As any arbitrary point in time, the start of a new year is as good as any to do those activities which ideally are done regularly, but often only happen annually. Like checking the batteries in your smoke detectors, there’s a set of really trivial steps that anyone with any online technology interface can, and should do.
Check back with online services you use and see if they now support Multi-Factor Authentication (MFA); enable it if they do. MFA comes in multiple types, from an SMS to your mobile, an automated telephone call, an app installed on your phone that generates a unique code every 30 seconds, and offline hardware devices such as a Yubikey (FIDO2).
Uninstall programs you no longer use. On Windows, go to Add or Remove Programs and review the entries. On Debian and similar, “dpkg –get-selections |grep installed“
Update those programs you do use, from verified authoritative sources. In particular if you have a Password Manager (take a backup first!), web browser, email client.
Ensure all OS patches are installed. Your OS should have support for this, but some patches may be held back.
Update the firmware on your home WiFi router. If your ISP provided you with the router, then ask them for the updates and how to apply them. If there are no updates for the last 4 years (eg: since the WAP2 Krack attacks), then go buy a new one that will come with firmware updates from the manufacturer.
Update the firmwares on your printers, network security cameras, desk phones and any other devices you have.
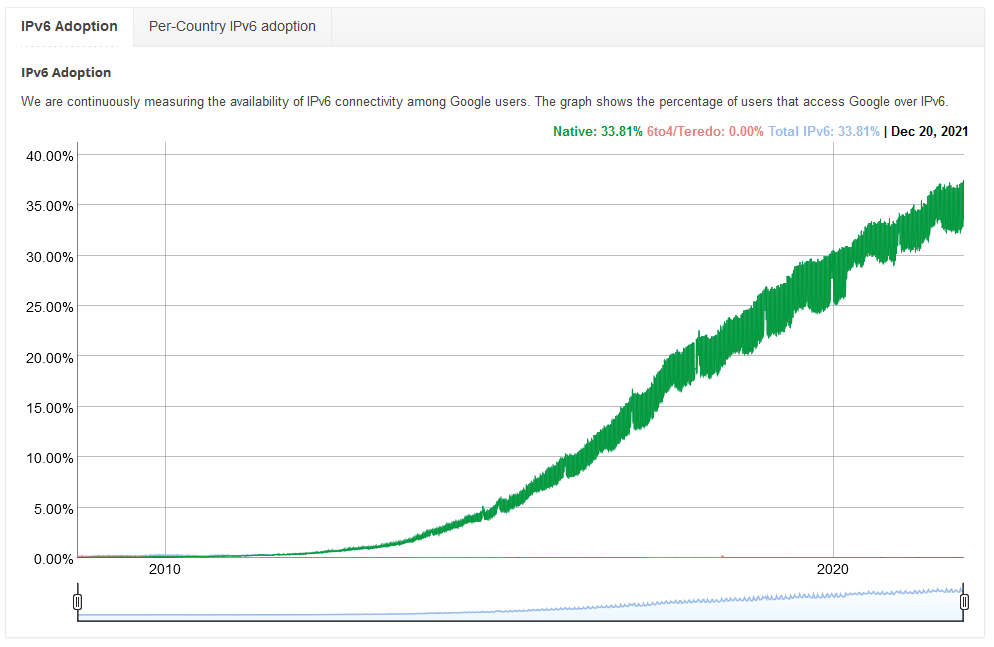
As we round out another year, here’s a perspective on where we are up to on the IPv6 transition that has been going for 20 years, but now gathering momentum.
With around 33% of traffic being IPv6, its reasonably significant on a global level. The country-by-country map shows the US on 47%, Germany at 55%, UK on 34%, and Australia at 27%. We’re fast reaching the tipping point where IPv6 is the expected traffic type.
Clearly, the biggest factor is going to be the destination services that people (and systems) want to get to offering IPv6, and then the client (users) having IPv6 available to then send that traffic.
In Australia, the dominant cell phone provider, Telstra, has been using IPv6 for its consumer business since 2016. Now, five and a half years later, we’re still waiting for Optus (Singtel), Vodafone, and many more to pick up.
For ISPs: iiNet continues to show no innovation since the engineering talent departed in the post TPG acquisition. Aussie Broadband (whom I churned to) still call their IPv6 offering a beta, but its been very stable for me now for… years. Perhaps time to take the beta label off?
IPv6 on the Cloud
AWS made many IPv6 announcements through pre-Invent and re:invent (the annual AWS Cloud summit/conference).
Many key services already had 1st class dual-stack support for IPv6 along side IPv4. Key amongst this is Route53, serving DNS responses on either transport layer.
Now we’re seeing IPv6 only capability, as IPv4 starts to look more and more like a legacy transport protocol.
With that perspective, its a shame to see how many of the trusted brands back on the commercial ISP and Mobile carrier market just aren’t up to speed. No engineering investment to really modernise.
AWS VPC: IPv6 only subnets
When defining a VPC, one of the most durable configurations is the IPv4 CIDR range assigned. Once allocated, its set. You can add one more IPv4 allocation if you must, in a separate range, with all kinds of complications.
Since 2016 AWS has permitted an IPv6 network allocation to dual-stack subnets in a VPC, and to allocate to an EC2 instance. Traffic within the VPC was still primarily IPv4 – for services like RDS (databases), etc. Slowly we’ve seen Load Balancers become dual-stack, which is one of the most useful pieces for building customer/internet facing dual-stack, but then fall back to IPv4 on the private side of the load balancer.
The IPv6 in subnets had an interesting feature. Initially the address allocation was only, but now you can BYO, however, the subnet size is always /56, some 18 quintillion IP addresses. Compare with IPv4, where you can make subnets from /28 (14 IPs) to /16 (65,533 IPs).
Two common challenges used to appear with IPv4 subnets: one, you ran out of addresses, especially in public subnets with multiple ALBs of variable traffic pattern peaks, and two: a new Availability Zone launch, and the contiguous address space needs some consistency to meet with traditional on-premises (internal) firewalling.
Now, you only have the one consideration: contiguous address space, but you’re unlikely to exhaust a subnet’s IPv6 address allocation.
When ap-southeast-2 launched, I loved having two Availability zones, and in the traditional IPv4 address space, I would allocate a contiguous range for each purpose across AZs equally. For example:
Purpose
AZ A
AZ B
Supernet
Public
10.0.0.0/24
10.0.1.0/24
10.0.0.0/23
Apps (Private)
10.0.2.0/24
10.0.3.0/24
10.0.2.0/23
Databases (Private)
10.0.4.0/24
10.0.5.0/24
10.0.4.0/23
Contiguous address space across two AZs
From the above, you can see I can summarise up the two allocations for each purpose, the one in AZ A and AZ B, into one range.
Now for various points I wont dive into her, having TWO AZs is great, but having three is better. However, address space is binary and works in powers of two the purpose of subnetting and supernetting, so if I wanted to preserve contiguous address space, then I would have kept the 10.0.2.0/24 reserved for the AZ C, and then have a left over /24 (10.0.3.0/24) in order to make a larger supernet of 10.0.0.0/22 to cover all Public Subnets:
Purpose
AZ A
AZ B
AZ C
Reserved
Supernet
Public
10.0.0.0/24
10.0.1.0/24
10.0.2.0/24
10.0.3.0/24
10.0.0.0/22
Apps (Private)
10.0.4.0/24
10.0.5.0/24
10.0.6.0/24
10.0.7.0/24
10.0.4.0/22
Databases (Private)
10.0.8.0/24
10.0.9.0/24
10.0.10.0/24
10.0.11.0/24
10.0.8.0/22
Now we’ve split our address space four ways, preserved continuity to be able to subnet, but we had to reallocate the .2 and .3 ranges. What a pain.
Now, we can take VPC subnetting further; the next increment would be provisions for 8 AZs. That’s probably a stretch for most organisations, so 4 seems to be most common.
Now take an IPv6 lens over this, and the only thing you’re looking at keeping contiguous over the IPV6 range is the order of allocation, from :00:, through to :03: for the Public Subnets, and then :04: to :07: for apps, and :08: to :0b: (yes, its hex) for the Databases.
Going backwards from IPv6 toIPv4
Another release at reinvent for VPC was the support for DNS64, and NAT64 on NAT Gateway. On a subnet by subnet basis, you can have the DNS resolver return a specially crafted IPv6 address that actually has an IPv4 embedded in it; when used with NAT64,then NAT Gateway will bridge the traffic going outbound from IPv6 internally, back to IPv4 externally. Now you can adopt modern IPv6 internal topologies, but still reach back into the past for those integrations that haven’t gone dual-stack yet.
Of course, this would be far easier if, for all services you wanted to access, you already had the choice of IPv4 or IPv6. Which, as a service provider, you should be offering to your integration partners already.
Load Balancers end-to-end IPv6
Until recently, when traffic from the Internet hit an ALB or NLB over IPv6, it would drop down to IPv4 for the internal connection; however that changed during reinvent with end-to-end IPv6. Virtual Machines (EC2 instances) now see the originating IPv6 address in packets.
Summary
Its been 3 years since some of the critical state government projects I was working on went dual stack in AWS. I encourage my teams to present dual-stack external interfaces, and to prepare all customer environment for this switch over as part of their managed services and professional services deployments. Its not complicated, it doesn’t add any cost, and it can be a competitive advantage. Its another example of a sunrise and sunset of yet another digital standard, and it wont be the last.
There’s a great XKCD cartoon entitled Depencency that cuts to the heart of today’s software engineering world: developers (and in turn organisations) everywhere love the use of libraries to accelerate their development efforts, particularly if that library of code is free to use, and typically that’s Open Source Free.
The image speaks about large complex systems, critical to organisations, needing the unpaid, thankless contributors of these libraries but upon whom everything relies.
In the last week, we’ve seen Log4J, a Java logging utility, come under such focus due to a critical remote code execution bug that can see the server side triggered to make outbound requests. A vast amount of Java based solutions for the last 15+ years has dependencies on logging messages being implemented using this library.
Java is widely used, as Oracle corporation points out clearly:
3 Billion Devices Run Java – Oracle
There’s two sides to this: invalid requests coming in that should be handled with sensible data validation, and the resulting external requests that servers can be tricked into making.
Now I am not saying everyone should use their own logging library; that would be even more on fire. But we should stand ready to update these things rapidly, and we should help with either code contributions or financial donations (or both) to help improve this for the common good.
Untrusted Data Validation
Validating untrusted data sources is critical. The content of a local configuration file is vastly different from the query from the Internet. I’ve often joked about setting my Browser user-agent string to the EICAR test file content, used as a dummy value to trigger Antivirus software to match on this text.
In this case, we have remote attackers stuffing custom generated data strings in HTTP requests (and email and other sources that accept external traffic/data) to try and trick the Log4j library into processing and interpreting this data instead of just writing it to a log file.
Web servers always accept data from the Internet, and Web Application Firewalls can offer some protection, but in this case, the actual “string to check” can be escaped, making it harder to write simple rules that match.
Restricting outbound traffic
An attacker is often trying to get a better access into the systems they target; their initial foothold may be tentative. In this example, the ability to trick a target server to fetch additional data (payload) from an external service is key. There’s two main types of external data egress: direct, and indirect.
In the direct model, your server, which you installed and thus trust, may be running behind a firewall, but have you checked if you have restrictions on what it can fetch directly from the Internet?
In AWS, the default AWS Security Group for egress is to permit all traffic; this is a terrible idea, but is the element of least surprise for those new to the AWS VPC environment. It is strongly recommended that you pair this down for all applications, to end up with only the minimum network access you need, even when behind a (managed) NAT Gateway or routing rules, and even if you think your server only has internal network access.
I wrote a whitepaper on this topic for Modis in 2019 about Lateral Movement within the AWS VPC, and some of the concepts there are relevant now.
Your VPC-deployed virtual machine instance probably only needs to initiate connections to S3 on 443, and its database server on the local CIDR (address) range. For example, if you have three Subnets for databases:
10.0.0.0/26 (Databases in AZ-A)
10.0.0.64/26 (Databases in AZ-B)
10.0.0.128/26 (Databases in AZ-C)
10.0.0.196/26 (reserved for future expansion of Databases in a yet-to-be announced AZ-D)
… and are running MySQL (eg, RDS MySQL) in those AZs, then you probably want an egress rule on your Application Server/instance of 10.0.0.0/24:3306. (Note, be ready for making this all IPv6 in future). However, your inbound rule on the same group is probably referential to your managed Load Balancer, on port 443.
What about DNS and Time Sync?
If you have cut down your egress to just the two rules (HTTPS for S3 to bootstrap, CFN-init to signal ASG creation, and database traffic), what about things like DNS and Time. These are typically UDP based (ports 53, 123).
Indeed, the typical DNS firewall used for NTP, when syncing from external time services, is *:123 inbound and *:123 outbound. Ouch.
AWS Time Sync Service
The good news is you do not need to permit this in your security group rules IF you are using the AWS VPC provided Time Sync service and DNS Resolvers. These are available over the link-local network, and security groups do not restrict this traffic; hence can be left closed for UDP port 123.
This time service is also scalable; you don’t need to have thousands of hosts pointing at one or two of your own NTP servers; the AWS Time Sync service runs from the hyper-visor, so as you randomly add instances, you have more physical nodes (droplets) involved in provisioning this, so your time services scale.
Managed & Scalable DNS Resolution
DNS can be used for data exfiltration. If you run your own DNS resolver (eg, on a Windows Domain Controller(s) or Linux host(s) and set your DHCP to hand this resolver address to clients, then you may be at risk of not even seeing this happen. This is an indirect way of being exploited; your end server may not have access to egress to the Internet, but it can egress to your DNS resolver to… well, look up addresses. If you do run your own DNS server, you should be looking at the log of what is being looked up, and managing the process to match this against a threat list, and issuing warnings of potential compromise.
Managed DNS Security Checks: Guard Duty
If that’s too much effort, then there is a managed solution for this: AWS Guard Duty and the VPC-provided DNS resolver. In order for Guard Duty to inspect and warn on this traffic, you must be sending DNS queries via the VPC resolver. Turning on Guard Duty while not sending DNS traffic through the AWS provided service – for example, running your own root-resolving DNS server, means the warnings from Guard Duty will probably never trigger.
By contrast, having your self-managed resolver (eg Active Directory server) use the VPC resolver means that it is the one that will be reported upon when any other instance uses it as a resolver with a risky lookup! I’m sue that will be a mild panic.
Managed DNS Proactive Blocking: DNS Firewall
Going beyond simply retrospectively telling you that traffic happened is pro-actively blocking DNS traffic. Route53 DNS Firewall was introduced in 2021, using managed block lists for malicious domains. This gives some level of protection that clients (instances) will get a failed DNS lookup when trying to resolve these bad domains.
My Recommendations
So here’s the approach I tell my teams when using VPCs:
Always use the link-local time Sync service; it scales, and reduces SPOFs and bad firewall rules.
Always use the link-local DNS resolver; it scales. use a Resolver Rule if you need to then hook the DNS traffic up to your own DNS server (AD Domain Controller).
Turn on Guard Duty, set up notifications of the Findings it generates.
Turn on DNS Firewall to actively BLOCK DNS lookups for bad domains.
Turn on your own Route53 query logs for yourself, with some retention period (90 days?)
For inbound Web traffic, use a managed Web Application Firewall with managed rules, and/or scope your application to the country you’re intending to serve traffic to. In particular, block access to administrative URL paths that don’t come from trusted source ranges.
Leverage any additional managed services that you can, so you minimise the hand-crafted solutions in your application.
Template your workload, and implement updates from template automation; no local changes. Deploy changes rapidly using DevOps principles. Socialiase with your team/management the importance of full stack maintenance and least privilege access — including at the network layer ingress and egress — and schedule and prioritise time to include technical debt in each iteration, including the updating of every third party library in your app.
If you have a DevOps pipeline with something like SonarQube or Whitesource, have it report on dependencies (libraries), and get reports on how out-of-date those libraries are, and/or if those out of date versions have known CVEs against them. Google Lighthouse (in the browser) does a great job of his for JavaScript web frameworks.
For this exploit you need to go widerthat what you run in cloud: your company printer (MFP), network security cameras, VoIP phones, UPS units, air-conditioners, Smart Hubs, TVs, Home Internet Gateways, and other devices will probably have an update. Your games console, and the games on it (this started from an update in Minecraft to address this and has… escalated quickly!). Even the physical on–prem firewalls and virtual appliances themselves – but ensure you don’t just do firewalls and ignore the larger landscape of equipment you have.
As an experiment, I have a CodeCommit repository that has a combination of CloudFormation Templates, and some static web content, checked in to two separate prefixes or folders: /Templates/ and /Website/.
What I am trying to do is, upon any commit to the repo, determine if the Website prefix needs an update, or the Templates have to trigger CFN Stack Update.
Starting with the most basic piece, I want the web content to go via CodePipeline, and unpack into an S3 Bucket, against which there is a CloudFront distribution pointing (with an Origin Access Identity already in place).
By default, an S3 unpack expects the entire repo to unpack into S3, but I want to only have a particular sub folder, so I’ve implemented a “repackage” step as a Lambda function in the pipeline, which grabs the Original Artifact the pipeline has, unpacks it, and then create as new Artifact containing just the folder /Website/ and below. Turned out to be around 50 lines of code in Python:
import json
import boto3
import os
import zipfile
def lambda_handler(event, context):
if (event["CodePipeline.job"]["data"]["inputArtifacts"][0]["location"]["type"] != "S3"):
return { 'statusCode': 500, 'body': json.dumps('Not on S3') }
dl_filename = event["CodePipeline.job"]["data"]["inputArtifacts"][0]["location"]["s3Location"]["objectKey"].split('/')[-1]
s3client = boto3.client('s3',
aws_access_key_id=event["CodePipeline.job"]["data"]["artifactCredentials"]["accessKeyId"],
aws_secret_access_key=event["CodePipeline.job"]["data"]["artifactCredentials"]["secretAccessKey"],
aws_session_token=event["CodePipeline.job"]["data"]["artifactCredentials"]["sessionToken"]
)
with open("/tmp/" + dl_filename, 'wb') as data:
s3client.download_fileobj(
event["CodePipeline.job"]["data"]["inputArtifacts"][0]["location"]["s3Location"]["bucketName"],
event["CodePipeline.job"]["data"]["inputArtifacts"][0]["location"]["s3Location"]["objectKey"],
data)
with zipfile.ZipFile("/tmp/" + dl_filename, 'r') as zip:
zip.extractall('/tmp/')
zip.close()
ul_filename = event["CodePipeline.job"]["data"]["outputArtifacts"][0]["location"]["s3Location"]["objectKey"].split('/')[-1]
zipf = zipfile.ZipFile("/tmp/" + ul_filename, 'w', zipfile.ZIP_DEFLATED)
os.chdir('/tmp/Website/')
for root, dirs, files in os.walk('.'):
for file in files:
zipf.write(os.path.join(root, file))
zipf.close()
#WARNING: CodePipeline artifacts may ave a default BucketPolicy requiring an explict KMS key. Remove that SSE requirement, turn on dfault encryption for the bucket.
s3response=s3client.upload_file(
"/tmp/" + ul_filename,
event["CodePipeline.job"]["data"]["outputArtifacts"][0]["location"]["s3Location"]["bucketName"],
event["CodePipeline.job"]["data"]["outputArtifacts"][0]["location"]["s3Location"]["objectKey"],
ExtraArgs={"ServerSideEncryption": "AES256"}
)
client_cp = boto3.client('codepipeline')
response_cp = client_cp.put_job_success_result(jobId=event["CodePipeline.job"][ "id"])
return {
'statusCode': 200,
'body': json.dumps('Done repacking.')
}
This runs reasonably quickly, and means I am not unpacking the entire CodeCommit repo into my CloudFront distribution.
I’ve been tracking my blog posts and other “contributions” to the AWS developer community since 2017 when the program was originally called the AWS Cloud Warrior Program. This morphed into the Partner Ambassador program, for the top engineering talent in the partner community, and then became a global program.
You can find the ambassadors here. At the time of writing (Nov 1 2021), three are 227 people listed: 114 in APAC, 43 in Europe, 9 in LATAM, and 46 in North America.
I submitted some 28 items to the program in 2021 (until mid-October 2021), from Blog Posts to Case Studies, Open Source work, Event Hosting, and Certification Subject Matter Expert contributions.
This was enough to land me in the #2 position for 2021, as shared during the online Global Ambassador Summit recently – shown in this slide:
And while I sit here with 9 (of 11) AWS certifications (more set to launch during re:Invent), I don’t yet hold the coveted Gold Jacket for holding all available cert (which looks as loud and proud as you can imagine; I think I saw something similar in The Hangover movie).
Arjen and Ian are both amazing engineers; I am honoured to be considered amongst them in this program.
Sharing ideas and solutions has been core to my work in the technology field since I was at University when I first discovered open-source and then became a Debian Linux Developer. Indeed, as developers (and Sys Admins, these days deemed as DevOps Engineers) become more senior, sharing and mentoring becomes more of the job.
Occasionally I get feedback from people that my posts have helped them save time and find a solution quickly, or avoid problems. Often I find myself reading back my own posts years later, thanking younger-me for putting some notes online.
But as with most in this industry, we stand on the shoulders of others; the only right thing to do is to support those coming after us.