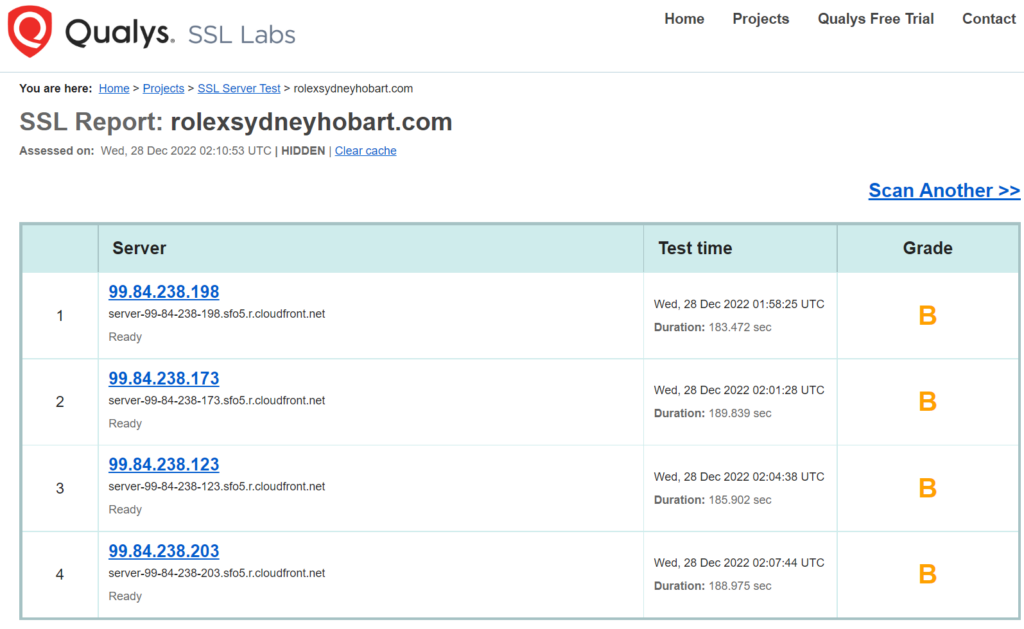
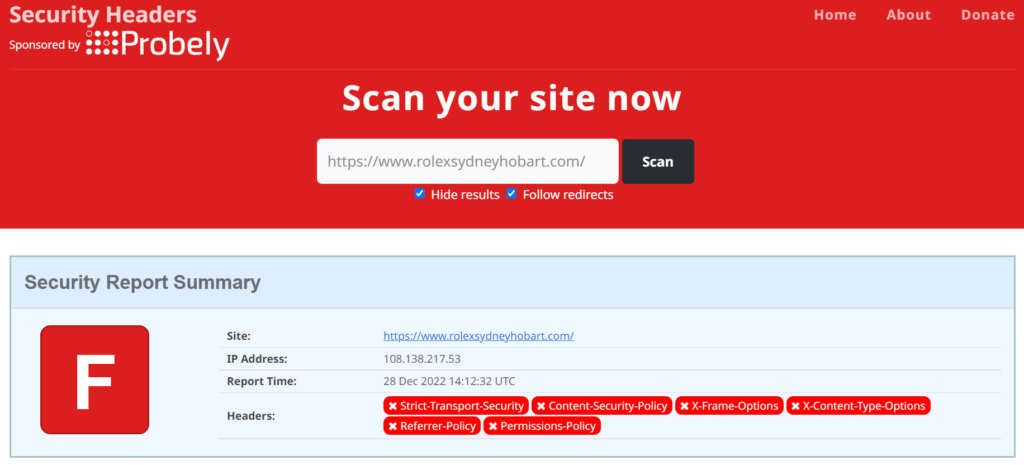
Earlier this week, AWS posted about their expanded support for TLS 1.3, clearly jumping on the reduced handshake as a speed improvement in their blog post entitled: Faster AWS cloud connections with TLS 1.3.
Back in 2017, (yes, 6 years ago) we started raising Product Feature Requests for AWS products to enable this support, and at the same time, customer control to be able to limit the acceptable TLS versions. This makes perfect sense in customer applications (the data plane). Not only do we not want our applications supporting every possible historic version of cryptography, various compliance programs require us to disable them.
Most notable in this was PCI DSS 3.1, the Payment Card (credit card) Industry Association’s Data Security Standard, which drove the nail in to the coffin of TLS 1.1 and everything before it.
Over time, TLS versions (and SSL before it) have fallen from grace. Indeed, SSL 1.0 was so bad it never saw the light of day outside of Netscape.
And it stands to reason that, in future, newer versions of TLS will come to life, and older versions will, eventually, have to be retired; and between those two, is another transition. However, this transition requires deep upgrades from cryptography libraries, and sometimes to client code to support the lower level library’s new capability..
On the server side, we often see a more proactive implementation of what currently supported TLS versions are permitted. Great services like SSLLabs.com, Hardenize.com, and testssl.sh have guided many people to what today’s current state of “acceptable” and “good” would generally look like. And the key item of those services, is their continual uplift as the state of “acceptable” and “good” changes over time.
On the client side, its not always been as useful. I may have a process that establishes outbound connections to a server, but as a client, I amy wan tto specify some minimum version for my compliance, and not just rely upon the remote party to do this for me. Not many software packages do this – the closest control you get is an integration possibly using HTTPS (or TLS), and not the next level down of “yeah, so which versions are OK to use when I connect outbound”. Of course, having specified HTTPS (or TLS) and doing server certificate validation against our local trust store, we then have a degree of confidence hat its probably the right provider, given that one of my 500 trusted CAs signed that certificate. we got given back during the handshake
This sunrise/sunset is even more important to understand in the case of managed services from hyperscaler cloud providers. AWS speaks of the deprecation of TLS 1.1 and prior in this article (June 2022).
If you have solutions that use AWS APIs, such as applications talking to DynamoDB, then this is part of your technical debt you should be actively, regularly addressing. If you haven’t been including updated AWS SDKs in your application, and updating your installed SSL libraries, updating your OS, then you may not be prepared for this. Sure, it may be “working” fine right now.
One option you have is to look at your application connection logs, and see if the TLS version for connections is being logged. If not, you probably want to get that level of visibility. Sure, you could Wireshark (packet dump) a few sample connections, but it would probably be better not to have to resort to that. Having the right data logged is all part of Observability.
June 28 is the (current) deadline for AWS to raise the minimum supported TLS version. That’s a month away from today. Let’s see who hasn’t been listening…