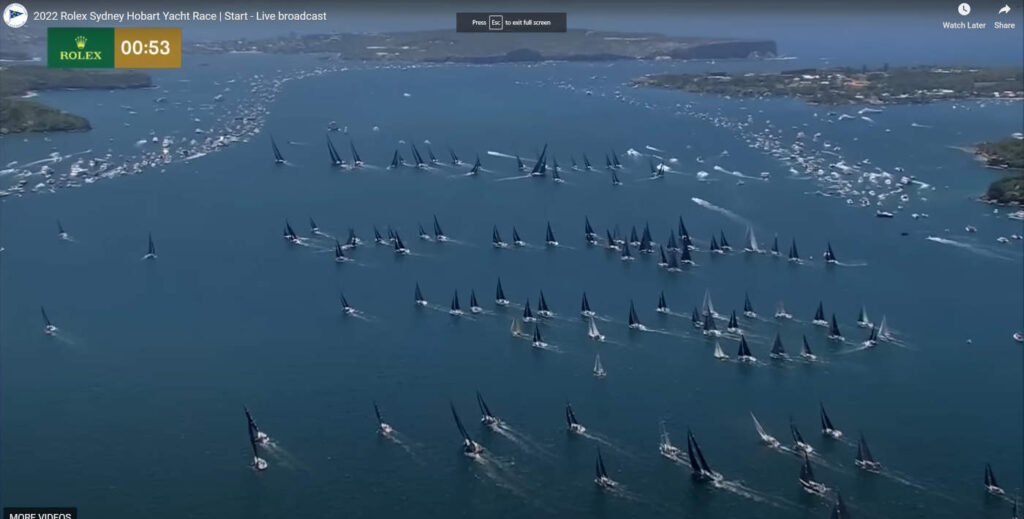
This years Sydney to Hobart was a stunning race. Coverage on broadcast TV in Australia started with good coverage by Seven West Media’s 7+ service. The stunning coverage included a view of the four simultaneous start lines for the different classes:
Four start lines of the 2022 Sydney to Hobart Yacht Race, taken from @CYCATV on YouTube
Sadly, the broadcast TV coverage ended just after the start. With 7+ on the sail of one of the boats, I was expecting a bit more coverage.
Luckily the CYC had an intermittent live stream on YouTube, with Peter Shipway (nominative determinism at work there), Gordon Bray and Peter Gee hosting.
The primary website for the race this year was https://www.rolexsydneyhobart.com/, and this year this appeared to be running via AWS CloudFront.
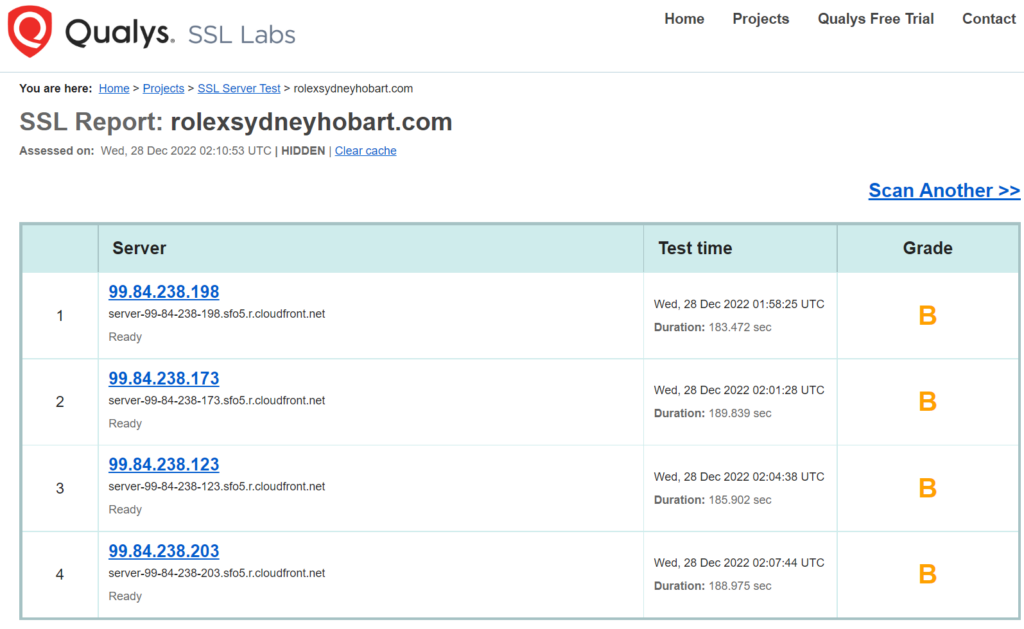
Time for a quick health check, with SSL Labs:
After noting this is CloudFront, I notice that its resolved as IPv4 only. Shame, as IPv6 is just two steps away: tick a box in the CloudFront config, and publish an AAAA record in DNS. Its also interesting that some of the sub-resources being loaded on their page from alternate origins are available over IPv6 (as well as good old IPv4).
Talking of DNS, a quick nslookup shows Route53 in use.
Back to the output, a B. Here’s a few items observed on the SSLLabs report:
TLS 1.1 is enabled – it’s well past time to retire this. Luckily, TLS 1.2 and 1.3 are both enabled.
Even with TLS 1.2, there are some weak ciphers, but (luckily?) the first one in the list is reasonably strong.
HTTP/2 is not enabled (falling back to HTTP/1.1).
HTTP/3 is not enabled. Even more performance than HTTP/2.
Amazon Certificate Manager (ACM) is in use for the TLS certificate on CloudFront
It also says that there is no DNS CAA record, a simple way to lock out any other CA provider being duped into mis-issuance of a certificate. A low risk, but a (free) way to prevent this.
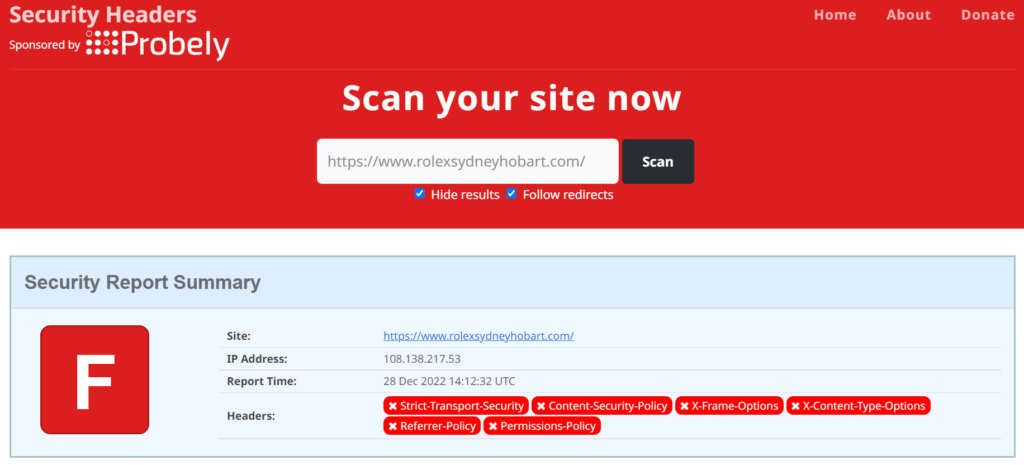
Turning to SecurityHeaders.com, we get this:
SecurityHeaders.com output for rolexsydneyhobart.com, December 2022
Unfortunately, looks like no security related headers are sent.
Strict Transport Security (HSTS) is a no-brainer these days. We (as a world) have all gone TLS for online security, and we’re not heading back to unencrypted HTTP.
The service stayed up and responsive: well done to the team who put this together, and good luck with looking through the event and finding improvements (like above) for next year.
The Chief Executive of insurance company Zurich, Mario Greco, recently said:
“What will become uninsurable is going to be cyber,” he said. “What if someone takes control of vital parts of our infrastructure, the consequences of that?”
Mario Greco, Zurich
In the same article is Lloyds insurance looking for exceptions in Cyber insurance for those attacks that are state based actors, which is a difficult thing to prove with certainty.
All in all, some reasons that Cyber Insurance exists is to cover from a risk perspective the opportunity of spending less on insurance premiums (and having financial recompense to cover operational costs) that having competent processes around software maintenance to code securely to start with, detect threats quickly, and maintain (patch/update) rapidly over time.
The structure of most organisations to have a “support team” who are responsible for an ever growing list of digital solutions, goaled on cost minimisation, and not measured against the amount of maintenance actions per solutions operated.
Its one of the reasons I like the siloed approach of DevOps and Service Teams. Scope is contained to one (or a small number of similar) solution(s). Same tech base, same skill set. With a remit to have observability, metrics and focus on one solution, the team can go deep on full-stack maintenance, focusing on a job well done, rather than a system that is just turned on.
It’s the difference between a grand painter, and a photocopier. Both make images; and for some low-value solutions, perhaps a photocopier is all they are worth investing in from a risk-reward perspective. But for those solutions that are the digital-life-blood of an organisation, the differentiator to competitors, and those that have the biggest end-customer impact, then perhaps they need a more appropriate level of operational investment — as part of the digital solution, not as a separate cost centre that can be seen to be minimised or eradicated.
If Cyber insurance goes end-of-life as a product in the insurance industry, then the war on talent, the focus to find those artisans who can adequately provide that , increases. All companies want the smartest people, as one smarter person may be more cost effective than 3 average engineers.
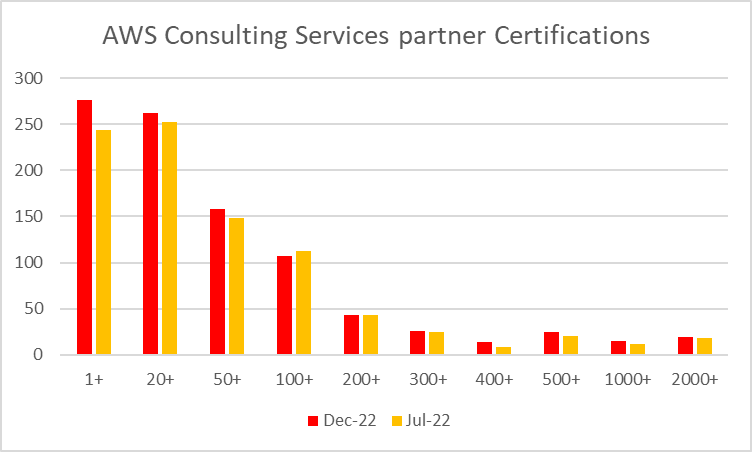
This time, there were 945 partners in the data set, up from 882 in July by 62 new organisations or a 7.1% increase.
What was clear is that much of this growth is at the lower levels but we can also see some growth in the larger buckets of certs, with two exceptions.
The 100-200 category saw a drop in the number of partners in this space, but only by 5 organisations. Similarly, the 200-300 space remained stable at 43 organisations, but I know of several businesses that have migrated from the 200+ to 300+ category. so others have moved into this grouping from the lower levels.
1+
20+
50+
100+
200+
300+
400+
500+
1000+
2000+
Dec 2022
276
262
158
107
43
26
14
25
15
19
Jul 2022
244
252
148
112
43
25
8
20
12
18
ASW Certifications held by Consulting Services partners in the AWS Partner Finder
Is at the 400-500 grouping that an increase of 75% has been seen, from 8 organisations to 14.
Furthermore, raw data shows that there are 9 organisations who would fit in a 5000+ certification grouping – who combined would have 117,317 AWS certifications.
The largest? 36,098 certifications goes to Accenture, followed by 14,740 at IBM, and Deloitte on 14,605. Deloitte would be #2 if they grouped Deloitte Shanghai and Deloitte Tohmatsu together. Similarly, NTT is in the partner data as 5 separate organisations.
IPv6 has been something I have long championed, ever since establishing the first tunnels in the last 1990’s when I was working at UWA. Its also something I was pushing to AWS Service Delivery teams when I worked at AWS in the early 2010s, and in my time at Ajilon/Modis/Akkodis, I have set IPv6 as a stretch goal for all AWS projects to support as a standard.
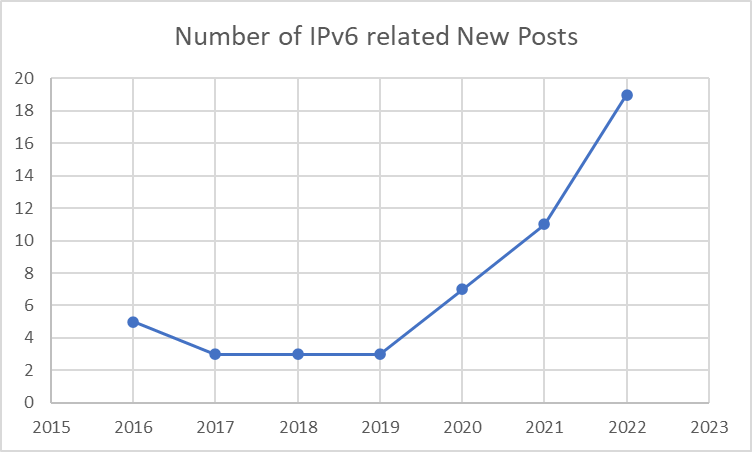
What’s interesting to see is the increase in IPv6 related announcements from ASW in the What’s New page by year:
Number of IPv6 related posts on AWS What’s New page, as at 19 Dec 2022.
It’s clear that IPv6 is now a first class citizen. Coverage is pretty strong, and customers not only can, but in my opinion should, be targeting dual stack solutions, or in some use cases, IPv6-only deployments.
As System Operators (Sys Admins), DevOps and Developer folk, you should be fully comfortable with another transport protocol. Any considerations around addressing should be minimal. In the on-premises desktop/end-user-compute environment, your internal networks are possibly all IPv4 only, but your corporate proxy should now be dual-homed. (It should also be supporting TLS 1.3 and HTTP/3).
I’ve been talking for the last number of years about some of the web security changes that have happened in the web/browser/PKI landscape, many of which have happened quietly and those not paying attention may have missed.
One very interesting element has been a modern browser capability called Network Error Logging. Its significant as it fixes a problem in the web space where errors may happen on the client side, and the server side hears nothing about it.
Adopting NEL is another tool in your DevOps armoury, to drive operational excellence and continuous improvement of your deployed web applications, helping to retain customers and increase business value.
Essentially, this is a simple HTTP header string that can be set, and browsers that recognise it will cache that information for a period (that you specify). If the browser has any of a whole set of operational issues while using your web site, then it has an opportunity to submit a report to your error logging endpoint (or cache it to submit later).
Prior to this, you would have to rely on the generosity of users reporting issues for you. The chance of a good Samaritan (white hat) getting through a customer support line to report issues is.. small! Try calling your local grocery store and tell them they have a JavaScript error. Indeed, for this issue, we have RFC 9116 for security.txt.
Having your users report your bad news is kind of like this scene from the 1995 James Bond film GoldenEye:
“Unlike the American Government we prefer not to get our bad news from CNN” – M, GoldenEye
So, what’s the use-case of Network Error Logging. I’ll split this into four scenarios:
Developer environments
Testing environments
Non-production UAT environments
Production Environments
Developer Environments
Developers love to code, and will produce vast amounts of code, and have it work in their own browser. They’ll also respond to error sin their own environments. But without the NEL error logs, they may miss the critical point a bug is at, when something fails to render in the browser.
NEL gives developers the visibility they are lacking when they hit issues, with otherwise, need screen captures from the browser session (which are still useful, particularly if your screen capture includes the complete time (including seconds) and the system is NTP synchronised).
With stricter requirements coming (such as Content Security Policies being mandated by the PCI DSS version 4 draft on payment processing pages), the sooner you can give developers the visibility of why operations have failed, the more likely of success when the software project makes it to a higher environment.
So, developers should have a non-production NEL endpoint, just to collect logs, so they can review and sort them, and affect change. Its not likely to be high volume reporting here – it’s just your own development team using it, and old reports are quickly worthless (apart from identifying regressions).
Testing Environments
Like developers, Test Engineers are trying to gather evidence of failures to feed into trouble ticketing systems. A NEL endpoint gives Testers this evidence. Again the volume reporting may be pretty low, but the value of the reporting will again help errors hitting higher environments.
Non-Production UAT Environments
This is your last chance to ensure that the next release into production is not hitting silly issues. The goal here to is make the volume of NEL reports approach zero, and any that come in are likely to be blockers. Depending on the size of your UAT validation, the volume will still be low.
Production Environments
This is where NEL becomes even more important. Your Security teams and your operational teams need to both have real-time visibility of reporting, as the evidence here could be indicative of active attempts to subvert the browser. Of course the volume of reports could also be much larger, so be prepared to trade the fraction of reporting to balance the volume of reports. It may also be worth using a commercial NEL endpoint provider for this environment.
Running your own NEL Endpoint
There is nothing stopping you from running your own NEL endpoint, and this is particularly useful in low volume, non-production scenarios. It’s relatively, simple, you just need to think of your roll out:
Let every project define their own NEL endpoints, perhaps one per environment, and let them collect and process their own reports
Provide a single central company-wide non-production NEL endpoint, but then give all developers access to the reports
Somewhere in the middle of these above two options?
Of course, none of these are One Way Doors. You can always adjust your NEL endpoints, by just updating the NEL headers you have set on your applications. If you don’t know how to adjust HTTP header strings on your applications and set arbitrary values, then you already have a bigger issue in that you don’t know what you’re doing in IT, so please get out of the way and allow those who do know to get stuff done!
Your NEL endpoint should be defined as a HOSTNAME, with a valid (trusted) TLS certification, listening for an HTTP post over HTTPS. Its a simple JSON payload, that you will want to store somewhere. You have a few choices as to what to do with this data when submitted:
Reject it outright. Maybe someone is probing you, or submitting malicious reports (malformed, buffer overflow attempt, SQL injection attempt, etc)? But these events themselves may be of interest…
Store it:
In a relational database
In a No-SQL database
In something like ElasticSearch
Relay it:
Via email to a Distribution List or alias
Integration to another application or SIEM
My current preference is to use a No-SQL store, with a set retention period on each report.
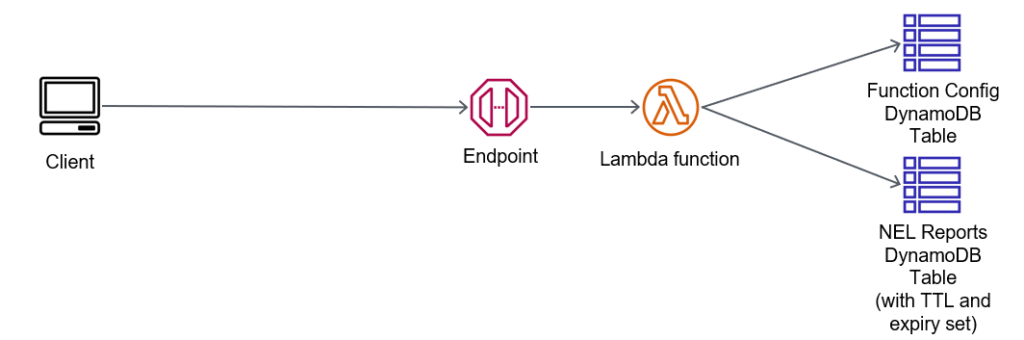
NEL in AWS API Gateway, Lambda and DynamoDB
The architecture for this is very simple:
Simple NEL endpoint with API Gateway, Lambda and DynamoDB
We have one table which controls access for reports to be submitted; its got config items that are persistent. I like to have a config for banned IPs (so I can block malicious actors), and perhaps banned DNS domains in the NEL report content. Alternately, I may have an allow list of DNS domains (possibly with wildcards, such as *.example.com).
My Lambda function will get this content, and then evaluate the source IP address of the report, the target DNS domain in the report, and work out if its going to store it in the Reports table.
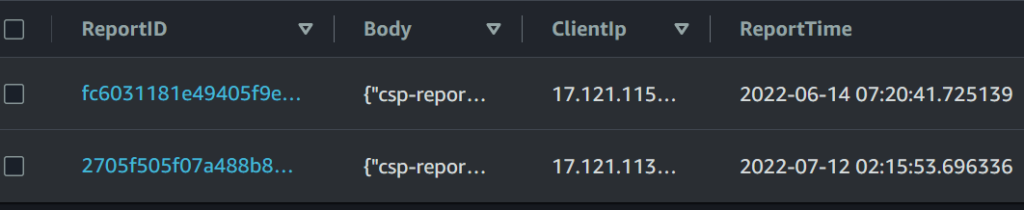
When inserting the JSON into the report table, I’m also going to record:
The current time (UTC)
The source address the report came from
Here’s an example report that’s been processed into the table:
And here is the Lambda code that is validating the reports:
import json
import boto3
import ipaddress
import datetime
import uuid
def lambda_handler(event, context):
address = report_src_addr(event)
if address is not False:
if report_ip_banned(address) or not report_ip_permitted(address):
return {
'statusCode': 403,
'body': json.dumps({ "Status": "rejected", "Message": "Report was rejected from IP address {}".format(address)})
}
if not report_hostname_permitted(event):
return {
'statusCode': 403,
'body': json.dumps({ "Status": "rejected", "Message": "Reports for subject not allowed"})
}
report_uuid = save_report(event)
if not report_uuid:
return {
'statusCode': 403,
'body': json.dumps({ "Status": "rejected"})
}
return {
'statusCode': 200,
'body': json.dumps({ "Status": "accepted", "ReportID": report_uuid})
}
def save_report(event):
report_uuid = uuid.uuid4().hex
client_ip_str = str(report_src_addr(event))
print("Saving report {} for IP {}".format(report_uuid, client_ip_str))
response = report_table.put_item(
Item={
"ReportID": report_uuid,
"Body": event['body'],
"ReportTime": str(datetime.datetime.utcnow()),
"ClientIp": client_ip_str
}
)
if response['ResponseMetadata']['HTTPStatusCode'] is 200:
return report_uuid
return False
def report_ip_banned(address):
fe = Key('ConfigName').eq("BannedIPs")
response = config_table.scan(FilterExpression=fe)
if 'Items' not in response.keys():
print("No items in Banned IPs")
return False
if len(response['Items']) is not 1:
print("Found {} Items for BannedIPs in config".format(len(response['Items'])))
return False
if 'IPs' not in response['Items'][0].keys():
print("No IPs in first item")
return False
ip_networks = []
for banned in response['Items'][0]['IPs']:
try:
#print("Checking if we're in {}".format(banned))
ip_networks.append(ipaddress.ip_network(banned))
except Exception as e:
print("*** EXCEPTION")
print(e)
return False
for banned in ip_networks:
if address.version == banned.version:
if address in banned:
print("{} is banned (in {})".format(address, banned))
return True
#print("Address {} is not banned!".format(address))
return False
def report_ip_permitted(address):
fe = Key('ConfigName').eq("PermittedIPs")
response = config_table.scan(FilterExpression=fe)
if len(response['Items']) is 0:
return True
if len(response['Items']) is not 1:
print("Found {} Items for PermittedIPs in config".format(len(response['Items'])))
return False
if 'IPs' not in response['Items'][0].keys():
print("IPs not found in permitted list DDB response")
return False
ip_networks = []
for permitted in response['Items'][0]['IPs']:
try:
ip_networks.append(ipaddress.ip_network(permitted, strict=False))
except Exception as e:
print("permit: *** EXCEPTION")
print(e)
return False
for permitted in ip_networks:
if address.version == permitted.version:
if address in permitted:
print("permit: Address {} is permitted".format(address))
return True
print("Address {} not permitted?".format(address))
return False
def report_hostname_permitted(event):
if 'body' not in event.keys():
print("No body")
return False
if 'httpMethod' not in event.keys():
print("No method")
return False
elif event['httpMethod'].lower() != 'post':
print("Method is {}".format(event['httpMethod']))
return False
if len(event['body']) > 1024 * 100:
print("Body too large")
return False
try:
reports = json.loads(event['body'])
except Exception as e:
print(e)
return False
for report in reports:
print(report)
return True
if 'url' not in report.keys():
return False
url = urlparse(report['url'])
fe = Key('ConfigName').eq("BannedServerHostnames")
response = config_table.scan(FilterExpression=fe)
if len(response['Items']) == 0:
print("No BannedServerHostnames")
return True
for item in response['Items']:
if 'Hostname'not in item.keys():
continue
for exxpression in item['Hostname']:
match = re.search(expression + "$", url.netloc)
if match:
print("Rejecting {} as it matched on {}".format(url.netloc, expression))
return False
return True
def report_src_addr(event):
try:
addr = ipaddress.ip_address(event['requestContext']['identity']['sourceIp'])
except Exception as e:
print(e)
return False
#print("Address is {}".format(addr))
return addr
def parse_X_Forwarded_For(event):
if 'headers' not in event.keys():
return False
if 'X-Forwarded-For' not in event['headers'].keys():
return False
address_strings = [x.strip() for x in event['headers']['X-Forwarded-For'].split(',')]
addresses = []
for address in address_strings:
try:
new_addr = ipaddress.ip_address(address)
if new_addr.is_loopback or new_addr.is_private:
print("X-Forwarded-For {} is loopback/private".format(new_addr))
else:
addresses.append(new_addr)
except Exception as e:
print(e)
return False
return addresses
You’ll note that I have a limit on the size of a NEL report – 100KB of JSON is more than enough. I’m also handling CIDR notation for blocking (eg, 130.0.0.0/16).
Operational Focus
Clearly to use this, you’ll want to push the Lambda function into a repeatable template, along with the API Gateway and DynamoDB table.
You may also want to have a Time To Live (TTL) on the Item being submitted in save_report() function, with perhaps the current time (Unix time) plus a number of seconds to retain (perhaps a month), and configure TTL expiry on the DynamoDB table.
You may also want to generate some custom CloudWatch metrics, based upon the data being submitted; perhaps per hostname or environment, to get metrics on the rate of errors being reported.
Summary
Hopefully the above is enough to get you to understand NEL, and help capture these reports from your web clients; in a production environment you may want to look at report-uri.com, in non-production, you may want to roll your own as above.