One thing is sure, these days every political party has a website to publish their message, and right now its one of their key places to disseminate their content from – often reticulating from the web site to the wider broadcast media.
As a source of truth for each party, how well are they implementing modern web security that’s free to implement and use?
I’ve used a number of tools in the past, but I chose just two to do a straw poll to examine them.
The first is Scott Helm’s SecurityHeaders.com. A simple rating A through F gives the general overview of the way the curators of the various sites have activated browser support to help ensure their content – and the visitors to their sites – are as protected as possible.
Scott does a fantastic job of adjusting the ratings over time, as new capabilities are established as commonplace amongst the major web browser platforms. It’s a free service to check any site, publicly available, and you can check your favourite site (such as your employer, or band) right now!
The second services is Qualys’ SSLLabs.com (originally by Ivan Ristic, who now operates hardenize.com – worth a look too). Instead of looking at the simple text headers, SSLLabs looks at the encryption used over the untrusted Internet, and a few other attributes, and again gives an A through F report, so it is easy to understand who does a good job, and who is not quite there yet.
The Australian Labour Party
The ALP lives at https://www.alp.org.au/. Let’s start with the simple security headers rating:
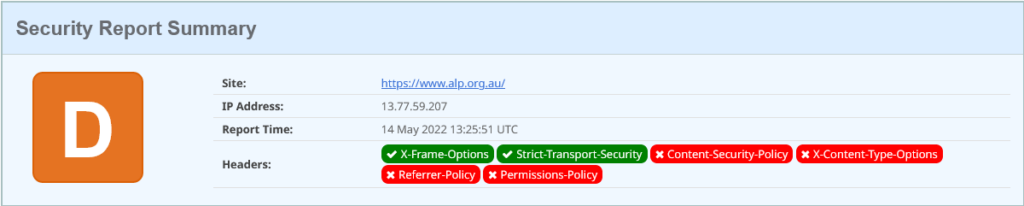
That’ s a pretty poor outing. The first header activated is a legacy security header used to instruct browsers about having content rendered with iframe and frame HTML elements – these days accomplished via a Content Security Policy. Secondly they have indicated to browsers that their site is an HTTPS site and should only ever be contacted using encrypted communications (TLS, or HTTPS), and never over plain-text unencrypted HTTP.
So what?
Content Security Policies (CSPs) are about to become a mandated part of the Payment Card Industry (PCI) Data Security Standard, currently in draft, that any payment page on the Internet (you know, the one you use every day when you buy something online and enter card holder details) will be required to have a CSP to help protect the security of the web page. A CSP doesn’t cost anything, it’s just a text field letting your browser know boundaries from where it can fetch additional content to render the page. And if it’s good enough for a payment page, then its good enough for anything you’re trying to have a strong security reputation on.
OK, let’s move to the TLS (formerly called SSL) strength, with SSLLabs:
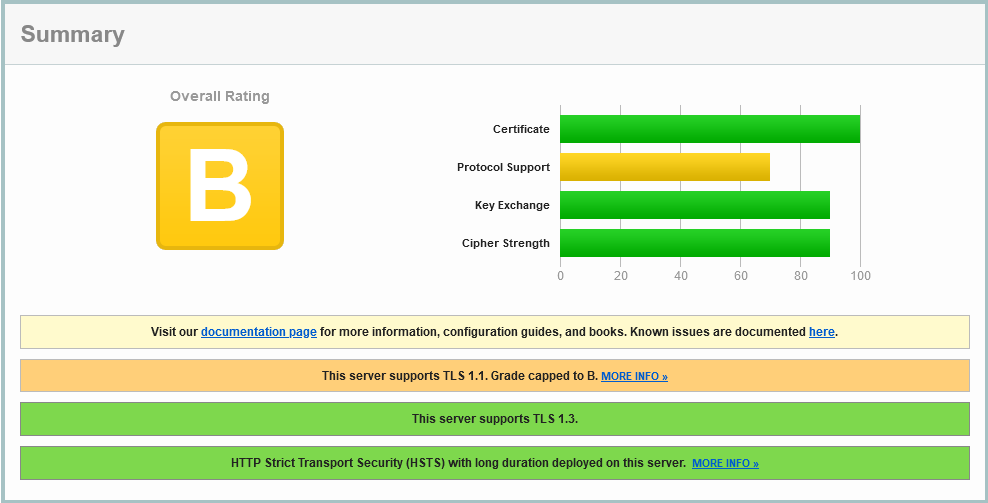
Well, they’ve left the older TLS 1.1 protocol enabled. That’s been deprecated since around 2016, so only 6 years out of date. It’ s nice to see the newest TLS 1.3 is enabled here, and the encryption ciphers are ordered with stronger crypto before weaker ciphers (why are those older ones still enabled, as they are likely ever legitimately used?). The test shows that the more efficient HTTP2 has not been enabled, and the simple Certificate Authority Authorization record in DNS has not been set – which helps declare which Certificate Authorities are permitted to issue the trust certificates for alp.org.au.
We notice that there is just one IPv4 address returned when doing this check which raises a few questions:
- there is no apparent Content Delivery Network in place
- dual-stack support for IPv6 has not been enabled
- there’s possibly only one site for this service to run from?
A traceroute for this appears to disappear into MSN.net in Melbourne.
Liberal Party of Australia
Move to the Liberals who are at https://www.liberal.org.au/. Cranking up Security Headers shows:
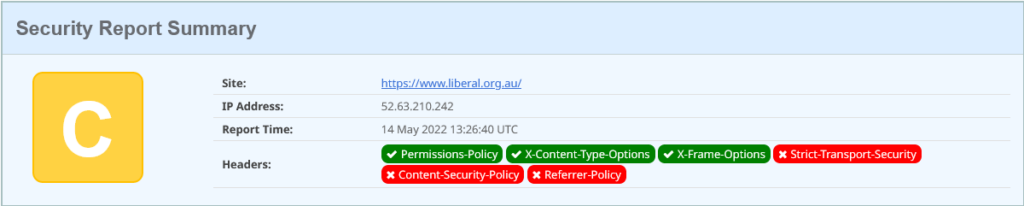
This is just marginally better than the Labour Party: they have enabled one extra header: the Permission Policy. This tells the browser what capabilities its allowed to use when rendering your content.
Its a good start: but the policy contains just “interest-cohort=()”. This policy is opting out of Google Analytics cohort analysis. as shown here, but its only supported on the Chrome browser. They’ve missed the chance to disable geo-location and other browser capabilities to protect their viewers.
The configured headers the admin has left enabled declare they have a Varnish Cache, and Apache/2.4.29. I’d recommend turning off as much of this identification as possible (hey admin, look up: ServerTokens PROD).
OK, on to SSLLabs analysis, but as we do, we get a different initial screen compared to our first review:
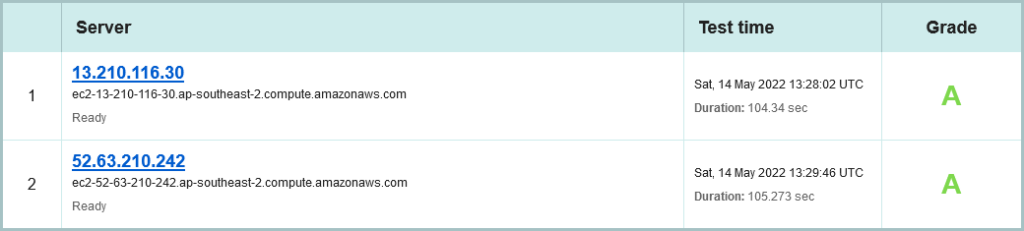
This time, we’ve detected two distinct site locations that this content has been served from. Again we’re only talking IPv4, but the reverse DNS shown gives away where; the AWS Sydney Region (which I helped launch as an AWS staff member in 2013).
This is possibly an AWS managed load balancer, configured across two Availability Zones (for those coming here for the first time, an Availability Zone, or AZ, is a cluster of data centres, so each AZ can be through of as a site: Central North Sydney, South Sydney. Indeed, The Sydney AWS Region has three AZs available as at May 2022, and not using the third AZ when its just sitting there is possibly a missed opportunity for higher fault tolerance.
Of course, both site locations are configured identically so we already know they rate as an A, so we can inspect any of the two in detail:
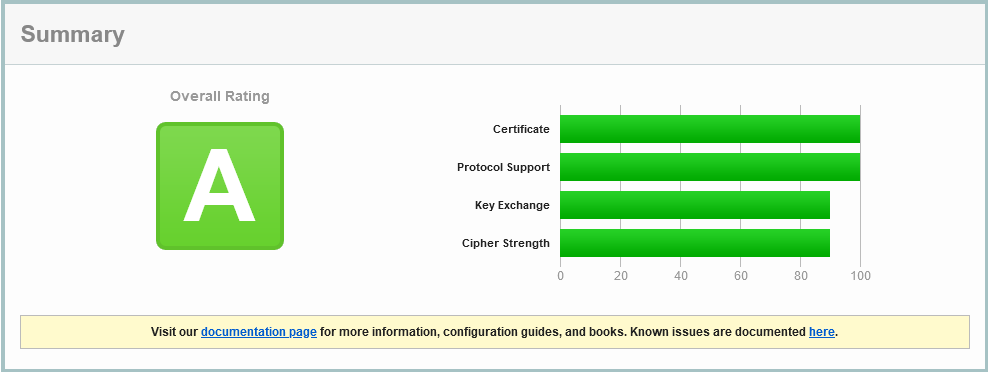
That’s pretty satisfying to start with.
We still note a missing DNS Certificate Authority Authorization (CAA) entry, as per the Labour Party. But we note that ONLY TLS 1.2 is enabled, and not the current best-in-show, TLS 1.3 (which is slightly optimised in connection establishment).
What is unusual is the ordering of the encryption ciphers here; some weaker ones are priorities over stronger ones:
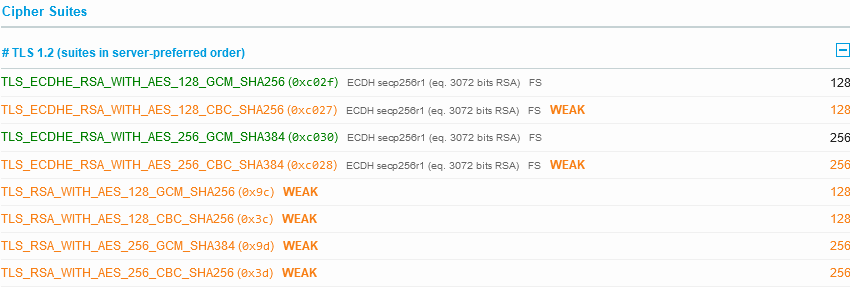
Normally you would want your strongest encryption ciphers first before the ones that are known to be weak are selected (or better yet, don’t even support the weak ones).
We note that only HTTP 1.0 is supported, not HTTP/1.1 not HTTP/2.
The Australian Greens
Start with the headers:
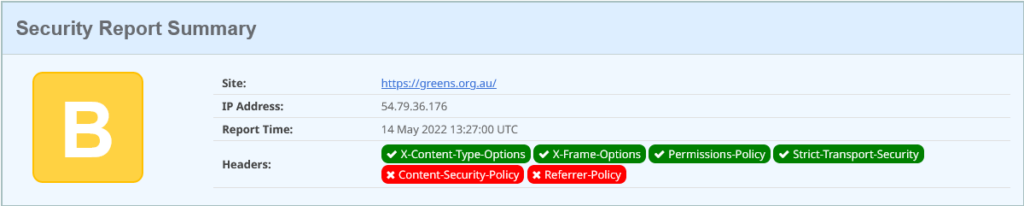
This is looking marginally more polished. It’s a Drupal 9 site (the headers show this – would be good to not advertise it). This time one additional legacy security header is set: x-content-type-options; this tells browsers to trust the mime content-type that is sent with objects, and not try and double-guess them (if the website admin got it wrong). For example, if we try and download an image, and the response is a content-type of image/jpeg, but the payload is JavaScript, then treat it as a broken image! Don’t keep guessing as browsers have in the past, as that guessing may trick the browser into executing some browser code that the admin had not intended.
OK, move to the crypto on SSLLabs – and this time we have three sites serving this content:
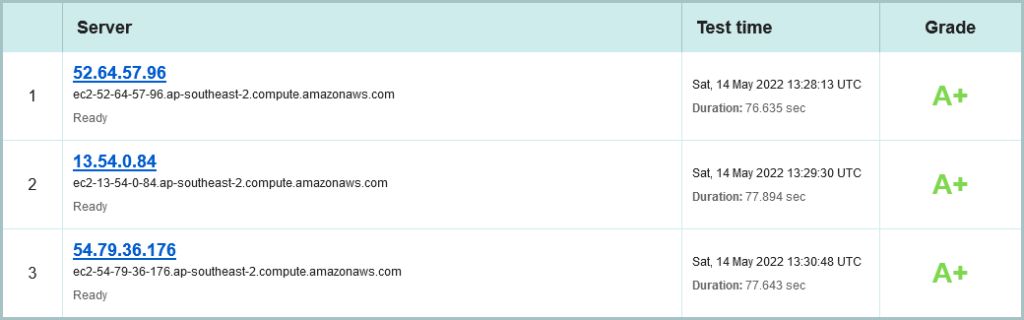
Nice, the Greens are also using AWS in Sydney, and are spread across all three Availability zones. (Shout out to an old friend: Grahame Bowland, are you doing this? 😉 ). Its still only IPv4, sadly. But already see see a stellar A+ rating:
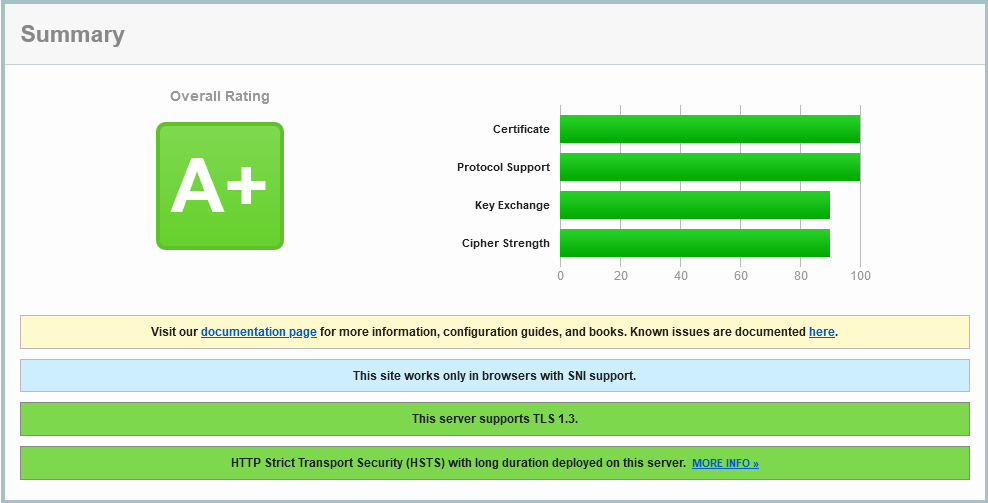
The same DNS CAA record is missing, but we see HTTP/2 is enabled, as well as just TLS 1.2 and 1.3. More over the cipher suite is super strong, with nothing weak supported:
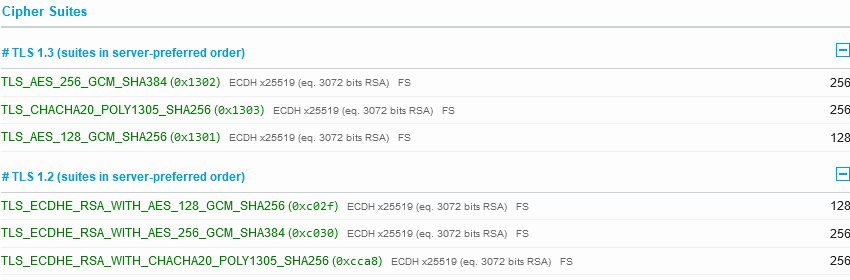
This is what a site that doesn’t take weak encryption as acceptable is supposed to look like!
The Climate200 Collective
There are a lot of candidates under this umbrella, and instead of reviewing them all independently, I’ll just pop over to https://www.climate200.com.au/. Lets roll with security headers:
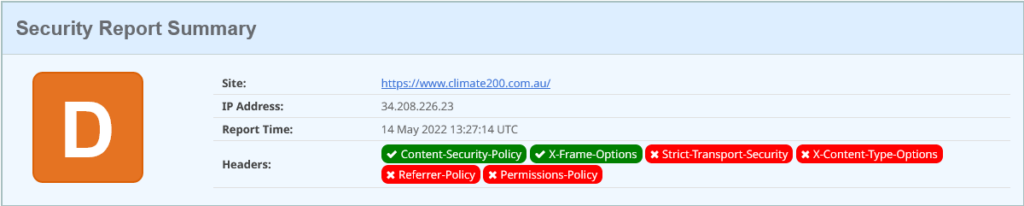
But this is stronger than it looks, because we finally have a Content Security Policy. However the extend of the policy is to limit frames and iframes, with “frame-ancestors ‘self’“. So much more has been missed, like enforcing everything the browser loads comes form the same domain, over HTTPS.
Now, headers are indicating this is an Open Resty server running on Containers (with Kubernetes management) in AWS’s US West 2 Region – also known as the AWS Oregon Region. AWS often speaks of this Region as running from a lot of green energy, which may be the reason for this.
OK, lets scoot to the network transport encryption report from SSL Labs, and again we have the three site presentation choice:
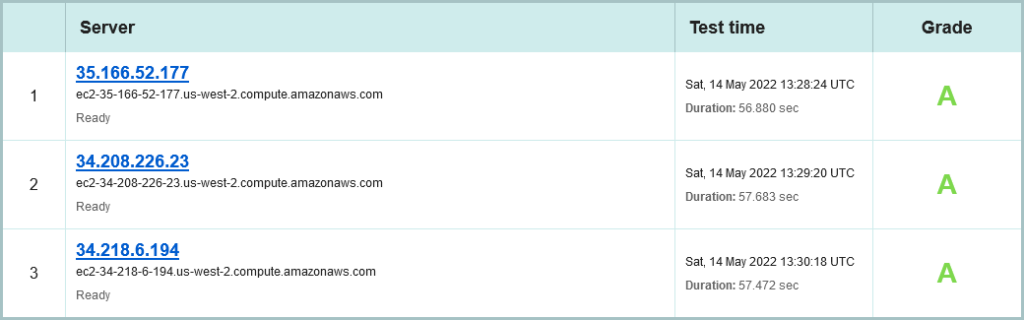
As with SecurityHeaders.com, the confirmation of using AWS, this time US-west-2 (Oregon) Region. All sites rating an A, but only using IPv4.
The Australian Election Commission
Now lets look at who is running the election, the AEC. A hat tip to their social media team who have been having a right ripper time with some bon humeur in the lead up to Democracy Sausage day (many polling booths in Australia will have a local, volunteer, non-partisan community group running a barbecue (bbq) with a sausage in a roll, possibly with grilled onion – oh I can smell it now!).
Right, AEC, how are your security headers:
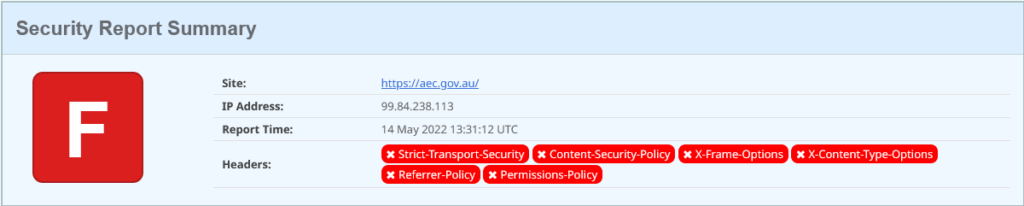
Oh. Erm.
Lets move to your crypto and see if we can recover this:
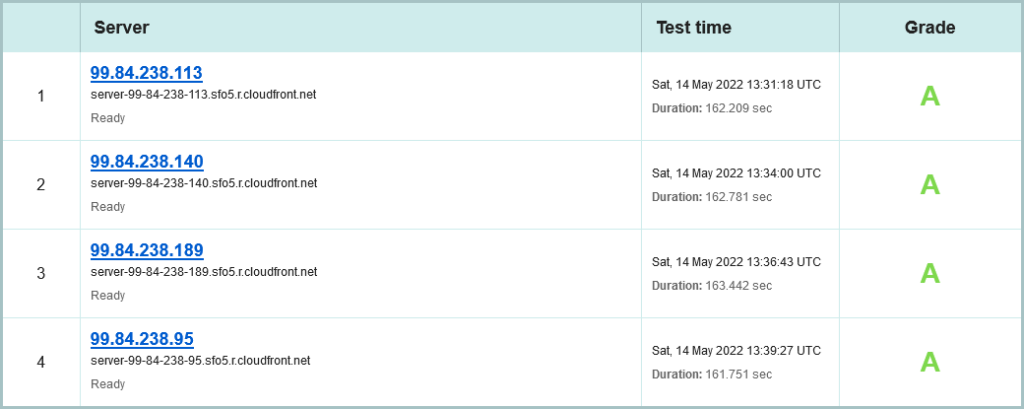
What a save! They are using a Content Delivery Network (CDN) to front their origin web service. That’s the fourth time in this article it’s been an AWS based service as well, but again its IPv4 only. Let’s lean in to the first site:
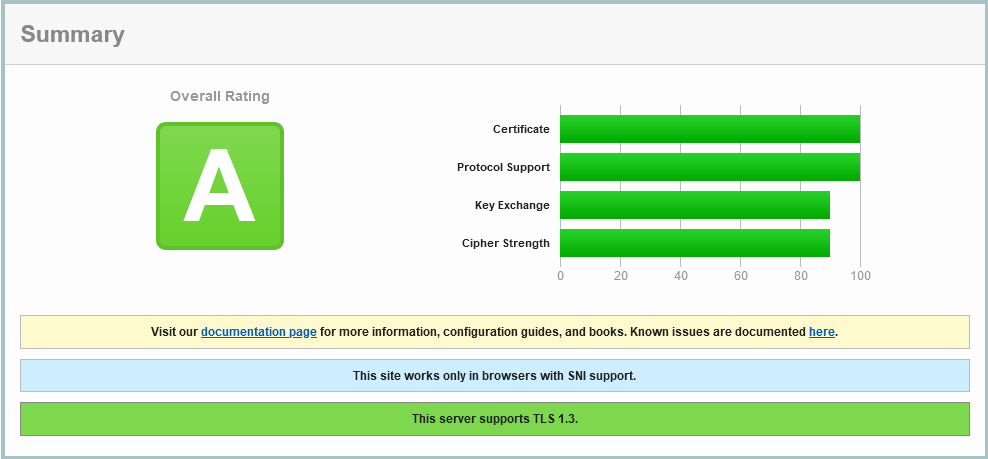
So we have TLS 1.3 enabled, with TLS 1.2 as a backdrop, but none of the older risky protocols. Nice. But the ciphers for TLS 1.2 are a little confused:
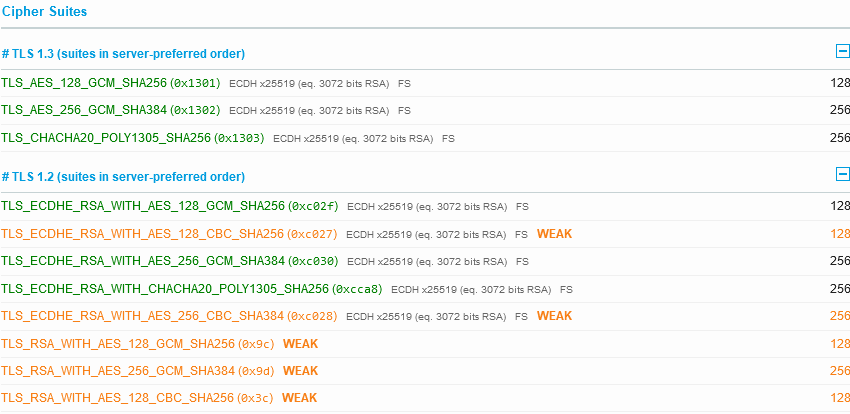
That CBC use of AES in yellow should be either below the other green ones, or removed. However, custom configuration is very limited with Amazon CloudFront; AWS does permit you to chose some good TLS options (I’ve worked for years with them to ensure these choices are available to customers).
Moving down the details shown, we saw HTTP/1.0, 1.1 and 2 are all available, which is also good.
An Overview
Lets put those ratings for the above organisations, and add a few more for good order, into a table:
| Party | Sec Headers | SSLLabs | Hosting | Multi-site | IPv6 |
|---|---|---|---|---|---|
| Labour Party | D | B | Melb? | No | No |
| Liberal Party | C | A | AWS Sydney | 2 AZ | No |
| Australian Greens | B | A+ | AWS Sydney | 3 AZ | No |
| Climate 200 | D | A | AWS Oregon | 3 AZ | No |
| Australian Electoral Commission | F | A | AWS CloudFront | Many (4 sites in DNS response) | No |
| United Australia Party | F | B | CloudFlare | Many (6 sites in DNS response) | Yes |
| One Nation | C | B | CloudFlare | Many (4 sites in DNS response) | Yes |
| Liberal Democrats | D | A | CloudFlare | Many (4 sites in DNS response) | Yes |
| Australian Christians | F | A | Host Universal in Melbourne | No | No |
So what can we deduce?
- None of them have populated a DNS CAA record to help ensure only their authorised Certificate Authority is issuing certificates in their name.
- Minor parties are using CloudFlare and permitting IPv6; none of the major parties have discovered IPv6!
- None of them have strong Content Security Policies
- Most major parties and the AEC are AWS Customers.
- I didn’t observe any of them implement Network Error Logging (NEL). Now there’s a nice feedback loop to help detect web security incidents as they happen…
So who would I chose as my winner here? It would be… the Greens, with the stronger ratings they have. There’s still room for improvement (like dual-stack IPv6, using CloudFront, a proper CSP), but they are ahead of the rest leading both of these basic assessments.
And the loser? Well, let’s not punch down too much; the explanations here are plain enough for any tech to follow the bouncing ball and enable better security, availability, and speed (at no additional cost!).
Does this make any difference to policies, fairness, environment (well, Australian Greens are using the AWS Oregon Region)? No, not really right now. I doubt any future minister for telecommunications is going to understand if the simple security adjustments shown could help increase security in any cyber attack. I just find this interesting…
As always, my thanks to Scott Helme for Security Headers, Ivan Ristic for SSLLabs, and the people who contribute to web and browser security improvements.