I was reading a post the other day advising AWS customers to consider why they aren’t reaching 100% RI coverage. This triggered me, as 100% coverage is often not a good thing. And yes, now we have Savings Plans for Some Things in AWS, but some places remain with Reservations as the way to get consumption discounts by trading on flexibility.
And it’s that trade on flexibility that is critical.
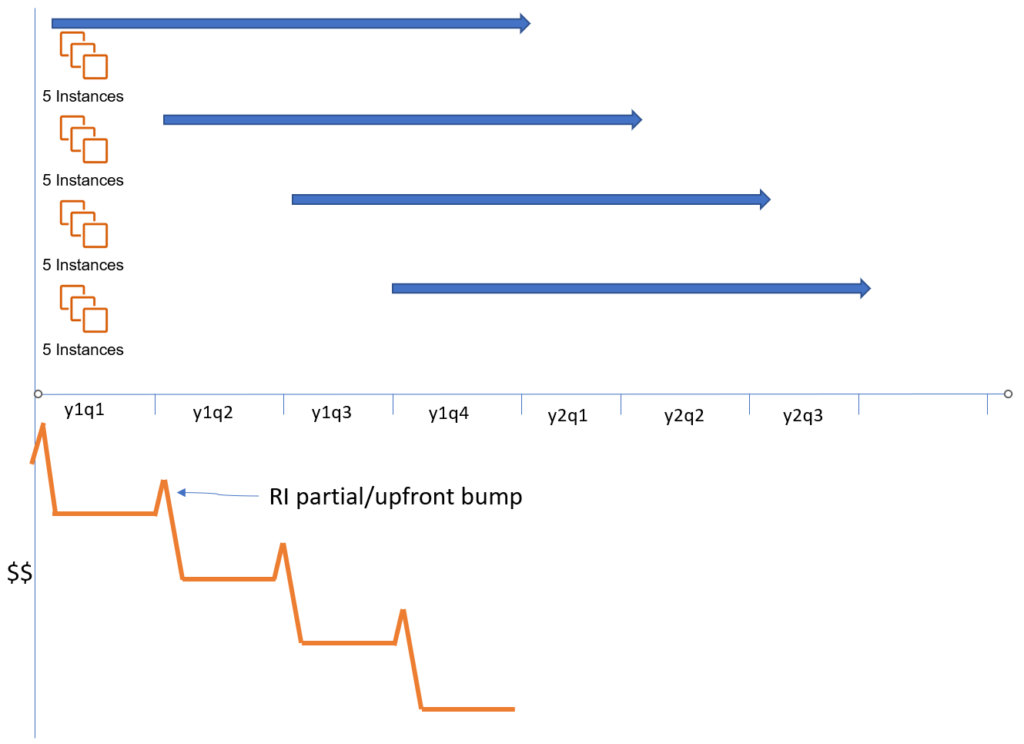
1 year versus 3 years
First off, 3 years versus 1 year; the difference in percentage discount is often negligible, sometimes as low as 1% – 2%. Whereas, over the difference (years 2 and 3), there is the distinct possibility that a new instance type may come out, offering better power, performance, or price. That price improvement point has historically been seen as around 15%, which makes for an ideal time to “roll forward”, if you can. Reservations don’t technically STOP you from doing this, but if you’re not using the capacity you reserved then you may find your still paying for what you no longer use.
Rolling forward on services like RDS is not a problem; as the customer, you’re not managing the OS in the Virtual Machine or Container that its running in.
But in the EC2 world, you may find that your Linux or Windows OS needs an update to support the newer instance family. This was the case ones with RedHat 7.x and the change from m3 to m4; an updated Linux kernel was required. You were fortunate if you were on RedHat Enterprise Linux >=7, as this was when in-place upgrades were introduced — not that this is the recommended DevOps path (rip and replace the instance is my preference).
In-place upgrades made this something that could get you out of a lot of re-engineering if a workload was not already designed with rolling updates and instance replacement in mind. Revolutionary as this was for Redhat 7 GA in 2014, but (as a Debian Developer) Debian’s been doing that since 1996.
Reservations in Waves
The next thing to look at is slicing your reservations into waves, to give you future flexibility.
Typically a partial or full up front payment for your reservation is going to give you the biggest discount, but at the cost of hitting your cash flow now. If you had 20 Reservations required, then you’d be tempted to acquire all of them immediately.
But wait, what happens if you change your mind for some of that workload now, or in 3 months time. And sinking all that capital now may be undesirable.
I’d strongly suggest slicing this into quarterly reservations (each at one year’s duration, as above), picking up (at most) a quarter of your fleet each time. This will, in future, give you a quarterly opportunity to adjust your coverage mix.
And while I say at most a quarter of the fleet; you may still want some flexibility to scale down a little, so perhaps your target is not continual 100% coverage, but continual 80% coverage.
This discussion is then a risk conversation, of making commitments you may want to adjust. And knowing the way you may want to adjust is something that is learnt through experience.
At each quarter, there is a smaller bump for the upfront or partial up front payment, but each of those bumps is now (and in future) a decision point.
RIs applied over time.
This financial operating model may not fit your risk/reward requirements, but its worth considering your approach to long term discounts, and the flexibility you may want in future.
Today was the day that Amzon CloudFront, the global Content Delivery Network (CDN) service, made HTTP/3 optionally available. This is something we’ve been anticipating for some time, and the result, thus far, is a seamless acceleration of delivery.
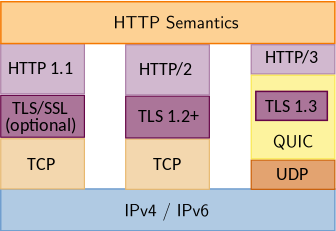
HTTP has been around for almost 30 years. It works with other protocols such as encryption (Transport Layer Security, or TLS), and network (Internet Protocol, or IP) to request Objects (documents, images, data) from a Server.
With HTTP 1.0 (and 0.9) clients would connect to a server, request a single object and then disconnect. They would then read the content they had, and realise they needed a second object (like an image), and then repeat the process. When this was unencrypted HTTP, this was typically done by connecting using the Transmission Control Protocol (TCP) over the Internet Protocol (IP), using a hostname and port number. The convention was to use TCP port 80 for your web server, and you could make a plain-text (unencrypted) connection using telnet and just type your request: “GET / HTTP/1.0\n\n”. Note the backslash-n is actually carriage return, two in a row, which indicated the end of the request.
Over time, additional options were added to the request (before the double carriage-return), such as cookies, client User Agent strings, and so on.
Then, with the dawn of Netscape Navigator came public key encryption in the browser, and the opportunity to encrypt data over the untrusted Internet with some degree of privacy and identity. However, the encryption was negotiated first, before the client had made any HTTP request, so a new endpoint had to be deployed that specifically was ready to start encryption, before eventually talking the HTTP protocol. A new TCP port was needed, and 443 was assigned.
Now we have two conversations happening: the negotiation of encryption, and then separately, the request and response of web content. Both conversations have changed over time.
Encryption Improvements
The encryption conversation started as Secure Socket Layer (SSL) version 2 (v1 never saw the light of day). This was replaced with SSLv3, and then standardised and renamed to Transport Layer Security (TLS) 1.0; TLS 1.0 was improved upon for version 1.1, and then version 1.2, and today we have TLS version 1.3 – and those older versions have mostly been deemed to be no longer reliable/safe to use. TLS 1.2 and 1.3 are all that seen today, and we’ll likely see 1.2 disappear at some stage. TLS 1.3 is slightly faster, in that there can be one (sometimes two) less round-trips to establish the encrypted connection. And less found trips = faster.
HTTP Improvements
So the first improvement here was the slight bump to HTTP 1.1, where by the client could request an Object, but ask the server to hold the link open, and after sending the requested Object, be ready for another request. This was called HTTP keep-alive, and it was good. Well, better than shutting down a perfectly good connection only open another one up.
But then came resources which would potentially block. If I request 6 items in series, and item number 2 takes some time to be processed and returned, then it may block items 3, 4, 5 and 6 (they’re all in a single line of request and response).
HTTP/2 fixed this, by permitting the client to ask for multiple Objects simultaneously, not one after the other. It also headers in the request to be compressed (as they were getting to be quite large), and it switched up the conversation form plain text, to binary.
The response from the server was binary simultaneous streams of Objects in parallel.
This fixed the speed issue of blocking caused by slow objects, and while it was faster, but it started to uncover a the next bottle neck; packet loss and retransmission of packets over the Internet. This was done by the TCP layer – it implements buffers and handles retransmissions, but in the strict OSI layer mode of networking, those retransmissions were transparent to the higher level protocols.
In order to handle this better, the QUIC protocol had to abandon the safety-net of TCP’s implementation of packet loss, and revert to the more basic UDP approach, and implement more intelligent retransmissions that could understand which concurrent stream(s) were impacted by a packet drop.
This fusing of QUIC and TLS with HTTP gives us HTTP/3. QUIC itself has its own IETFWorking Group, and in future we could see other uses for QUIC.
Finding and using HTTP/3 over UDP
Now we know why the move from TCP to UDP, we look at how this works. With previous versions of HTTP, the location was easy; a scheme, hostname and a port number: https, blog.james.rcpt.to, and 443. Because we said https, we can assume that if no port number is specified, then its probably the assigned default 443. But QUIC and HTTP/3 doesn’t have an assigned UDP port (at this time). Its any available port the administrator wishes to use.
So how does a browser know what to connect to?
Turns out this is an header that the current HTTP/2 (over TCP) service has configured called “alt-svc“. So any current browser that makes its default https over TCP to a web server asks for its first object, and in response, it gets told something like:
h3=":443"; ma=86400
Indeed, I’ve just lifted this from CloudFront today. It’s telling the client that for h3 (HTTP/3) endpoint, to connect to the same hostname on UDP port 443 (what a coincidence!). It’s also saying the Maximum Age (MA) to remember this Alternate Service endpoint is one day, or 86,400 seconds.
Using Google Chrome browser, with the Developer tools open to the Network tab, when I visit an H3 capable website for the first time I see this:
Network traffic in Google Chrome Developer tools
We saw the initial protocol was an HTTP/2, but the request for the style.css object was done over HTTP/3.
The Max Age is currently not configurable by CloudFront customers, and may indeed change over time.
Network Firewalls and Proxies
Many enterprises have network firewalls that only permit certain traffic and protocols. Some organisations deploy internal proxies that intercept their staff web traffic and inspect it to remove malware and viruses from being downloaded. In both these scenarios you may hit restrictions that inhibit HTTP 3, but luckily, browsers are smart enough to silently revert to the existing HTTP/2 protocol on trusty TCP.
As UDP is not commonly used in organisations over the Internet, the chances are this is already blocked. As UDP doesn’t have a standardised port number, there’s no easy fix: its not as easy as saying “just unblock egress UDP port 443”. Even then you may want some introspection then to ensure the traffic going in/out is QUIC/HTTP 3 and is encrypted. But this could be any UDP port. I hope that 443 becomes a pseudo standard.
Network proxies, which could also benefit from the speed improvements, will need to be updated. But this was already an issue – any intercepting proxy that doesn’t support HTTP/2 is already out of date and slowing you down.
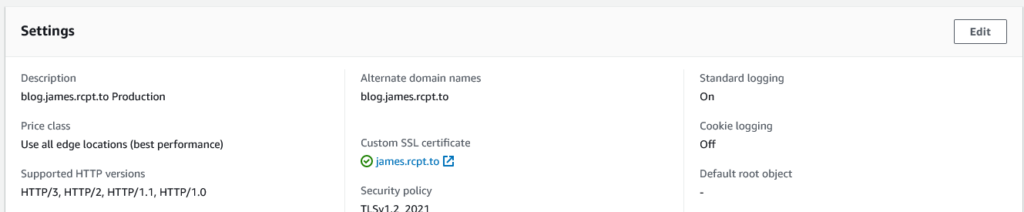
Configuring CloudFront
You’ll find a slight tweak to the CloudFront distribution console, which now can show this:
HTTP/3 (and indeed 2) are not enabled by default at this time, but there’s few reasons not to enable them. There’s nothing else to set, just tick the box.
Summary
Thus far I haven’t seen any issues from clients trying to browse a number of CloudFront Distributions that I help administrate. I recommend testing this in your non-production environments and see what issues you see. You’ll also want to check in with CaniUse.com to see if you can use HTTP/3 for some of your modern clients.
Some other tools may not yet be ready to do inspection of HTTP/3 endpoints, like various web page speed tests, or my other favourites, SecurityHeaders.com, SSLLabs.com, and Hardenize.com.
If you see websites are suddenly faster, you may find its because QUIC just became available to them. If you have use cases where milliseconds of speed improvements are critical, then this may be for you.
To be fair, Fastly (hi Arthur!) and CloudFlare has supported HTTP/3 for some time. Even Akamai has HTTP/3 available in beta to some customers.
This blog is using CloudFront, and there’s a chance that some of your requests you just did here are over HTTP/3. The origin server supports HTTP/2 over TCP, but that’s separate to the connection that your browser made to the CloudFront edge closest to you.
Congratulations to the CloudFront service team on this release. It appears this has been smooth, seamless, doesn’t cost customers any more for optimal delivery. There’s nothing not to like!
Postscript: IPv6 on CloudFront
HTTP/3 also works over IPv6, but check you have taken the TWO steps to enable it; in the CloudFront distribution, enable IPv6 (either via the API, in your CloudFormation template, or in the Web Console), AND ensure you have a DNS record of type AAAA that lets clients find the IPv6 endpoint for your distribution. If you use Route53 as your DNS service, look for the Alias record option for AAAA, with the name of the record equal to the desired hostname (and check you have a corresponding TLS Certificate with that hostname, possibly from Amazon Certificate Manager for free!).
In July of 2022, Amazon started to offer some customers the option of a free, physical Multi-Factor Authentication token to help secure AWS Accounts. And (at the time of writing) this is a FIDO2 Multi Factor Authentication (MFA) device.
This is a fantastic step forward.
MFA support for AWS IAM wasintroduced in 2009. Its expanded capability over time included Gemalto key fob devices (off-line, pre-seeded) , SMS text message (with caveats and warnings on using SMS for MFA), and FIDO 2 based devices.
The of-fline key fobs suffered from a few small flaws:
The battery would go flat after some time.
There was no time synchronisation, and time drift would happen to the point of not being able to be corrected if not used for extended periods of time (weeks, months, years).
The SMS approach was fraught with danger due to unauthorised mobile phone subscription take over – whereby someone walks into the retail store and convinces a young assistant that they’ve lost their phone and gets them to vend a replacement SIM card with your number, amongst other approaches.
In 2015, when there was just one AWS training course that wasn’t pre-sales free, Architecting on AWS, I was offering advanced security and operations training on AWS under my training brand, Nephology. Luckily the state of education (and certification) has expanded greatly from AWS (and others), and I no longer need to fill this gap — and my day job has become so busy I don’t get the time (despite missing out on the additional income).
At that time, FIDO2 was not supported by the AWS API and Console.
And thus, every student of Nephology for our AWS Security course from 2015 until I finished delivering my education around 2018, received from me a Gemalto MFA to help secure their master (root) credentials of their primary AWS account. My training also included actually helping enabling the MFA, and the full lifecycle of disabling and re-establishing MFA, as well as what to do when the MFA breaks, is lost, goes flat, or looses time sync.
It was a key enabler, in real terms, to help customers secure their environments better. And clearly, I was 7 years ahead of my time, with AWS now, in limited terms, making a similar offer to some of its customers.
Its amazing today to see the capability usefulness of FIDO2 devices for MFA, and I’ve long since deprecated the physical key fobs in favour of this. So long as the MFA device can be plugged in (USB3, USBC) or connected to (NFC, etc) then they’ll continue to be effective.
The flexibility of being able to use the same FIDO2 MFA device with multiple other services, outside of AWS, means it helps the general security for the individual. No one wants 20 physical MFAs; this really is the one (key) ring to rule them.
I first used a physical VoIP phone when I was living in London, in 2003. It was made by Grandstream, was corded, and registered to a SIP provider in Australia (Simtex, whom I think on longer exist).
It was rock solid. Family and friends in Australia would call our local Perth telephone number, and we’d pick up the ringing phone in London. Calls were untimed, no B-party charging, and calls could last for hours without fear of the cost.
The flexibility of voice over internet was fantastic. At work, I had hard phones in colo cages and office spaces from San Francisco, to New York, Hamburg and London, avoiding international roaming charges completely.
The move to Siemens Gigaset
Sometime around 2008/2009, I swapped the Grandstream set for a Siemens Gigaset DECT wireless system: a VoIP base station, and a set of cordless handsets that used the familiar and reliable DECT protocol. The charging cradle for handsets only required power, meaning the base station could be conveniently stashed right beside the home router – typically with DSL where the phone line was terminated.
It was fantastic; multiple handsets, and the ability to host two simultaneous, independent (parallel) phone calls. In any household, not having to argue for who was hogging the phone, and missed inbound calls was awesome. And those two simultaneous calls were from either the same SIP registration or up to 6 SIP registrations.
Fast forward to 2022, and I still use the exact, same system, some 13 years later. I’ve added additional handsets. I’ve switched calling providers (twice). Yes, we have mobile phones, but sadly, being 8,140 meters from the Perth CBD is too far for my cell phone carrier (Singtel Optus) to have reliable indoor coverage. Yes, I could switch to Telstra, for 3x the price, and 1/3 the data allowance per month (but at least I’d get working mobile IPv6 then).
Gigaset has changed hands a few times, and while I’ve looked at many competitors over the years, I haven’t found any that have wrapped up the multi-DECT handset, answer phone, VOIP capability as well.
Yes, there are some rubbish features. I do not need my star sign displayed on the phone. Gigaset themselves as a SIP registrar has been unnecessary for me (YMMV).
And there are some milder frustrations; like each handset having its own address book, and a clunky Bluetooth sync & import to a laptop, or each handset having its own history of calls made. And, no IPv6 SIP registration.
What they haven’t done (that I have found) is make it clear which model is newer, and which models are superseded. Indeed, just discovering some of the models of base station in the domestic consumer range is difficult.
So the base station: which model is current? A Go Box 100? N 300? Comfort A IP flex? N300? Try finding the N300 on the gigset.com web site!
Can I easily compare base station capabilities/differneces without comparing the handsets – no!
I am looking for a base station that now supports IPv6, and possibly three simultaneous calls (two is good, but three would be better).
I keep returning to gigaset.com to hope they have improved the way they present their product line up, but alas, after 5 years or looking, it’s not got any better. It’s a great product, fantastic engineering, let down by confusing messaging and sales. At least put the release year in the tech spec so we can deduce what is older and what is newer, for both handsets and base station.
I feel that if Gigaset made their procurement of base station and handsets clearer they’d sell far more.
I try and stay as up-to-date with all things Cloud, and have done for the better part of a decade and a bit. But I recently came across a social media post entitled “Is it safe to move to the cloud?“, and with this much experience, I had so many immediate thoughts, that this post thus precipitated.
My immediate reaction was “Is it safe to NOT move to The Cloud?“, but then I thought about the underlying problems with all digital solutions. And the key issue is understanding TCO, and ensuring the right cost is being endured over the operating time of the solution, rather than the least cost as is so typical.
The truth is that with digital systems, things change all the time. And if those systems are facing untrusted networks (such as the Internet), or processing untrusted data (such as came from humans) then there are issues lurking.
Let me take a moment to point out, as an example, any Java implementation that used the very popular Log4J library to handle error messages. Last December (2021) a serious vulnerability arose that meant that if you logged a certain message, then it would trigger an issue. Quite often error messages being raised include the offending input that failed validation or caused an exception, and thus, you could have untrusted data triggering a vulnerability via this (wildly popular and heavily used) library.
It’s not that anyone had done anything bad on purpose. No one had spotted it (and reported it to the developer of the library) earlier.
Of course, the correct thing happened: an updated version of this library was released. And then other vendors of solutions updated their products that included this newer version of the Log4J library. And then your operations team updated your deployment of this application.
Or did they.
There’s a phrase that fills me with fear in IT operations: “Transition to Support“. It indicates we’re punting the operational responsibility of the solution to a team that a did not build it, and do not now how to make major changes to the application. We’re sending to to a team that already look after other digital solutions, and adding one more thing to their work for them to check is operational, and for them to maintain — which, as they are often overwhelmed with multiple solutions, they do the simplest thing: check it is operational, not that it is Well Maintained.
Transition to support: the death knell for Well-Maintained systems
James Bromberger
I’ve seen first hand that critical enterprise systems, line-of-business processing that is the core of the business, is best served when the smart people who built it, stay to operate it in a DevOps approach. This team can make the major surgical changes that happen after deployment, and as business conditions and cyber threats change.
The concern here is cost. Development teams cost more than dumping large numbers of systems on under staffed Support teams. Or support gets sent offshore to external providers who may spend 30 seconds checking the system works, but no time investigating the error messages and their resolution that may require a software update.
It’s a question of cost.
A short-term CIO makes their hero status by cutting costs. Immediately this has only a positive impact on the balance sheet. But as time goes on, the risks of poor maintenance goes up. But after the financial year has ended, and short term EBITDA shows massive growth, and a heroes party is given for the CIO, they then miraculously depart for another job based on the short term success.
Next up, the original company finds that their digital solution needs to be updated, but there is no one who understands it to make such a change.
The smart people were let go of. They were seen as a cost, not part of the business.
So lets rephrase the question: “Is it safe to move to the cloud with your current IT management and maintenance approach?” Possibly not: you probably have to modify the way you do a lot of things, including how you structure your teams and Org Unit. You may need to up-weight training for teams who will now take on full responsibility for workloads, instead of just being “the network guy”. But this is an opportunity; those teams can now feel that THEY are the service team for a workload that supports something more substantial than just rack-and-stack of storage. Moving to separate DevOps teams per critical workload, you can then have them independently innovate – but collaborate on standards and improvements. a friendly competition on addressing technical debt, or number of user feature improvements requested – and satisfied.
So is it safe to move to the Cloud? It depends on who is doing, how much knowledge and experience they have, and what happens next in your operating model.
The Cloud is not just another data centre. And TCO isn’t just cloud costs, and it isn’t just people cost. Sometimes the cost is the compliance failure and fine you get by inadvertently removing the operating model that would have prevented a data breach.
Its been 7 years since I (and my colleagues at Ajilon/Modis, soon to be Akkodis) moved the Land Registry of Western Australia, the critical government registry of property ownership of the state, into the AWS Cloud for Landgate. We’ve kept a DevOps approach for the solution – ensuring it was not just Well-Architected, but Well Maintained. It’s a small DevOps crew now that ensure that Java Updates, 3rd party library updates and more get imported, but also maintenance of the Cloud environment such as load balancing, virtual machine types & images (AMIs) get updated, managed relational database versions get updated, newer TLS versions get supported and — more importantly — older versions get deprecated and disabled. FinOps, DevOps, and collaboration.