When I worked at AWS in 2012-2014, I championed the adoption of IPv6. I’ve spoken about Ipv6 many times on this blog, at AWS User Group Meetings, and with my colleagues at work. We’ve deployed solutions dual-stack for clients where there hasn’t been any cost implications in doing so.
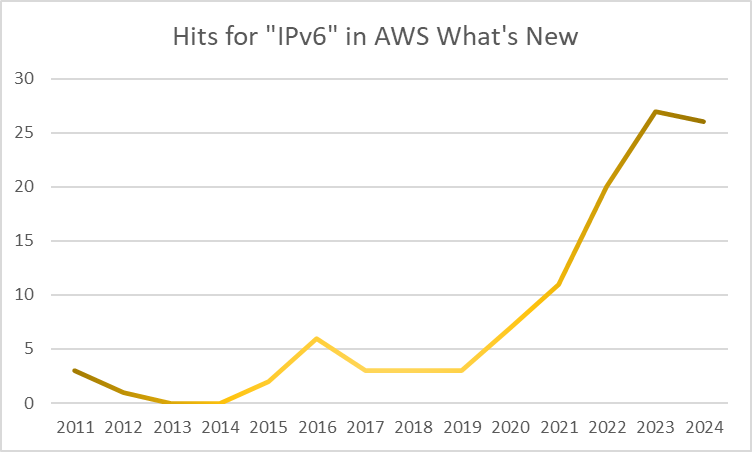
Over time, a number of “What’s new” posts have shown where IPv6 capability has been added. Now after 10 years since I departed AWS, I though I would look at the rate of IPv6 announcements and see =how it stacked up over time.
Clearly we can see an uptick in announcements from 2021 onwards. Additional managed services are still adopting; perhaps the rate of change is leveling out now.
I’ve switched to using Unifi a few years back, and made the investment in a Unifi Dream Machine when my home Internet connection exceeded 25 MB/sec — basically when NBN Fibre to the Premises (FTTP) became available in my area, replacing the ADSL circuit previously used.
I’d also shifted ISPs, as I wanted one that gave me native IPv6 so that I can test customer deployments (and be ahead of the curve). I selected Aussie Broadband, and they have been very good.
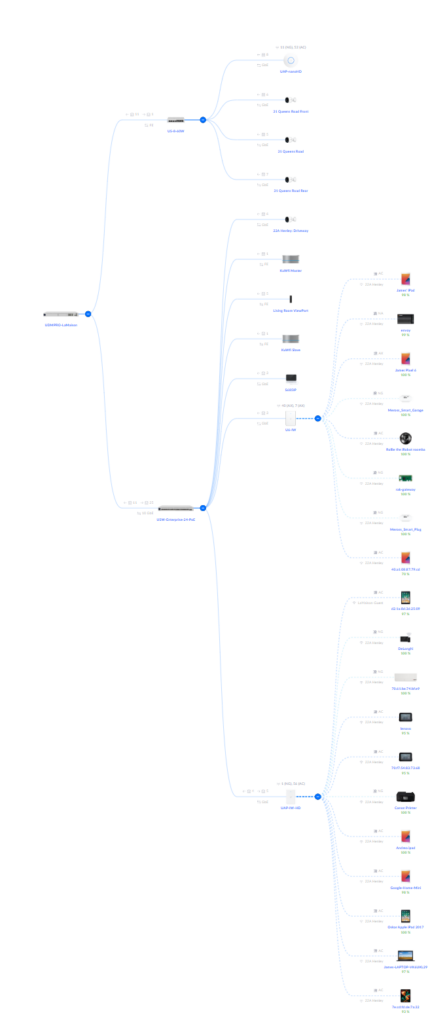
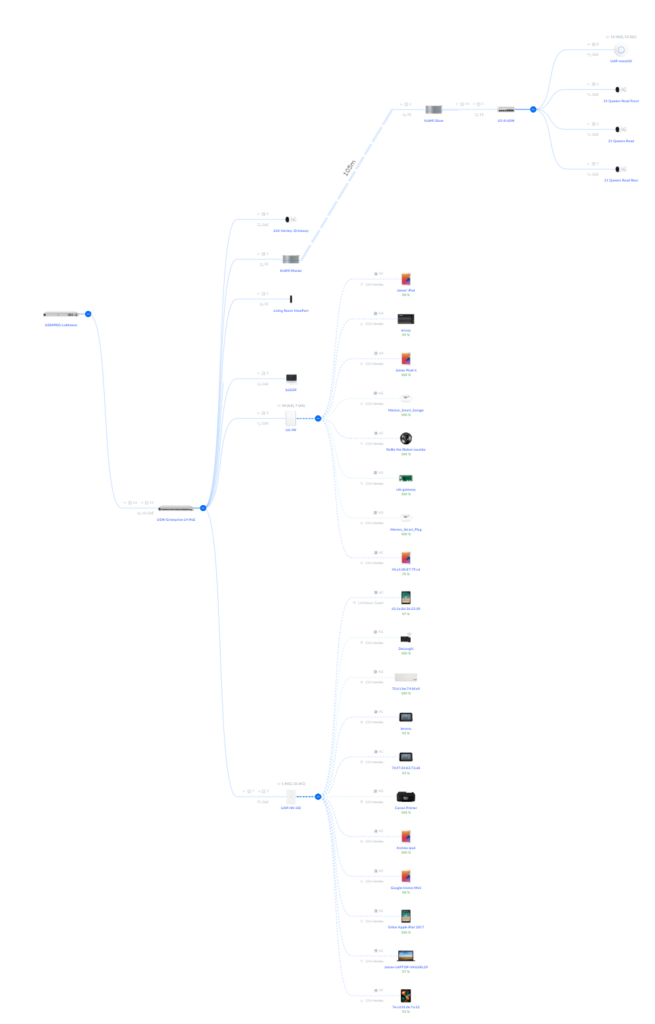
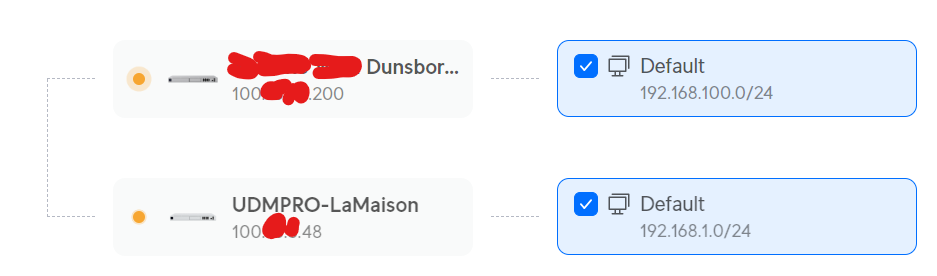
Here’s what my home network topology looks like, according to Unifi:
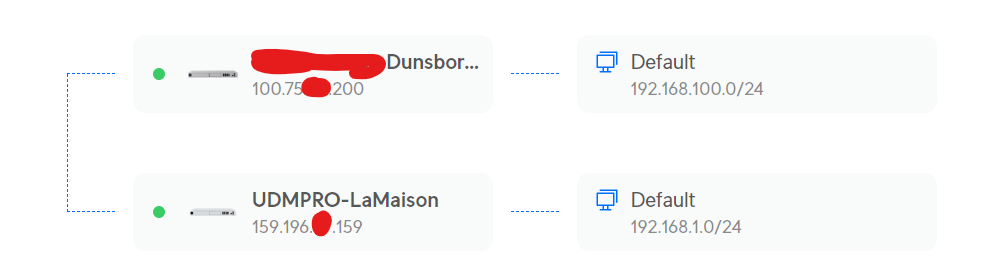
But actually, this is what it really is like:
The difference is the top cluster, which has the two point-to-point devices, separated by around 105 meters (300ft), which the Unifi device does not see.
Meanwhile, my family had a separate property 300 kms away in the southwest of Western Australia, which until two months ago, had been a totally disconnected site: no Internet and no telephone. With aging family members, it was becoming more pressing to have a telephone service available at the property, and resolve the issue of using a mobile hot spot when on site.
At the same time, we had a desire to get some CCTV set up, and my Unifi Protect had been working particularly well for several years now at my location(s) – including over a 100m point-to-point WiFi link.
Once again, we selected Aussie Broadband as an ISP, but a slower Fibre to the Node (FTTN) was delivered, which we weren’t expecting. This required an additional VDSL bridge to convert from the analogue phone line, to ethernet presentation to the UDM SE gateway/router.
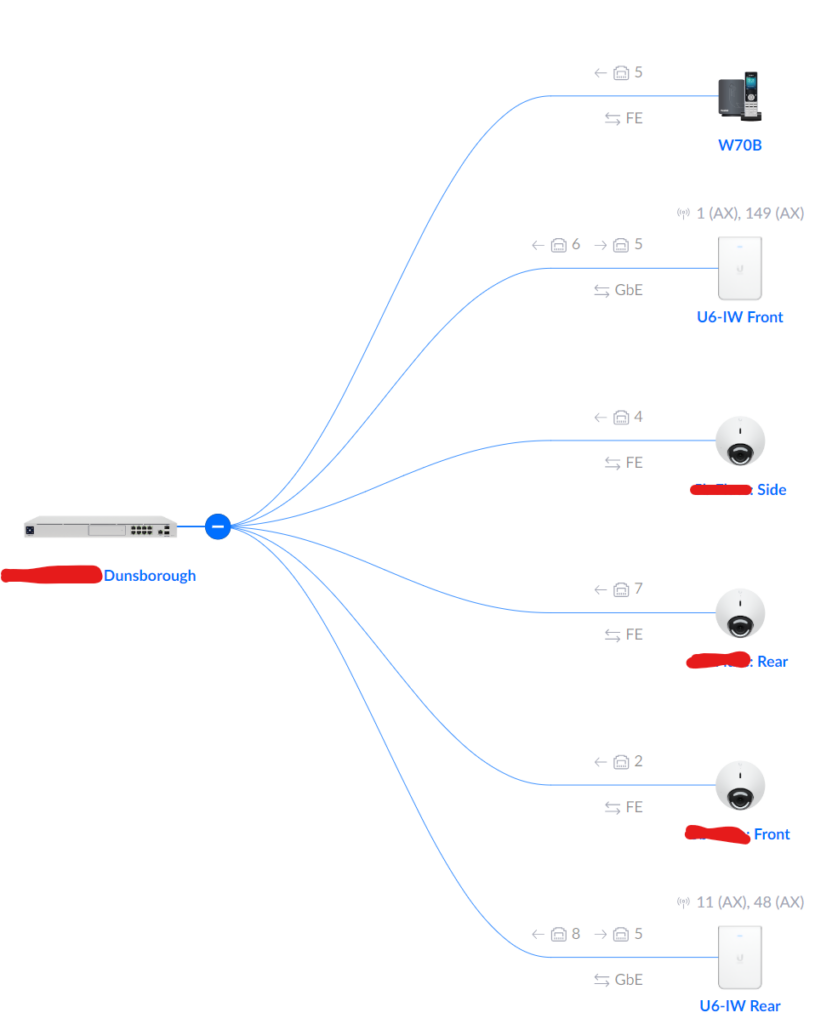
Here’s the topology of the new site:
Easy. The Unifi device has some great remove administration capabilities, which means ensuring everything is working is easy to do when 300 kms away.
Unifi Site Magic
And then this week, I see this:
So I wander over to unifi.ui.com, and try to link my two sites – one subnet at each of the two sites, and it starts to try to connect:
But after a while, I give up. It won’t connect.
I see it only supports IPv4 (at this time). Everything else looks fine…
It’s only then (after a post to the Ubiquiti forums) that I’m pointed at the face that both sites are on 100.xxx, which are reserved addresses for Carrier Grade NAT.
A quick look up on the Aussie Broadband site, and I see I can opt out of CGNAT, and today I made that call. Explaining the situation, I requested one site be moved out (I’m not greedy, and IPv4 space is scarce).
Am hour later, and I have a better outcome:
And now, from Perth, I can ping the VoIP phone on-site 300 kms away behind the router:
C:\Users\james>ping 192.168.100.122
Pinging 192.168.100.122 with 32 bytes of data: Reply from 192.168.100.122: bytes=32 time=19ms TTL=62 Reply from 192.168.100.122: bytes=32 time=20ms TTL=62 Reply from 192.168.100.122: bytes=32 time=19ms TTL=62 Reply from 192.168.100.122: bytes=32 time=19ms TTL=62
Ping statistics for 192.168.100.122: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 19ms, Maximum = 20ms, Average = 19ms
What’s interesting is that only ONE of my sites had to be popped out from behind the ISP’s CGNAT, and the Site Magic worked.
Of course in future, having IPv6 should be sufficient without having to deal with CGNAT.
It was always going to happen. We’ve been watching the exhaustion of the 32 bit address space of IPv4 for more than 20 years, and we’ve had the solution available for even longer: IPv6.
I’ve written many times about IPv6 adoption and migration on this blog. I’ve spoken many times with colleagues about it. I’ve presented at AWS User Groups about using IPv6 in AWS. And when I worked at AWS 10 years ago, I championed that s a competitive advantage to IPv6 all the things where IPv4 was in use.
The adoption has been slow. Outside of the Cloud, ISP support has been mixed, depending if they have the engineering capability to uplift legacy networks, or not. Let’s be clear – those ISPs who removed their engineers, and minimise the innovation, are about to have a lot of work to do, or face tough conversations with customers.
For those that have already done the work, then this weeks AWS annoucement about the start of charging for public IPv4 address space from 2024 is a non-issue. For others, its going to start to mean some action.
You’re back, ok, so at time of blogging, charges start in 2024. Currently, your first IPv4 assigned to an instance is not charged for, but soon it will be half a US cent per hour, or on a 744 hour month, US$3.72 a month. Not much, unless you have hundreds of them.
Selling an IPv4 netblock
In the last few years I helped a government agency “sell” an unused /16 IPv4 netblock for several million dollars. They had two of them, and had only ever used a few /24 ranges from their first block; the second block was not even announced anywhere. There was no sound plan for keeping them.
The market price to sell a large contiguous block of addresses keeps going up – 4 years ago it was around $22 per IPv4 address (and a /16 is 65,536 of them, so just over US$1.4M). Over time, large contiguous address blocks were becoming more valuable. Only one event would stop this from happening: when no one needed them any more. And that event was when the tipping point into the large spread (default) usage of IPv6, at which time, they drop towards worthless.
The tipping point just got closer.
Bringing it back to now
So with this announcement, what do we see. Well, this kind of sums it up:
Congratulations, your IPv6 migration plan just got a business case, AWS is now charging for v4 addresses. v6 is free, and the sky has finally fallen:
Nick Matthews @nickpowpow
There have been many IPv6 improvements over the years, but few deployments are ready to ditch IPv4 all together. Anything with an external deployment that only supports IPv4 is going to be a bit of a pain.
Luckily, AWS has made NAT64 and DNS64 available, which lets IPv6 only hosts contact IPv4 hosts.
The time has come to look at your business partners you work with – those you have API interfaces to, and have the IPv6 conversation. It’s going to be a journey, but at this stage, its one that some in the industry have been on since the last millennium (I used to use Hurricane Electric’s TunnelBroker IPv6 tunnelling service in the late 1990s from UWA for IPv6).
Looking at your personal ISP and Mobile/Cell provider
It’s also time to start to reconsider your home ISP and cell phone provider if they aren’t already providing you with real IPv6 addresses. I personally swapped home Internet provider in Australia several years ago, tired of the hollow promises of native IPv6 implementation from one of Australia’s largest and oldest ISPs, started by an industry friend of mine in Perth many years ago (who has not been associated with it for several years). When the ISP was bought out, many of the talented engineers left (one way or another), and it was clear they weren’t going to implement new and modern transport protocols any time soon.
Looking at your corporate IT Dept
Your office network is going to need to step up, eventually. This is likely to be difficult, as often corporate IT departments are understaffed when it comes to these kinds of changes. They often outsource to managed service providers, many of whom don’t look to the future to see what they need to anticipate for their customers, but minimise the current present cost to “keep the lights on”. This is because customers often buy on cost, not on quality or value, in which case, the smart engineers are elsewhere.
Your best hope is to find the few technically minded people in your organisation who have already done this, or are talking about this, and getting them involved.
Looking at your internet-facing services
There’s only one thing to do, ASAP: dual-stack everything that is [public] Internet facing. Monitor your integration partners for traffic that uses IPv4, and talk to them about your IPv6 migration plans.
Its worth watching for when organisations make this switch. There are many ways to do this.
For web sites and HTTP/HTTPS APIs, consider using a CDN that can sit in front of your origin server, and as the front-door to your service, can be dual stack for you. Amazon CloudFront has been a very flexible way to do this for years, but you must remember both steps in doing this:
Tick the Enable IPv6 on the CloudFront distribution
Add a record to your DNS for the desired hostname as an AAAA record, alongside the existing A record.
The Long Term Future
IPv4 will go away, one day.
It may be another 20 years, or it may now be sooner given economic pressures starting to appear. Eventually the world will move on past Vint Cerf’s experimental range that, from the 1970s, has outlasted all expectations. IPv4 was never supposed to scale to all of humanity. But its replacement, IPv6, is likely to outlast all of us alive today.
I first used a physical VoIP phone when I was living in London, in 2003. It was made by Grandstream, was corded, and registered to a SIP provider in Australia (Simtex, whom I think on longer exist).
It was rock solid. Family and friends in Australia would call our local Perth telephone number, and we’d pick up the ringing phone in London. Calls were untimed, no B-party charging, and calls could last for hours without fear of the cost.
The flexibility of voice over internet was fantastic. At work, I had hard phones in colo cages and office spaces from San Francisco, to New York, Hamburg and London, avoiding international roaming charges completely.
The move to Siemens Gigaset
Sometime around 2008/2009, I swapped the Grandstream set for a Siemens Gigaset DECT wireless system: a VoIP base station, and a set of cordless handsets that used the familiar and reliable DECT protocol. The charging cradle for handsets only required power, meaning the base station could be conveniently stashed right beside the home router – typically with DSL where the phone line was terminated.
It was fantastic; multiple handsets, and the ability to host two simultaneous, independent (parallel) phone calls. In any household, not having to argue for who was hogging the phone, and missed inbound calls was awesome. And those two simultaneous calls were from either the same SIP registration or up to 6 SIP registrations.
Fast forward to 2022, and I still use the exact, same system, some 13 years later. I’ve added additional handsets. I’ve switched calling providers (twice). Yes, we have mobile phones, but sadly, being 8,140 meters from the Perth CBD is too far for my cell phone carrier (Singtel Optus) to have reliable indoor coverage. Yes, I could switch to Telstra, for 3x the price, and 1/3 the data allowance per month (but at least I’d get working mobile IPv6 then).
Gigaset has changed hands a few times, and while I’ve looked at many competitors over the years, I haven’t found any that have wrapped up the multi-DECT handset, answer phone, VOIP capability as well.
Yes, there are some rubbish features. I do not need my star sign displayed on the phone. Gigaset themselves as a SIP registrar has been unnecessary for me (YMMV).
And there are some milder frustrations; like each handset having its own address book, and a clunky Bluetooth sync & import to a laptop, or each handset having its own history of calls made. And, no IPv6 SIP registration.
What they haven’t done (that I have found) is make it clear which model is newer, and which models are superseded. Indeed, just discovering some of the models of base station in the domestic consumer range is difficult.
So the base station: which model is current? A Go Box 100? N 300? Comfort A IP flex? N300? Try finding the N300 on the gigset.com web site!
Can I easily compare base station capabilities/differneces without comparing the handsets – no!
I am looking for a base station that now supports IPv6, and possibly three simultaneous calls (two is good, but three would be better).
I keep returning to gigaset.com to hope they have improved the way they present their product line up, but alas, after 5 years or looking, it’s not got any better. It’s a great product, fantastic engineering, let down by confusing messaging and sales. At least put the release year in the tech spec so we can deduce what is older and what is newer, for both handsets and base station.
I feel that if Gigaset made their procurement of base station and handsets clearer they’d sell far more.
Like many, I ditched my out of date ISP provided home gateway a few years back, and about a year ago put in a Unifi Dream Machine Pro as a home gateway, and a pair of Unifi Access Points, implementing WiFi 5 (802.11ac), and able to take better advantage of the 1GB/50MB NBN connection I have.
Now, I find that WiFi 5 maxes out at around 400 MBit/sec, so I’ve been waiting for the newer WiFi 6 APs to launch – in particular the In-Wall access point. However, then comes along WiFi 6E, using the newly available 6 GHz spectrum, as well as dropping to the 5Gz and 2.4 GHz spectrum.
Then I went one further, and acquired a 16 TB HDD into the Unifi Dream Machine Pro and a single G4 Pro camera. This gave me around 3 months of continuous recording, and has helped pin point the exact time a neighbours car got lifted, as well as showing us the two times before that the perps drove past – all from the end of a 50 meter driveway an the other side of a closed vehicle gate.
I wanted to have an easy way my family can bring up the video feed on the TV, large enough to see detail from each camera.
But then the pandemic hit, and the global supply chain brought things to a standstill. Unifi, and their Australian distributors and retailers, have been sorely out of stock for a long time. Only one WiFi 6E product has launched from Ubiquiti thus far, and like most of their products, immediately sold out on their US store and hasn’t made it to Aus yet. Even the UDM Pro Special Edition hasn’t surfaced either in stock in the US, or from the Australian Distributors.
So it was with some glee I found just 5 of the Unifi Viewport devices had made it to Australia last week, the first time I’d seen stock in a year (I could have missed it). So I pounced on it, and today I unboxed it.
Unifi Protect ViewportContents and box of the Unifi Protect Viewport
The device shipped with an HDMI cable, some screws and a wall mount, and a small slip of instructions.
At one end of the device is a standard Ethernet port, th eother end has an Ethernet-out port, and an HDMI-out port. That’s handy if you already have a device that’s on Ethernet, like your TV itself, without running another patch back to your switch.
The actual Viewport itself was larger than I had expected, as shown when I hold it in my hand here:
Unifi Protect Viewport
I plugged it into a patch to a POE port on my Switch-8, and immediately it powered up, took a DHCP lease, and was shown as pending for adoption into my network.
The adoption took a moment, then a firware update and reboot, and then it automatically connected and started showing the default layout of cameras from Unifi Protect.
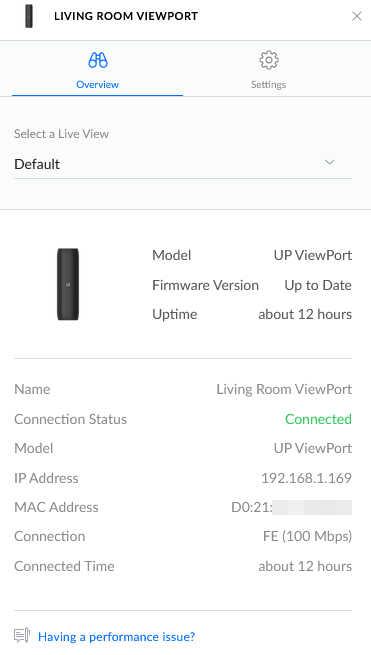
There were no visible lights to indicate the unit was powered on. Meanwhile, the device showed up in the console, with the following settings:
Unifi Protect settings
As you can see from the above, the “Select a Live View” comes from the Protect web app. I created a second Live view configured for four cameras, dragged the one camera I g=do have to one of the quadrants, and then could update the Viewport to instantly show the alternate 4 quadrant view.
The end result, on an 80″ TV looks like this:
Viewport displaying on a TV
I left the unit streaming to the TV for several hours, and it didn’t miss a beat. I could feel a little warmth from the Viewport, but not enough that I would be alarmed.
If I were running a larger security setup, I could imagine having several large TVs each with their own Viewport, but showing different Live Views (with one showing just he primary camera of interest).
There’s no administrative control that I’ve seen on the Viewport itself. You cant change or select cameras, you cant shuttle/jog the stream forwards or backwards. It seems to do one thing – stream current feeds – and do it reliably (thus far).
The video image was crisp and clear (the above image was when it had changed to night mode). The time stamp in the stop left corner appeared to roll forward smoothly. I couldn’t measure the frame rate, but it seemed pretty good – perhaps 20 fps, maybe 25 fps.