Today was the day that Amzon CloudFront, the global Content Delivery Network (CDN) service, made HTTP/3 optionally available. This is something we’ve been anticipating for some time, and the result, thus far, is a seamless acceleration of delivery.
HTTP has been around for almost 30 years. It works with other protocols such as encryption (Transport Layer Security, or TLS), and network (Internet Protocol, or IP) to request Objects (documents, images, data) from a Server.
With HTTP 1.0 (and 0.9) clients would connect to a server, request a single object and then disconnect. They would then read the content they had, and realise they needed a second object (like an image), and then repeat the process. When this was unencrypted HTTP, this was typically done by connecting using the Transmission Control Protocol (TCP) over the Internet Protocol (IP), using a hostname and port number. The convention was to use TCP port 80 for your web server, and you could make a plain-text (unencrypted) connection using telnet and just type your request: “GET / HTTP/1.0\n\n”. Note the backslash-n is actually carriage return, two in a row, which indicated the end of the request.
Over time, additional options were added to the request (before the double carriage-return), such as cookies, client User Agent strings, and so on.
Then, with the dawn of Netscape Navigator came public key encryption in the browser, and the opportunity to encrypt data over the untrusted Internet with some degree of privacy and identity. However, the encryption was negotiated first, before the client had made any HTTP request, so a new endpoint had to be deployed that specifically was ready to start encryption, before eventually talking the HTTP protocol. A new TCP port was needed, and 443 was assigned.
Now we have two conversations happening: the negotiation of encryption, and then separately, the request and response of web content. Both conversations have changed over time.
Encryption Improvements
The encryption conversation started as Secure Socket Layer (SSL) version 2 (v1 never saw the light of day). This was replaced with SSLv3, and then standardised and renamed to Transport Layer Security (TLS) 1.0; TLS 1.0 was improved upon for version 1.1, and then version 1.2, and today we have TLS version 1.3 – and those older versions have mostly been deemed to be no longer reliable/safe to use. TLS 1.2 and 1.3 are all that seen today, and we’ll likely see 1.2 disappear at some stage. TLS 1.3 is slightly faster, in that there can be one (sometimes two) less round-trips to establish the encrypted connection. And less found trips = faster.
HTTP Improvements
So the first improvement here was the slight bump to HTTP 1.1, where by the client could request an Object, but ask the server to hold the link open, and after sending the requested Object, be ready for another request. This was called HTTP keep-alive, and it was good. Well, better than shutting down a perfectly good connection only open another one up.
But then came resources which would potentially block. If I request 6 items in series, and item number 2 takes some time to be processed and returned, then it may block items 3, 4, 5 and 6 (they’re all in a single line of request and response).
HTTP/2 fixed this, by permitting the client to ask for multiple Objects simultaneously, not one after the other. It also headers in the request to be compressed (as they were getting to be quite large), and it switched up the conversation form plain text, to binary.
The response from the server was binary simultaneous streams of Objects in parallel.
This fixed the speed issue of blocking caused by slow objects, and while it was faster, but it started to uncover a the next bottle neck; packet loss and retransmission of packets over the Internet. This was done by the TCP layer – it implements buffers and handles retransmissions, but in the strict OSI layer mode of networking, those retransmissions were transparent to the higher level protocols.
In order to handle this better, the QUIC protocol had to abandon the safety-net of TCP’s implementation of packet loss, and revert to the more basic UDP approach, and implement more intelligent retransmissions that could understand which concurrent stream(s) were impacted by a packet drop.
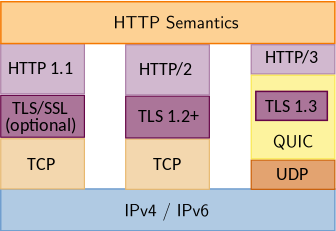
This fusing of QUIC and TLS with HTTP gives us HTTP/3. QUIC itself has its own IETF Working Group, and in future we could see other uses for QUIC.
Finding and using HTTP/3 over UDP
Now we know why the move from TCP to UDP, we look at how this works. With previous versions of HTTP, the location was easy; a scheme, hostname and a port number: https, blog.james.rcpt.to, and 443. Because we said https, we can assume that if no port number is specified, then its probably the assigned default 443. But QUIC and HTTP/3 doesn’t have an assigned UDP port (at this time). Its any available port the administrator wishes to use.
So how does a browser know what to connect to?
Turns out this is an header that the current HTTP/2 (over TCP) service has configured called “alt-svc“. So any current browser that makes its default https over TCP to a web server asks for its first object, and in response, it gets told something like:
h3=":443"; ma=86400Indeed, I’ve just lifted this from CloudFront today. It’s telling the client that for h3 (HTTP/3) endpoint, to connect to the same hostname on UDP port 443 (what a coincidence!). It’s also saying the Maximum Age (MA) to remember this Alternate Service endpoint is one day, or 86,400 seconds.
Using Google Chrome browser, with the Developer tools open to the Network tab, when I visit an H3 capable website for the first time I see this:

We saw the initial protocol was an HTTP/2, but the request for the style.css object was done over HTTP/3.
The Max Age is currently not configurable by CloudFront customers, and may indeed change over time.
Network Firewalls and Proxies
Many enterprises have network firewalls that only permit certain traffic and protocols. Some organisations deploy internal proxies that intercept their staff web traffic and inspect it to remove malware and viruses from being downloaded. In both these scenarios you may hit restrictions that inhibit HTTP 3, but luckily, browsers are smart enough to silently revert to the existing HTTP/2 protocol on trusty TCP.
As UDP is not commonly used in organisations over the Internet, the chances are this is already blocked. As UDP doesn’t have a standardised port number, there’s no easy fix: its not as easy as saying “just unblock egress UDP port 443”. Even then you may want some introspection then to ensure the traffic going in/out is QUIC/HTTP 3 and is encrypted. But this could be any UDP port. I hope that 443 becomes a pseudo standard.
Network proxies, which could also benefit from the speed improvements, will need to be updated. But this was already an issue – any intercepting proxy that doesn’t support HTTP/2 is already out of date and slowing you down.
Configuring CloudFront
You’ll find a slight tweak to the CloudFront distribution console, which now can show this:
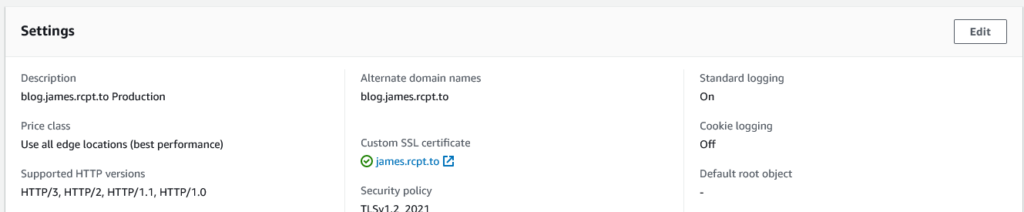
Hitting the Edit button will now show:

You’ll also find support for this in the CloudFormation for a CloudFront Distribution.
HTTP/3 (and indeed 2) are not enabled by default at this time, but there’s few reasons not to enable them. There’s nothing else to set, just tick the box.
Summary
Thus far I haven’t seen any issues from clients trying to browse a number of CloudFront Distributions that I help administrate. I recommend testing this in your non-production environments and see what issues you see. You’ll also want to check in with CaniUse.com to see if you can use HTTP/3 for some of your modern clients.
Some other tools may not yet be ready to do inspection of HTTP/3 endpoints, like various web page speed tests, or my other favourites, SecurityHeaders.com, SSLLabs.com, and Hardenize.com.
If you see websites are suddenly faster, you may find its because QUIC just became available to them. If you have use cases where milliseconds of speed improvements are critical, then this may be for you.
To be fair, Fastly (hi Arthur!) and CloudFlare has supported HTTP/3 for some time. Even Akamai has HTTP/3 available in beta to some customers.
This blog is using CloudFront, and there’s a chance that some of your requests you just did here are over HTTP/3. The origin server supports HTTP/2 over TCP, but that’s separate to the connection that your browser made to the CloudFront edge closest to you.
Congratulations to the CloudFront service team on this release. It appears this has been smooth, seamless, doesn’t cost customers any more for optimal delivery. There’s nothing not to like!
Postscript: IPv6 on CloudFront
HTTP/3 also works over IPv6, but check you have taken the TWO steps to enable it; in the CloudFront distribution, enable IPv6 (either via the API, in your CloudFormation template, or in the Web Console), AND ensure you have a DNS record of type AAAA that lets clients find the IPv6 endpoint for your distribution. If you use Route53 as your DNS service, look for the Alias record option for AAAA, with the name of the record equal to the desired hostname (and check you have a corresponding TLS Certificate with that hostname, possibly from Amazon Certificate Manager for free!).