I’ve spoken of the IPv6 transition for many, many years. Last month I gave a presentation at the AWS User Group (Perth) on this, and included a role play on packets through the network.
Earlier in 2022 we saw AWS VPC support IPv6-only subnets, a great way to scale out vast numbers of instances with 18 billion billion addresses per subnet. Today sees one of the most commonly used services with virtual machines – managed databases via the Relational Database Service – finally get its first bit of IPv6 support!
When creating a database, you now have a new option as shown here:
AWS Console Wizard for starting an RDS instance
It’s worth noting that, the Database Subnet defined in RDS can (at this point in time) select subnets that are either IPv4 only, or dual stack IPv4 and IPv6. To put this clearer, RDS is not (yet?) supporting IPv6 only deployment.
But that’s a small limitation. The power of scale-out of application servers in vast subnets can now natively talk to a dual-stack deployed RDS Instances using IPv6 as the transport protocol. No other proxies or adaptors or work-around required.
Of course, there’s more managed AWS services to even get this far – ElasticCache, for example, or even IPv6 as first class (eg: CloudFront origin fetch).
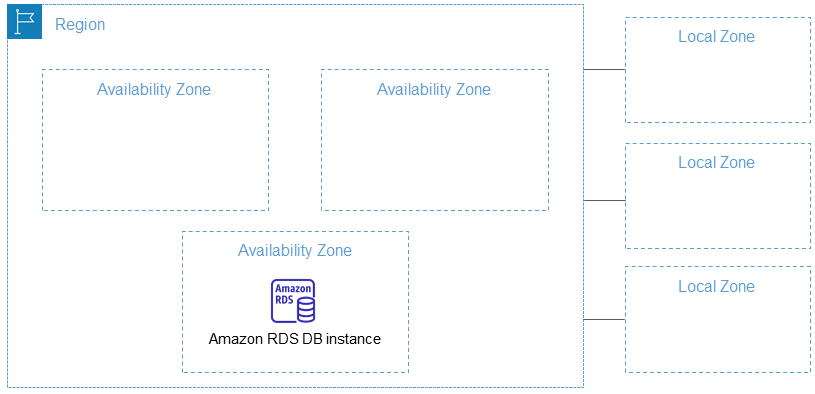
AWS recently made a bold announcement; at re:invent in specified a few countries it planned to open Local Zones in, but last week it revealed some 32 locations, including Perth, Brisbane, and Auckland
Perth is isolated by the vast distances between east and west coast of Australia – 2044 miles, similar distances to the continental United States between DC and LA (2200 miles), or London to Moscow (2500 miles). The Round Trip Time (RTT) of packets online is around 50ms, which for many applications is not immediately noticeable.
But for some time-critical workloads, its a deal breaker.
Local Zones offer a very cut down version of an AWS Region, targeting compute workloads that use a virtual machine Instance. First available in Japan, there are currently 16 in service; this recent announcement of 32 more will make 48 Local Zones.
While many have become familiar with AWS, the minimal viable product of a Local Zone may leave some confused: the options at your disposal are listed here.
Local Zone attachments
Local Zones are attached to a host Region. In the case of the announced Perth Local Zone, the API designation for this indicates this will be linked to the yet-to-launch Melbourne Region.
When it comes to load balancing within the Local Zone, typically only Application Load Balancing (ALB) is available. That’s perfect for HTTP based workloads with multiple local application servers, but if you’re looking to then add a managed RDS database behind that, you’ll be reaching back to the host Region. Same for SQS, SNS, and most everything else.
Instance types will also be limited, typically focusing on a subset of the latest general purpose families; this is likely to be true of the Elastic Block Store (EBS) volumes, where until now, GP2 (General Purpose SSD) has been the primary option.
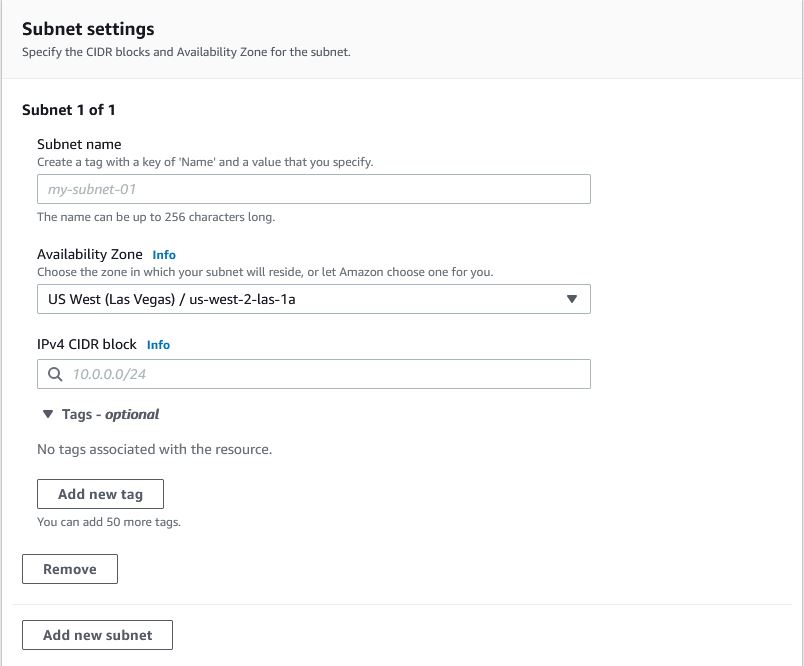
When it comes to networking, it appears that Local Zones do not yet support IPv6 dual-stack addressing, as shown in the Console option for defining a subnet with the current Oregon/Los Angeles Local Zone:
IPv4 only subnet creation in Oregon/LA
So, what would benefit from Local Zones? Well architectures with local access direct to instances, that perhaps transform and validate requests on the edge, or perhaps cache responses at the edge before forwarding more efficient queries across the “VPC-internal” connectivity to the host Region. Another use case may be local EC2 Windows Instances, where the reduced latency may make RDP access a seamless desktop experience.
Perhaps some Local Zones will supplant the need for on-premesis Outposts deployments.
Perhaps over time more architectural patterns will come about, and more services will start to make their way into the common Local Zone implementation. Some Local Zones may grow to become full Regions, as happened with the original Osaka (Japan) Local Zone.
Regardless of the way it ends up being used, the expansion is a massive step up in the globally deployed infrastructure.
For those not familiar, SSH is the Secure Shell, an encrypted login system that has been in use for over 25 years. It replaced unencrypted Telnet for remote (text) terminal connections used to access (and administer) systems over remote networks.
Authentication for SSH can be done in multiple ways: simple passwords (not recommended), SSH Keys, and even MFA.
SSH keys is perhaps one of the most common ways; its simple, free, and relatively easy to understand. It uses asymmetric key pairs, consisting of a Private key, and a Public Key.
Understandably, the Private key is kept private, only on your local system perhaps, and the Public key which is openly distributed to any system that wishes to give you access.
For a long time, the Key algorithm used here was the RSA algorithm, and keys had a particular size (length) measured in bits. In the 1990s, 128 bits was considered enough,but more recently, 2048 bits and beyond has been used. The length of the key was one factor to the complexity of guessing the correct combination: fewer bits means smaller numbers. However, the RSA algorithm becomes quiet slow when key sizes start to get quite large, and people (and systems) start to notice a few seconds of very busy CPU when trying to connect across the network.
Luckily, a replacement key algorithm has been around for some time, leveraging Elliptical Curves. This article gives some overview of the Edwards Curve Elliptical Curve for creating the public and private key.
What we see is keys that are smaller compared to RSA keys of similar cryptographic strength, but more importantly, the CPU load is not as high.
OpenSSH and Putty have supported Edwards curves for some time (as at 2022), and several years ago, I requested support from AWS for the EC2 environment. Today, that suggestion/wish-list item has come to fruition with this:
AWS has been one of the last places I was still using RSA based keys, so now I can start planning their total removal.
Clearly generating a new ED25519 key is the first step. PuttyGen can do this, as can ssh-keygen. Save the key, and make sure you grab a copy of the OpenSSH format of the key (a single line that starts with ssh-ed25519 and is followed by a string representing the key, and optionally a space and comment at the end). I would recommend having the Comment include the person name, year and possibly even the key type, so that you can identify which key for which individual.
You can publish the Public Key to systems that will accept this key – and this can be done in parallel to the existing key still being in place. The public key has no problem with being shared and advertised publicly – its in the name. The worse thing that someone can do with your public key is give you access to their system. In Linux systems, this is typically by adding a line to the ~/.ssh/authorized_keys file (note: US spelling); just add a new line starting with “ssh-ed25519”. From this point, these systems will trust the key.
Next you can test access using this key for the people (or systems) that will need access. Ensure you only give the key to those systems or people that should use it. Eg, yourself. When you sign in, look for evidence that shows the new key was used. For example, the Comment on the key (see point 1 above) may be displayed, such as:
Lastly you can remove the older key being trusted for remote access from those systems. For your first system, you may one to leave one SSH session connected, remove the older SSH key from the Authorized Keys file, and then initiate a second new connection to ensure you still have access.
Now that we have familiarity with this, we need to look at places where the older key may be used.
In the AWS environment, SSH Public Keys are stored in the Amazon EC2 environment for provision to new EC2 instances (hosts). This may be referenced and deployed during instance start time; but it can also be referenced as part of a Launch Configuration (LC) or Launch Template (LT). These LCs and LTs will need to be updated, so that any subsequent EC2 launches are provisioned with the new key. Ideally you have these defined in a CloudFormation Template; hence adjusting this template and updating the stack is necessary; this will likely trigger a replacement of the current instances, so schedule this operation accordingly (and test in lower environments first).
There’s no sudden emergency for this switch; it is part of the continual sunrise and sunset of technologies, and address the technical debt in a systematic and continual way, just as you would migrate in AWS from GP2 to GP3 SSD EBS volumes, from one EC2 instance family to the next, from the Instance MetaData v1 to v2, and or from IPv4 to dual-stack IPv6.
In December, Gartner produced another one of their Magic Quadrants comparing the offering from various Cloud service providers focusing on their database offerings. While its like reading tea leaves, its interesting to see the jostling of the players, the new departures who are excited (funded) enough to run an analyst relations ream, and those who are dropping out.
You can get a copy of the current report from Gartner, AWS, or the 2020 version from Google.
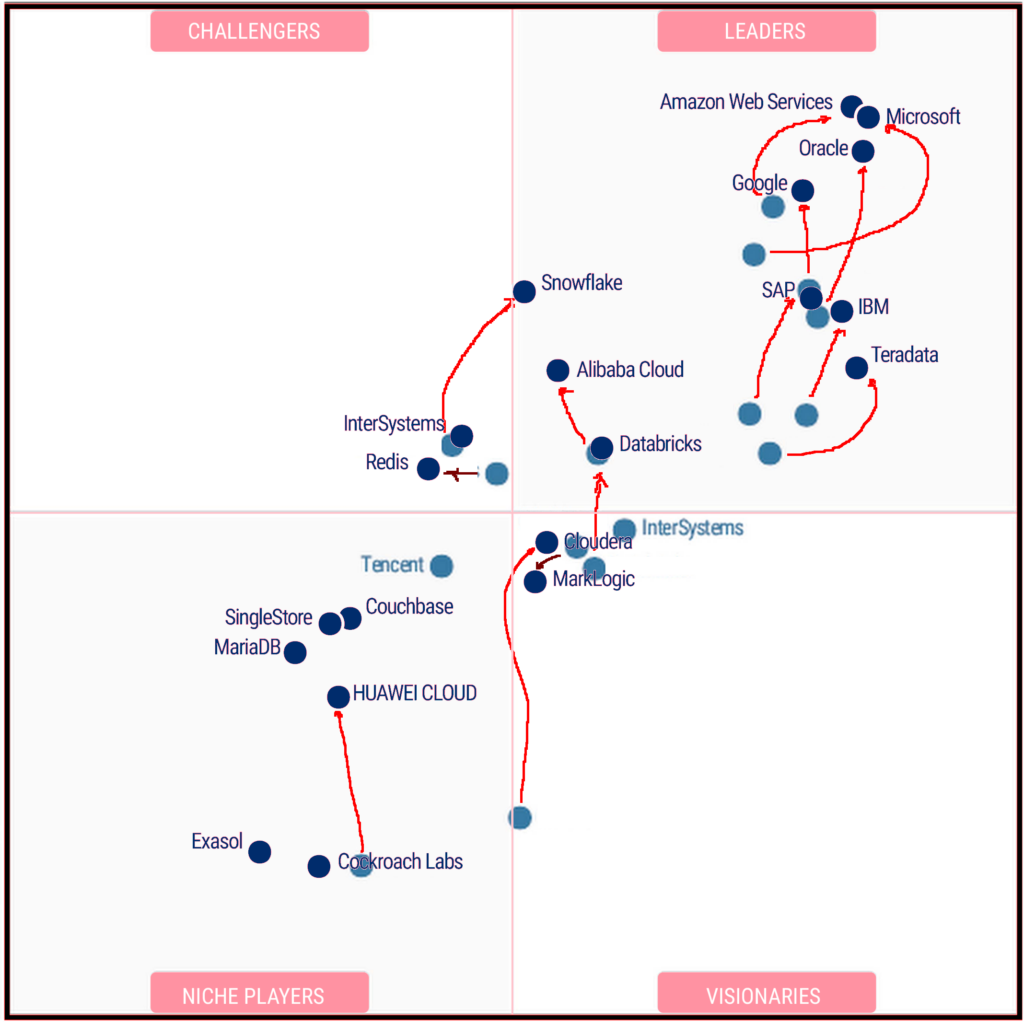
Here’s a mash up comparing the two years; the darker navy blue is 2021, and the lighter blue dots are 2020.
New to this in 2021 are:
Intersystems
MariaDB
Single Store
Exasol
Cockroach Labs
Leaving the magic quadrant in 2021 are Tencent.
Much improved are AWS and Microsoft who continue to lead – these two are now ranked neck and neck, with Oracle sitting behind them (but also improved). IMHO, those increasing in position are SAP, Teradata, Snowflake, Databricks an Cloudera, and even Huawei.
At the same time, relative to the others in this list, are two that are dropping in comparison: Redis and Marklogic – but only slightly.
As we round out another year, here’s a perspective on where we are up to on the IPv6 transition that has been going for 20 years, but now gathering momentum.
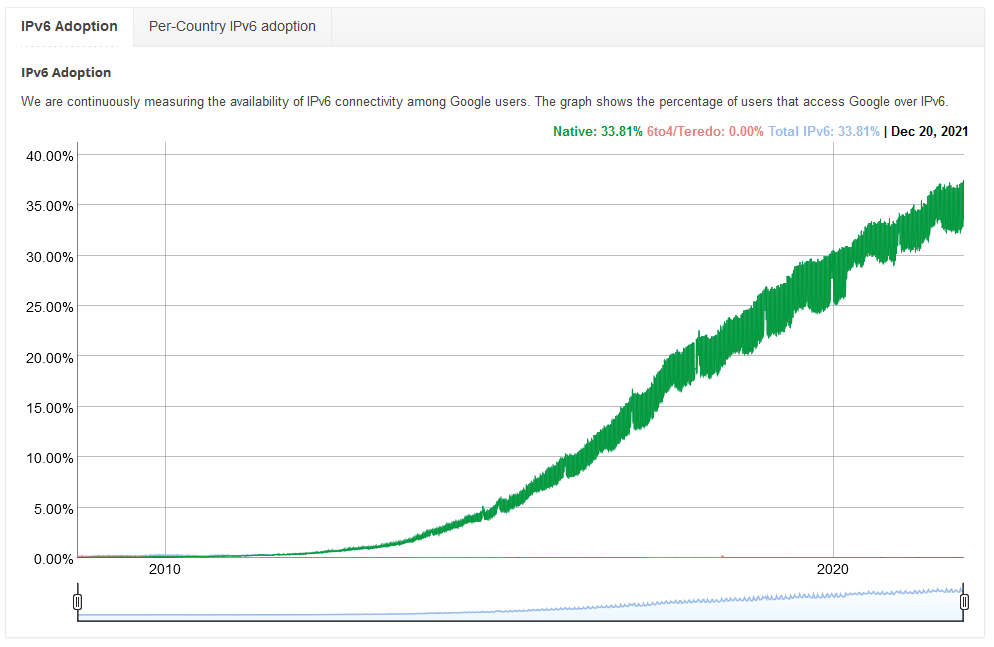
With around 33% of traffic being IPv6, its reasonably significant on a global level. The country-by-country map shows the US on 47%, Germany at 55%, UK on 34%, and Australia at 27%. We’re fast reaching the tipping point where IPv6 is the expected traffic type.
Clearly, the biggest factor is going to be the destination services that people (and systems) want to get to offering IPv6, and then the client (users) having IPv6 available to then send that traffic.
In Australia, the dominant cell phone provider, Telstra, has been using IPv6 for its consumer business since 2016. Now, five and a half years later, we’re still waiting for Optus (Singtel), Vodafone, and many more to pick up.
For ISPs: iiNet continues to show no innovation since the engineering talent departed in the post TPG acquisition. Aussie Broadband (whom I churned to) still call their IPv6 offering a beta, but its been very stable for me now for… years. Perhaps time to take the beta label off?
IPv6 on the Cloud
AWS made many IPv6 announcements through pre-Invent and re:invent (the annual AWS Cloud summit/conference).
Many key services already had 1st class dual-stack support for IPv6 along side IPv4. Key amongst this is Route53, serving DNS responses on either transport layer.
Now we’re seeing IPv6 only capability, as IPv4 starts to look more and more like a legacy transport protocol.
With that perspective, its a shame to see how many of the trusted brands back on the commercial ISP and Mobile carrier market just aren’t up to speed. No engineering investment to really modernise.
AWS VPC: IPv6 only subnets
When defining a VPC, one of the most durable configurations is the IPv4 CIDR range assigned. Once allocated, its set. You can add one more IPv4 allocation if you must, in a separate range, with all kinds of complications.
Since 2016 AWS has permitted an IPv6 network allocation to dual-stack subnets in a VPC, and to allocate to an EC2 instance. Traffic within the VPC was still primarily IPv4 – for services like RDS (databases), etc. Slowly we’ve seen Load Balancers become dual-stack, which is one of the most useful pieces for building customer/internet facing dual-stack, but then fall back to IPv4 on the private side of the load balancer.
The IPv6 in subnets had an interesting feature. Initially the address allocation was only, but now you can BYO, however, the subnet size is always /56, some 18 quintillion IP addresses. Compare with IPv4, where you can make subnets from /28 (14 IPs) to /16 (65,533 IPs).
Two common challenges used to appear with IPv4 subnets: one, you ran out of addresses, especially in public subnets with multiple ALBs of variable traffic pattern peaks, and two: a new Availability Zone launch, and the contiguous address space needs some consistency to meet with traditional on-premises (internal) firewalling.
Now, you only have the one consideration: contiguous address space, but you’re unlikely to exhaust a subnet’s IPv6 address allocation.
When ap-southeast-2 launched, I loved having two Availability zones, and in the traditional IPv4 address space, I would allocate a contiguous range for each purpose across AZs equally. For example:
Purpose
AZ A
AZ B
Supernet
Public
10.0.0.0/24
10.0.1.0/24
10.0.0.0/23
Apps (Private)
10.0.2.0/24
10.0.3.0/24
10.0.2.0/23
Databases (Private)
10.0.4.0/24
10.0.5.0/24
10.0.4.0/23
Contiguous address space across two AZs
From the above, you can see I can summarise up the two allocations for each purpose, the one in AZ A and AZ B, into one range.
Now for various points I wont dive into her, having TWO AZs is great, but having three is better. However, address space is binary and works in powers of two the purpose of subnetting and supernetting, so if I wanted to preserve contiguous address space, then I would have kept the 10.0.2.0/24 reserved for the AZ C, and then have a left over /24 (10.0.3.0/24) in order to make a larger supernet of 10.0.0.0/22 to cover all Public Subnets:
Purpose
AZ A
AZ B
AZ C
Reserved
Supernet
Public
10.0.0.0/24
10.0.1.0/24
10.0.2.0/24
10.0.3.0/24
10.0.0.0/22
Apps (Private)
10.0.4.0/24
10.0.5.0/24
10.0.6.0/24
10.0.7.0/24
10.0.4.0/22
Databases (Private)
10.0.8.0/24
10.0.9.0/24
10.0.10.0/24
10.0.11.0/24
10.0.8.0/22
Now we’ve split our address space four ways, preserved continuity to be able to subnet, but we had to reallocate the .2 and .3 ranges. What a pain.
Now, we can take VPC subnetting further; the next increment would be provisions for 8 AZs. That’s probably a stretch for most organisations, so 4 seems to be most common.
Now take an IPv6 lens over this, and the only thing you’re looking at keeping contiguous over the IPV6 range is the order of allocation, from :00:, through to :03: for the Public Subnets, and then :04: to :07: for apps, and :08: to :0b: (yes, its hex) for the Databases.
Going backwards from IPv6 toIPv4
Another release at reinvent for VPC was the support for DNS64, and NAT64 on NAT Gateway. On a subnet by subnet basis, you can have the DNS resolver return a specially crafted IPv6 address that actually has an IPv4 embedded in it; when used with NAT64,then NAT Gateway will bridge the traffic going outbound from IPv6 internally, back to IPv4 externally. Now you can adopt modern IPv6 internal topologies, but still reach back into the past for those integrations that haven’t gone dual-stack yet.
Of course, this would be far easier if, for all services you wanted to access, you already had the choice of IPv4 or IPv6. Which, as a service provider, you should be offering to your integration partners already.
Load Balancers end-to-end IPv6
Until recently, when traffic from the Internet hit an ALB or NLB over IPv6, it would drop down to IPv4 for the internal connection; however that changed during reinvent with end-to-end IPv6. Virtual Machines (EC2 instances) now see the originating IPv6 address in packets.
Summary
Its been 3 years since some of the critical state government projects I was working on went dual stack in AWS. I encourage my teams to present dual-stack external interfaces, and to prepare all customer environment for this switch over as part of their managed services and professional services deployments. Its not complicated, it doesn’t add any cost, and it can be a competitive advantage. Its another example of a sunrise and sunset of yet another digital standard, and it wont be the last.