I’ve switched to using Unifi a few years back, and made the investment in a Unifi Dream Machine when my home Internet connection exceeded 25 MB/sec — basically when NBN Fibre to the Premises (FTTP) became available in my area, replacing the ADSL circuit previously used.
I’d also shifted ISPs, as I wanted one that gave me native IPv6 so that I can test customer deployments (and be ahead of the curve). I selected Aussie Broadband, and they have been very good.
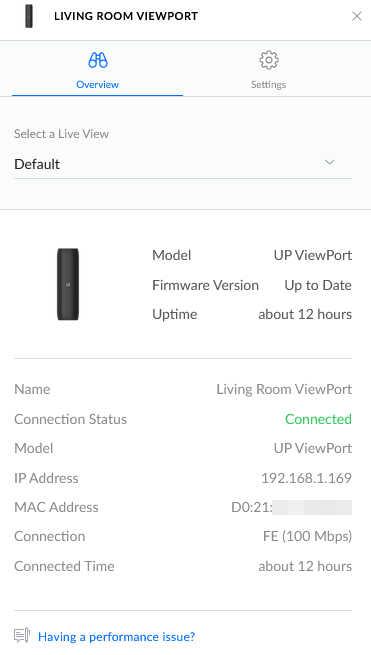
Here’s what my home network topology looks like, according to Unifi:
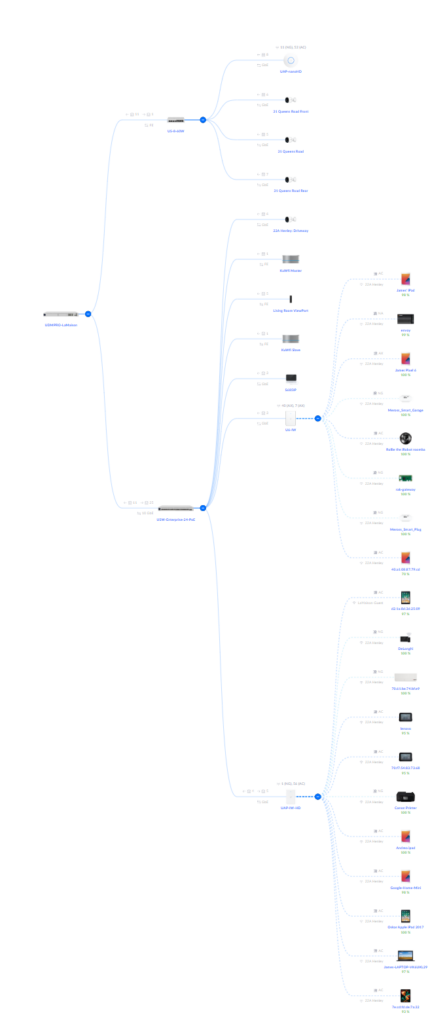
But actually, this is what it really is like:
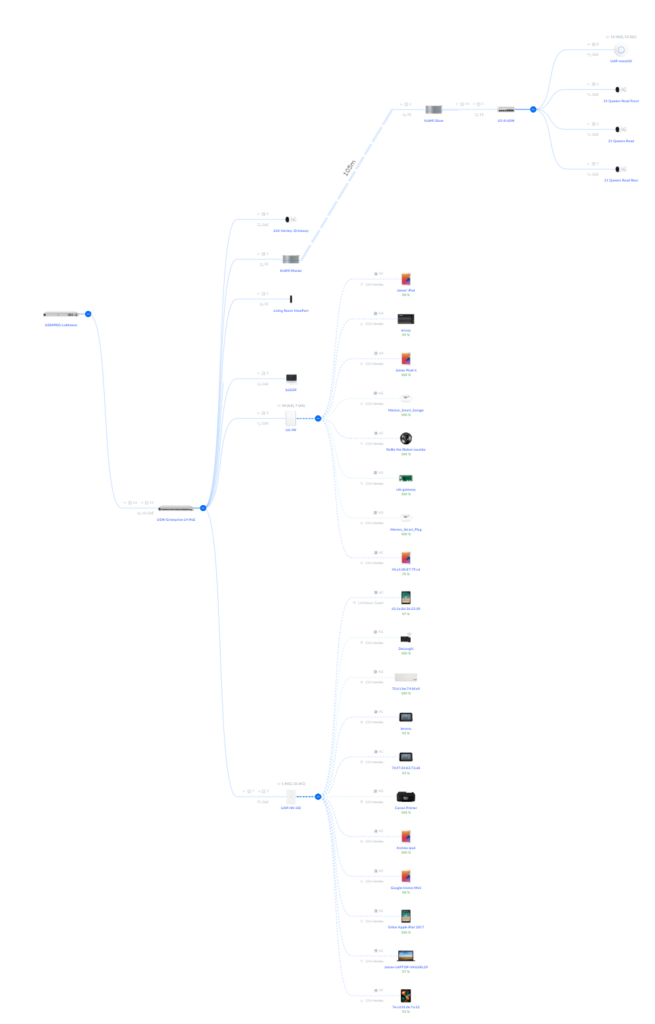
The difference is the top cluster, which has the two point-to-point devices, separated by around 105 meters (300ft), which the Unifi device does not see.
Meanwhile, my family had a separate property 300 kms away in the southwest of Western Australia, which until two months ago, had been a totally disconnected site: no Internet and no telephone. With aging family members, it was becoming more pressing to have a telephone service available at the property, and resolve the issue of using a mobile hot spot when on site.
At the same time, we had a desire to get some CCTV set up, and my Unifi Protect had been working particularly well for several years now at my location(s) – including over a 100m point-to-point WiFi link.
Once again, we selected Aussie Broadband as an ISP, but a slower Fibre to the Node (FTTN) was delivered, which we weren’t expecting. This required an additional VDSL bridge to convert from the analogue phone line, to ethernet presentation to the UDM SE gateway/router.
Here’s the topology of the new site:
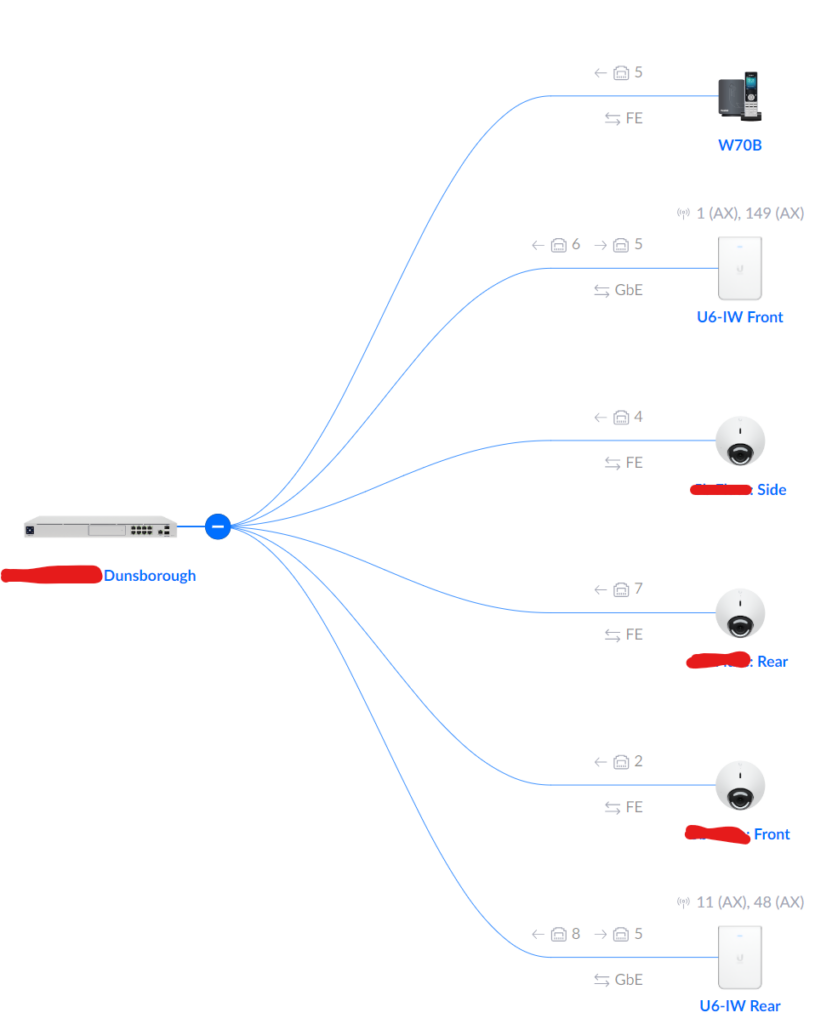
Easy. The Unifi device has some great remove administration capabilities, which means ensuring everything is working is easy to do when 300 kms away.
Unifi Site Magic
And then this week, I see this:
So I wander over to unifi.ui.com, and try to link my two sites – one subnet at each of the two sites, and it starts to try to connect:
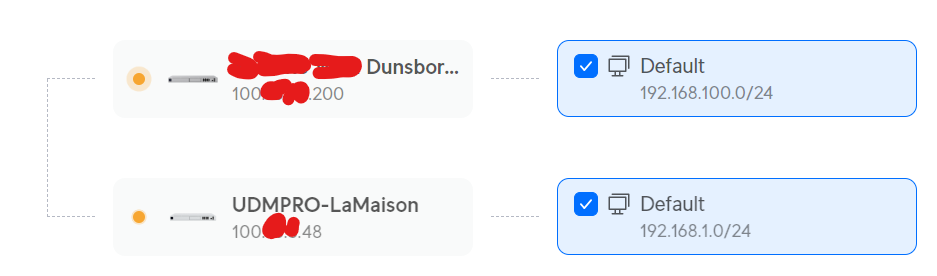
But after a while, I give up. It won’t connect.
I see it only supports IPv4 (at this time). Everything else looks fine…
It’s only then (after a post to the Ubiquiti forums) that I’m pointed at the face that both sites are on 100.xxx, which are reserved addresses for Carrier Grade NAT.
A quick look up on the Aussie Broadband site, and I see I can opt out of CGNAT, and today I made that call. Explaining the situation, I requested one site be moved out (I’m not greedy, and IPv4 space is scarce).
Am hour later, and I have a better outcome:
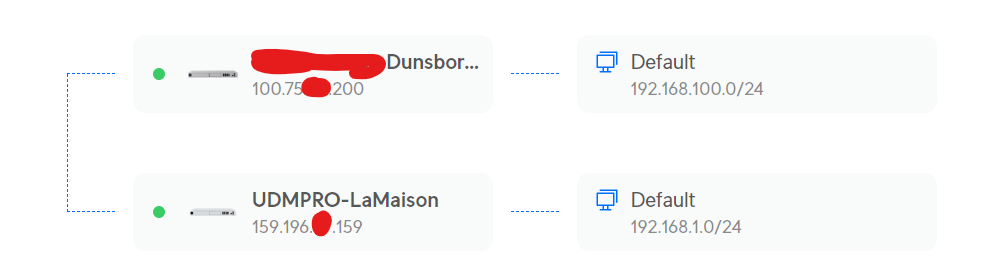
And now, from Perth, I can ping the VoIP phone on-site 300 kms away behind the router:
C:\Users\james>ping 192.168.100.122
Pinging 192.168.100.122 with 32 bytes of data:
Reply from 192.168.100.122: bytes=32 time=19ms TTL=62
Reply from 192.168.100.122: bytes=32 time=20ms TTL=62
Reply from 192.168.100.122: bytes=32 time=19ms TTL=62
Reply from 192.168.100.122: bytes=32 time=19ms TTL=62Ping statistics for 192.168.100.122:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 19ms, Maximum = 20ms, Average = 19ms
What’s interesting is that only ONE of my sites had to be popped out from behind the ISP’s CGNAT, and the Site Magic worked.
Of course in future, having IPv6 should be sufficient without having to deal with CGNAT.