There’s a word in “Gen AI” that I want you to concentrate on: generative.
Next I’d like you to think about areas in your organisation where you can safely generate (and review what’s generated). This is probably not safe in your invoicing, product testing & QA, CRM records, etc. Those systems all use something else: facts. Facts cannot be generated.
The inordinate amount of hype around GenAI, including finance people on the Australian Broadcast Corporation (ABC Australia) talking about the demise of one company because “Gen AI can now do what their product tech was” is well out of proportion.
Have you noticed how the hyper about the Metaverse has dropped off?
And blockchain?
These are all great technologies, but lets face it, in the majority of cases they have very little to do with the core business of what your organisation does – unless you’re in the arts and creative industries.
There are fantastic demos from Adobe where they generate additional image content. There are prose, poems and fiction being generated. All of which is circling around and creating content from existing examples. It may look fresh, but its generated from existing input, but without human intuition, insight, or intelligence.
We see “director of GenAI” as a job title, but I think that will last about as long as “director of blockchain“.
These technologies do have a place – I called out Adobe above, and you may use their software – but remember, the advantage is to Adobe’s product, and probably not yours. You likely don’t work for Adobe (I’m not picking on them, but the data is in: most of the world does not work there). You’re likely to be a few layers down in the value chain. You’ll benefit from it, but I don’t think you’re going to be training your own LLMs. Someone else will, and they’ll charge you for it or figure out a way to recoup the expense by some method.
But remember, its generated. I can use GenAI to give me tonight’s lottery numbers. While plausible, they are unlikely to be correct.
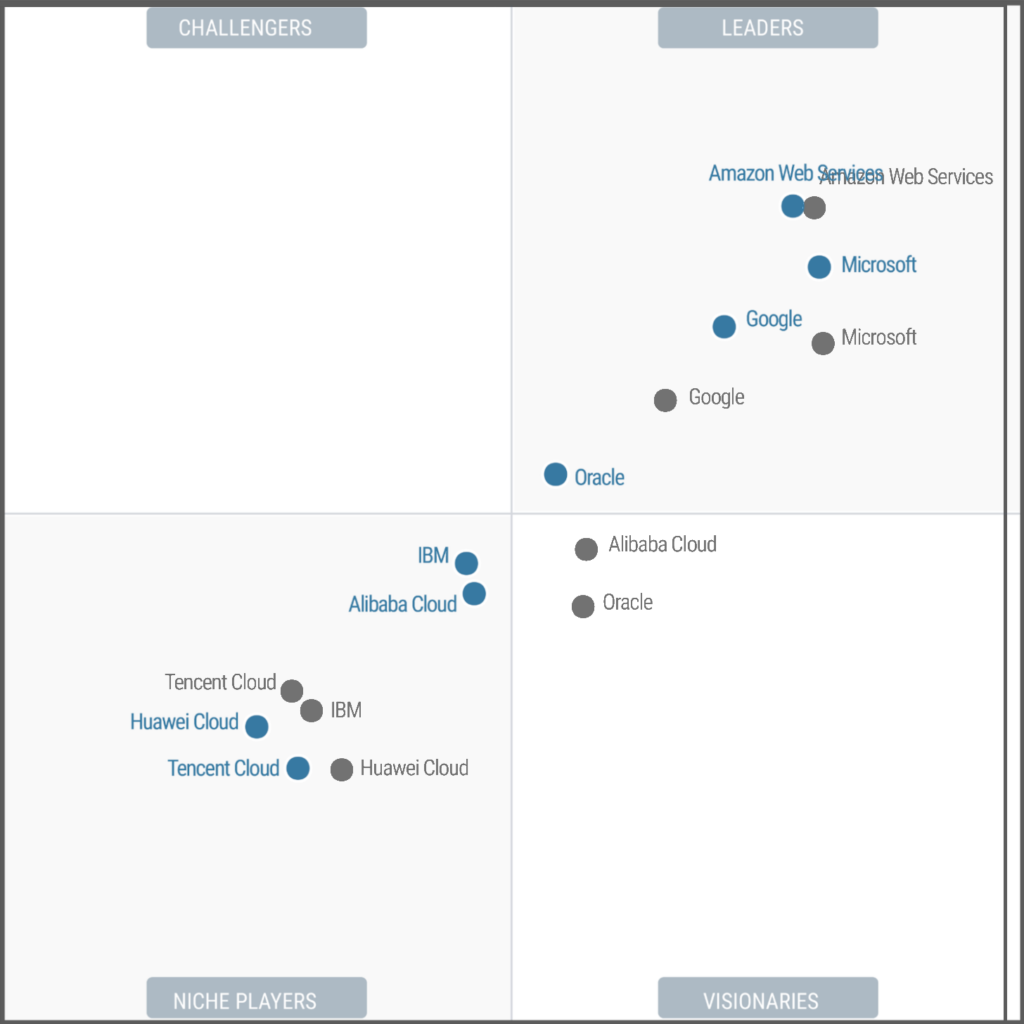
The traditional Gartner tea-leaves view of hyperscalar cloud providers was renamed in 2023, from “Magic Quadrant for Cloud Infrastructure and Platform Services” to “Magic Quadrant for Strategic Cloud Platform Services”. But the players are all the same as in 2022:
In grey are the 2022 results, and in blue is the 2023.
Alibaba slips a whole quadrant, with a large drop in its completeness of vision
Oracle rises a whole quadrant to join the leaders, but only just
Tencent dropped its ability to execute.
IBM picked up substantially, but still a niche player (but they are also the worlds largest AWS Consulting Services Partner when counted by AWS certification numbers (21,207), followed closely by Tata Consulting Services (21,200))
Huawei regressed its completeness of vision, but marginally improved its ability to execute
Google rose to now start approaching AWS and Microsoft.
Microsoft improved its ability to execute
AWS dropped its “completeness of vision” slightly
There’s only really three legitimate global hyperscalar contenders: AWS, Microsoft and Google, in that order. The rest are focused and founded within the great firewall of China, or IBM.
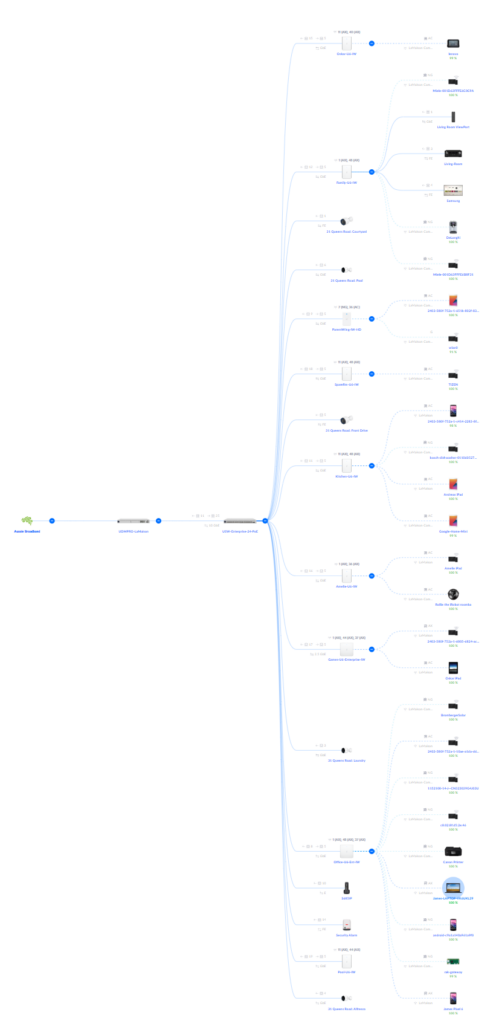
Over the 2023 end of year, I moved home. A long process of three years of construction and I have a shiny new pad. And of course back in 202, I had done diagrams for the cabling and access points that I would require. I had used the Ubiquity Networks Design Centre, design.ui.com, to lay out the plan: two floors of primary residential, with WiFi access points around the outer walls.
I wanted the flexibility of also having some ethernet patches, so it made sense (to me) to use the Unifi In Wall access points, as the provide a 4 port switch (and one of those ports is pass-through PoE). I also anted to ensure good WiFi coverage from the far rear of the property by a proposed swimming pool: no excusing for whinging about coverage for iPad users when lounging by that end of the property.
In the period that passed, Ubiquiti released the U6-IW device to replace the IW-HD, and the Enterprise U6-IW which ups the game to include a radio on the 6GHz spectrum in addition tot he existing 2.4GHz and 5GHz.
This is now all in place. The topology now looks like this:
The core of this is still my original Unifi Dream machine, and a 24 port Enterprise switch: you’ll note that most ports are actually used. Nearly everything plugged directly to the core switch is PoE: security cameras and In Wall access points.
Nice, so lets fire up 6HGz (form newer devices) and see what we can do. I went to edit the existing Wireless network definition, and ticked the “6Hz” option. At this time, the WiFi security instantly changed from “WPA2/WPA3” to only WPA3.
This instantly dropped half my devices off the network . Even the newest of home “wifi” appliances – dishwasher, garage doors, ovens, home security systems, doorbell intercoms can not handle WPA3. Indeed, lets look at these devices:
Miele oven (2023): WiFi 4
DeLonghi Coffee machine (2023): WiFi 4
Bosch Dishwasher (2023): WiFi 4
Fronius 10kW solar inverter (2023): WiFi 4
iRobot Roomba J7+ (2022): WiFi 5
These are all new devices, and yet the best Wifi they support means I’ll have to leave 802.11n enabled for the next decade or longer (until I replace them with something newer).
So now I have two WiFi networks: the primary ESSID that is 6GHz and WPA3, and a secondary “compatible” ESSID that does not permit 6GHz, but does support WPA2.
These device manufacturers are only listing “WiFi” in their sales messaging. None of them are going the next level of calling out which WiFi version they support, and what version of WPA. It’s time that manufacturers catch up on this, and enable consumers to select products that are more secure, and not products that force deprecated protocols to be used.
Today (Monday 27th of November) is the first day of a new AWS Certification: The AWS Certified Data Engineer —Associate. This is in a beta period now, and as such, any candidates who sit this certification won’t get a result until up to 13 weeks after the end of the beta period.
That beta period is November 27, 2023 – January 12, 2024; so in some time in February or March candidates will find out how they went. During that period, AWS will be assessing where the pass mark should be.
I’ve been pretty forthright in attempting most AWS certifications; I’ve always like to lead from the front to help demonstrate even an aging open source tech geek sys admin like myself can do this. And to that end, I reserved a quiet meeting room at 0200 UTC today (10am AWST) to do the online-proctored exam for this certification.
As always there are terms & conditions on disclosure, so I can only speak at high level. It was 85 questions, the vast majority where to select one correct answer (key) from four possibilities; only a handful had the “select any TWO” option.
The questions I received focuses on Glue, Redshift, Athena, Kinesis, and in passing, S3 and IAM. I say “I received“, as there is a pool of questions, and I would have only had 85 from a larger pool; your assessment would likely be different questions.
It took me around ne hour fifteen minutes, and I went back to review just 2 questrions.
Overall I found this was perhaps a little more detailed and domain based than the existing Associate level certifications. There were use cases for Redshift that I’ve not used that stumped me. There were Glue and Databrew use cases I haven’t used in production.
All in all I think its well placed to ensure that candidates have a solid understanding of data engineering, fault tolerance, cost, and durability of data. For those that are doing cloud native data analytics pipelines, then I would say this should be on your list of certs to get.
We’ll find out in Q1 if I am up to speed on this. 😉
Code build sits amongst a slew of Code* services, which developers can pick and chose from to get their jobs done. I’m going to concentrate on just three of them:
Code Commit: a managed Git repository
Code Build: a service to launch compute* to execute software compile/built/test services
Code Pipeline: a CI/CD pipeline that helps orchestrate the pattern of build and release actions, across different environments
My common use case is for publishing (mostly) static web sites. Being a web developer since the early 1990s, I’m pretty comfortable with importing some web frameworks, writing some HTML and additional CSS, grabbing some images, and then publishing the content.
That content is typically deployed to an S3 Bucket, with CloudFront sitting in front of it, and Route53 doing its duty for DNS resolution… times two or three environments (dev, test, prod).
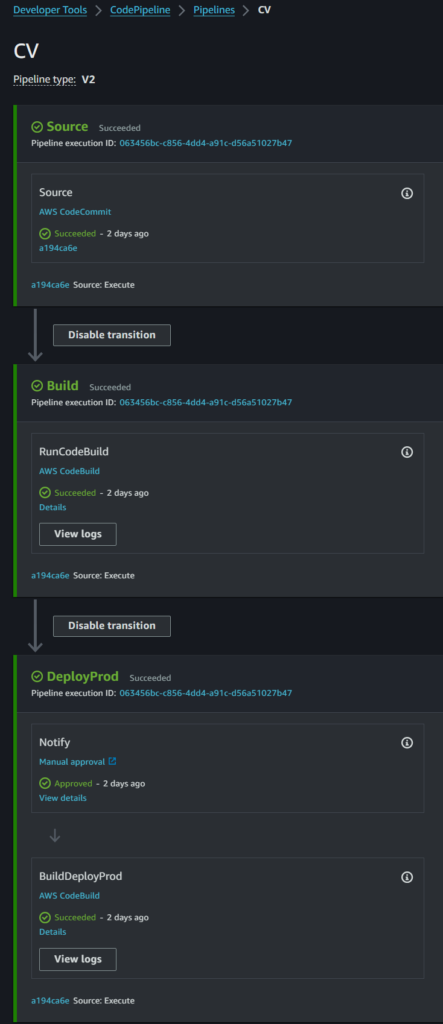
CodePipeline can be automatically kicked off when a developer pushes a commit to the repo. For several years I have used the native Code Pipeline service to deploy this artifact, but there’s always been a few niggles.
As a developer, I also like having some pre-commit hooks. I like to ensure my HTML is reasonable, that I haven’t put any credentials in my code, etc. For this I use the pre-commit hooks.
Here’s my “.pre-commit-config.yaml” file, that sits in the base of my content repo:
There’s a few more “dot” files such as “.htmllintrc” that also get created and persisted to the repo, but here’s the catch: I want them there for the developers, but I want them purged when being published.
Using the original CodePipeline with the native S3 Deployer was simple, but didn’t give the opportunity to tidy up. That would require Code Build.
However, until this new announcement, using code build meant defining a whole EC2 instance (and VPC for it to live in) and waiting the 20 – 60 seconds for it to start before running your code. The time, and cost, wasn’t worth it in my opinion.
Until now, with Lambda.
I defined (and committed to the repo) a buildspec.yml file, and the commands in the build section show what I am tidying up:
Yes, the buildspec.yml file is one of the files I don’t want to publish.
Time to change the Pipeline order, and include a Build stage that created a new output artifact based upon that. The above buildspec.yml file then has an additional section at the end:
artifacts:
files:
- '**/*'
This the code Build job config, we define a new name for the output artifacts, int his case I called it “TidySource”.However there was an issue with the output artifact from this.
When CodeCommit triggers a build, it makes a single artifact available to the pipeline: the ZIP contents from the repo, in an S3 Bucket for the pipeline. The format of this object’s key (name) is:
The original S3 Deployer in CodePipeline understood that, and gave you the option to decompress the object (zip file) when it put it in the configured destination bucket.
CodeBuild supports multiple artifacts, and its format for the output object defined from the buildspec is:
As such, S3 Deployer would then look for the object that should match the first syntax, and fails.
Hmmm.
OK, I had one more niggle about the s3 deployer: it doesn’t tidy up. If you delete something from your repo, the S3 deploy does not delete from the deployment location – it just unpacks over the top, leaving previously deployed files in place.
So my last change was to ditch both the output artifact from code build, and the original S3 deployer itself, and use the trusty aws s3 sync command, and a few variables in the code pipeline:
You can view the resulting web site at https://cv.jamesbromberger.com/. If you read the footnotes here it will tell you about some of the pipeline. Now I have a new place to play in – automating some of the framework management via NPM during the build phase, and running a few sed commands to update resulting paths in HTML content.
But my big wins are:
You can’t hit https://cv.jamesbromberger.com/.htmllintrc any more (not that there was anything secure in there, but I like to be… tidy)
Older versions of frameworks (bootstrap) are no longer lying around in /assets/bootstrap-${version}/.
Its not costing me more timer or money when doing this tidy up, thanks to Lambda.