When I worked at AWS in 2012-2014, I championed the adoption of IPv6. I’ve spoken about Ipv6 many times on this blog, at AWS User Group Meetings, and with my colleagues at work. We’ve deployed solutions dual-stack for clients where there hasn’t been any cost implications in doing so.
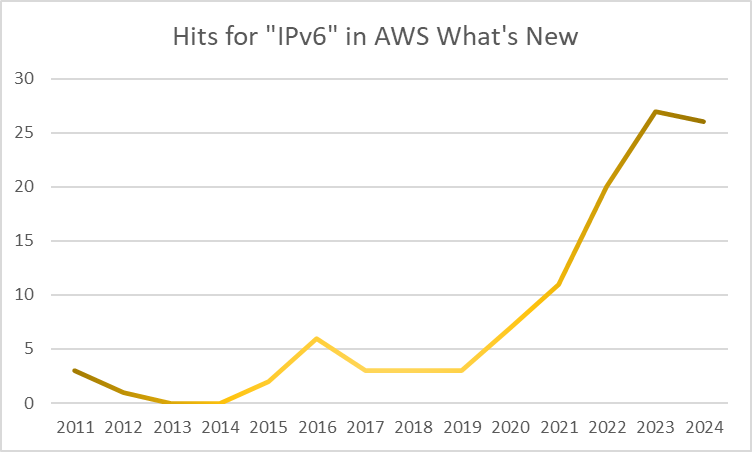
Over time, a number of “What’s new” posts have shown where IPv6 capability has been added. Now after 10 years since I departed AWS, I though I would look at the rate of IPv6 announcements and see =how it stacked up over time.
Clearly we can see an uptick in announcements from 2021 onwards. Additional managed services are still adopting; perhaps the rate of change is leveling out now.
I spent much of the pandemic, from late 2020 until December 2023, building a new family home. In Australia power efficiency for cooling (and heating) are critical. We minimised the size of north-facing windows, and ensured that thermal insulation was installed in the double-brick exterior walls, as well as sisal insulation under the roof tiles and Colorbond sheets, and then standard insulation above the ceilings. Lighting is almost exclusively LEDs.
Exterior (garden) smart lighting is configured to come on at sunset, then dim to 50% brightness at 10pm, and then further dim to 3% at 11pm, turning off at sunrise.
One key point was using our roof space for solar power, and so we commissioned a 10 KW inverter, and a single Tesla Powerwall 2, which was installed post-handover of the property in mid December 2023.
In January of 2024, we saw around 68% of our power usage was from the installed power system. The air conditioner was the biggest draw, on hot days it would run at a draw of 10 – 11 KW, and despite there being energy in the Powerwall, its limit was 5KW in and out (this is now increased in the PowerWall 3).
Even without the air conditioner, most days the PowerWall would be exhausted by around midnight, leaving just the grid supplying until the sun came up the next day.
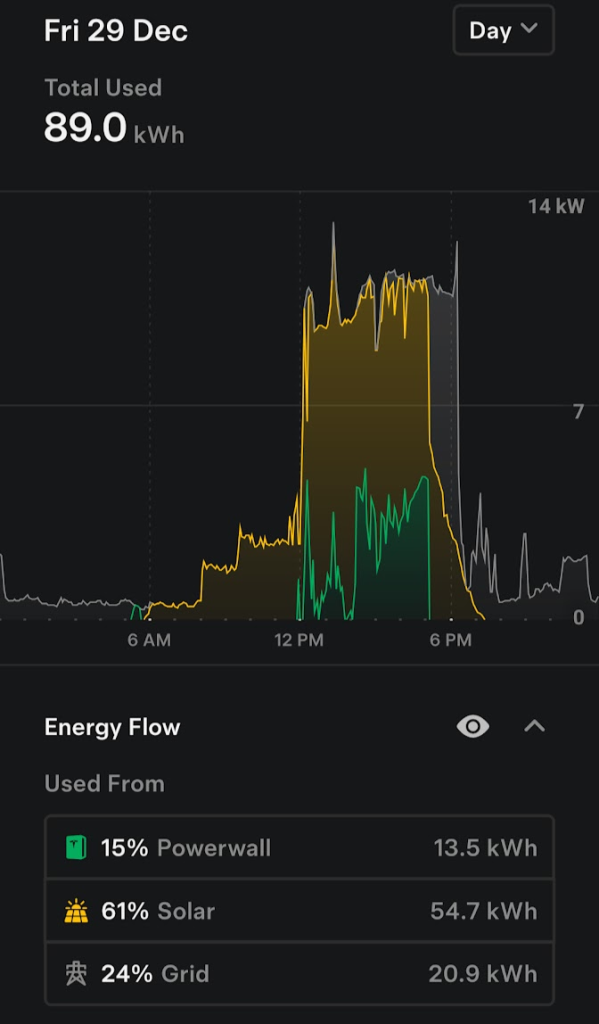
Here’s what December 29th looked like for me:
To further reduce power from the grid, I added a second set of panels on an additional 5KW inverter in May 2024.
By October 2024, the days in the southern hemisphere are getting longer, and the two inverters were at 100% load from mid-morning until 5pm or later, and we hit 90% of power coming from solar + battery for the month.
At this time, the Powerwall 2 was being discontinued, and existing PowerWall 2 installs cannot be expanded with PowerWall 3 units, so we divde in one more time and installed a second PowerWall in late October.
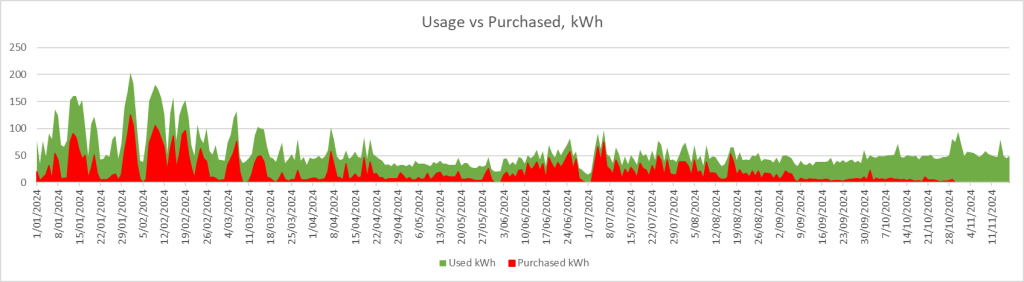
Since that second, we have not purchased any power from the grid.
The red is power purchased from the grid; the green is total power consumed.
Of course, we have yet to see the intense heat (and thus air conditioning draw) that February and March shows in my area.
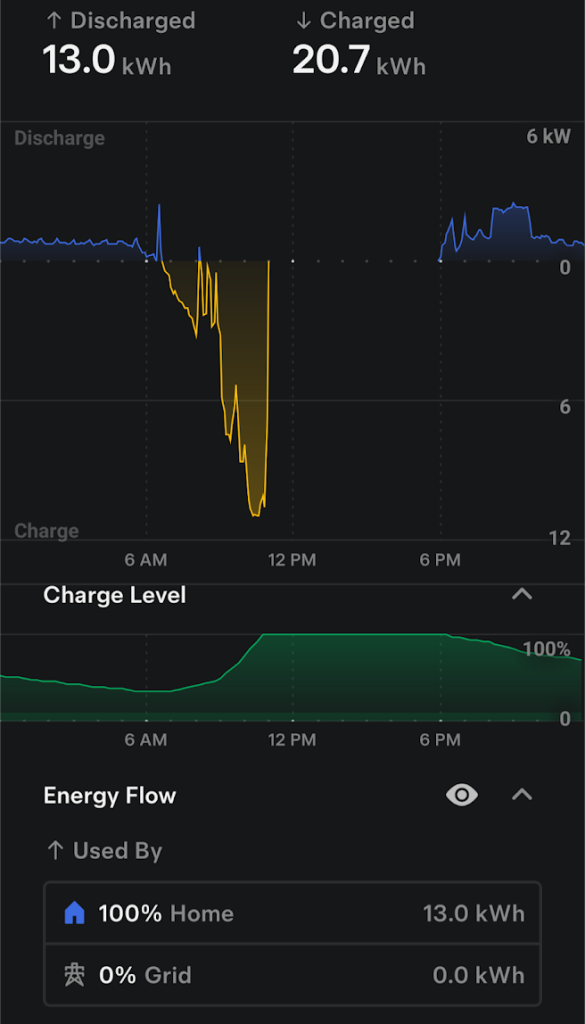
You’ll also note that most of our power usage is in the afternoon and evening, meaning the mornings are great time to charge batteries up:
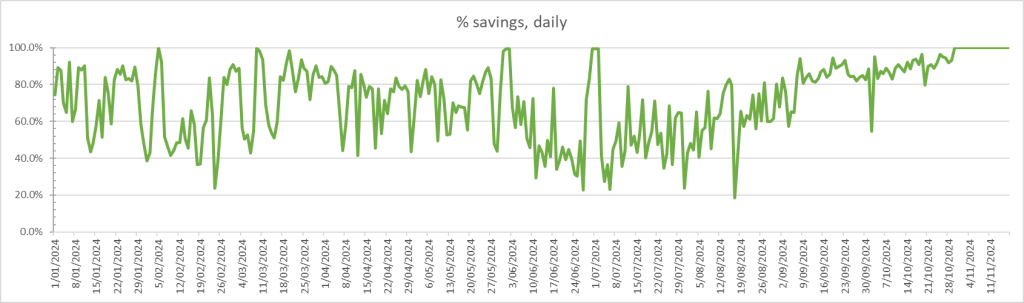
So what does that look like as a percentage saving per day:
The flatline at 100% is since the 2nd PowerWall went in.
I typically work from home these days (a global role that kicks in and out from9am until 10pm or later depending on the teams I am working with), but in an IT role means my work is mostly having my laptop (and screens) on.
One key question is the break even on this. If I use the last 3 weeks worth of data then it works out at a break even time of 7 years and 2 months. The last 300 days shows a 11 year break-even, but most of those 300 days did not have the 2nd PowerWall, nor the additional 5KW of solar generation. I imagine this will end up around an 8 years break even, within the 10 years warranty period of the battery, solar panels and inverters.
Two other points I get asked about:
we put in a total of 15 KW of inverters as we have three phase power to the property; in our area the power company limits the size of inverter(s) you can installed depending upon 3 phase or single phase supply
Having installed more than 5KW, the buy back for power fed back into the grid is $0.00. Nothing. Hence my system is set to reduce the amount fed to the grid, instead of sending as much as possible. If that was even $0.01 I’d remove that limit.
The cost of power from my provider, Synergy, increased on 1 July 2024 from 30.812c/KWH to 31.5823, or 2.5%. The connection fee (without consumption), went up from $1.1046/day, to $1.1322/day (just shy of 2.5%). This means I am still paying $413 per year (and increasing) to be connected to the grid, in case I run out of juice.
While I am no fan of the Tesla owner (and now government appointee?!), the technology appears to be sound, thus far. I’m pleased to have reduced my use of grid power to zero.
Lets see what the next 12 months of data produces.
In 2004, I was living in London, and decided it was time I had my own little virtual private server somewhere online. As a Debian developer since the start of 2000, it had to be Debian, and it still is…
This was before “cloud” as we know it today. Virtual Private Servers (VPS) was a new industry, providing root login to virtual servers that individuals could rent. And so I started being a client of Bytemark, who in turn offered me a discount as a Debian Gnu/Linux developer. With 1 GB of RAM, the initial VPS was very limited, but I ran my own mail server (with multiple domains), several web site s(all with SNI TLS enabled web sites, my own DNS server, and more.
Several years back I took the move to migrate my domains from being self-hosted on a VPS, to using AWS Route53. It was a small incremental cost, but I had long since stopped playing around and experimenting with DNS, and I wanted something that had high availability then a single virtual machine.
I have run a blog on my web site since the mid 1990’s (30+ years now), and WordPress has been my main platform since the late 2000s. This is WordPress now (2024), however a few years back I slotted AWS CloudFront in front of my origin service, to provide some level of global caching.
Several of the websites I run have also moved off to Amazon CloudFront, in particular all my small MTA STS web sites that serve just one small text file: the Mail Transport Agent Strict Transport Security policy document.
I still run my own mail server, with Exim4, PostgresQL, DoveCot Spamd, ClamD, etc. It lets me experiment with low level stuff that I still enjoy.
I have a few other services I want to move out of my VPS and into individual cloud-hosted platforms, but not everything is ready et. However a recent review of my VPC costings, and a forced migration from ByteMark (ioMart) to a new organisation UK Hosting, forced me to reconsider. So I took the inevitable change and migrated the entire VPS to AWS EC2 in Sydney, closer to where I am most of the time.
And so it comes to pass after 20 years, thank you to the team at Bytemark for my UK VPS.
Its late in 2024, and its time to recap the transitions in the technology space for Internet and web security. I’ve been reading the Internet Society’s pulse pages, and it gets me thinking…
HTTPS: generally this is well deployed with 97% of top 1000 web sites. But conversely, some 30 web sites don’t think the integrity (let alone the privacy) of data transfer from/to their web site is worth the effort? Here’s looking at you, Australia BOM, still force redirecting clients to unencrypted HTTP, particularly in light of your security incidents and increased funding for cyber security over the last decade.
TLS 1.3: Introduced in 2018, it only started taking off in 2019, and now sites as being available on 80% of the top 1000 sites. That’s some 200 sites that haven’t had the upgrade from older versions, which is almost exclusively TLS 1.2 (even older versions are gone, luckily).
HTTP/3: Based on a UDP transport instead of TCP, its seen a massive DROP in usage in the top 1000 with sites switching back to HTTP/2.
IPv6: Now sitting around 45%. For me, this is a trivial item to enable on Cloud; but some Internet Access Providers (ISPs, Telcos) are sweating their existing installations instead of moving their engineering forward (hello Optus: is IPv6 still not Yes!).
For me, these four technologies are a baseline implementation that do not add significant additional cost for operations, but provide speed, security, and connectivity enhancements.
I always recommend tools like SSLLabs.com, SecurityHeaders.com, Hardenize.com, and SSL.sh to test your services and help improve your delivery. If your web service misses these items, then you may need to consider upskilling your team or service provider, or switching your telco/carrier.
30 years ago, in 1994, I started studying at The University of Western Australia (UWA). At the start of the semester, an Orientation Day (O-Day) is held, where the various student clubs would try and recruit members.
Starting as a Computer Science student, I gravitated towards the University Computer Club stand, and signed up to become a member for a few dollars. Founded in 1974, it pre-dates and outlasts the famed Homebrew Computer Club (1975 – 1986), and even pre-dates the UWA Department of Computer Science.
This year the club turns 50, and a dinner was held.
Dr Andrew Williams on stage at the UCC 50th, University Club, UWA
Around 90 past and present members met for dinner at The UWA University Club function centre to reminisce, celebrate, and look forward to the future.
One key element to the ongoing success of a student club is having a space to congregate and to store equipment. Without a physical space that can be the club, it becomes very ephemeral, and often organisations disappear. The UWA Student Gild has supported the UCC with space for most of the 50 year history, and since the early 1990s, this has been a large space in the loft of Cameron Hall.
The UCC as seen from above, with Michael Deegan, James Bromberger and Shay Telfer, on the night of the UCC 50th anniversary dinnerThe UCC at UWA, on the night of the 50th anniversary, 21 Sept 2024.
In the above, you can see a green roof space on the left hand side: this is the UCC Machine Room. A few of us built this space around 1996 in order to house some of the servers that we had acquired, and to duct the air-conditioning (hanging from a window) to keep them cool. Nearly 30 years later, this structure is still standing, make from wood purchased from Bunnings, and a pair of frosted glass doors acquired from a recycling center in Bayswater.
On the shelves you can see manuals – lots of them, for things like BeOS, NextStep, various programming languages, Sun hardware, IBM hardware, On the shelfs is various hardware, cables, connectors and adaptors. On the tables are terminals, 3d printers, soldering irons, disk packs, tape reels, half built robot brains — spanning decades of technology changes. Posters from events past and present adorn surfaces, encouraging participation in activities, experimentation in software and hardware, and more.
One thing clear from the pictures shown is the impact technology ha had on our society. In 1994 I had a digital camera, a Kodak DC40. I took, stored and retained many photos, straight to digital, when most people were still using film (and taking that film to their local pharmacist/chemist to process/print???!). Today, everyone uses digital photography, mostly form their phones. Its normalised, ubiquitous, and the incremental cost for an image is practically zero (just the storage costs of the data produced). The quality is good today compared with 30 years ago.
Dr Williams (above) was one of the first in the world to put a CCD camera on the end of a telescope at the WA Observatory to record images, leading to many observations that would have historically been missed (not to mention, the flexibility to be one of the first astronomers to be working from home on cold nights).
Along one wall is a framed colour picture, taken by a West Australian newspaper photographer around 1997 or so. It shows a series of old IBM 360 cabinets – parts of a large mainframe computer, that was being disposed of from the UWA storage facility in the suburb of Shenton Park. Many old computers had names; this one was called Ben. It had been donated to the UCC well before my arrival, but now the time had come that this storage facility was being repurposed, and Ben had to go. Luckily it was being donated to a museum collector, and over the years I believe it made its way to the Living Computer Museum in Seattle.
But sitting on the wall of the UCC for the last 30 years has been my picture. Watching thousands of UCCans arrive fresh faced, and seen them learn, connect and evolve into some of the individuals who have powered organisations like Apple, Google, Amazon, Shell, BHP, Rio Tinto, The Square Kilometer Array, and many more.
I served as UCC President in 1996, and I helped organise the UCC’s 18th anniversary, 21st, and 25th. Now at 50, its clear that having the physical space to meet – and eat pizza, discuss news, share tips and skills – has been a key part of the longevity of the UCC.