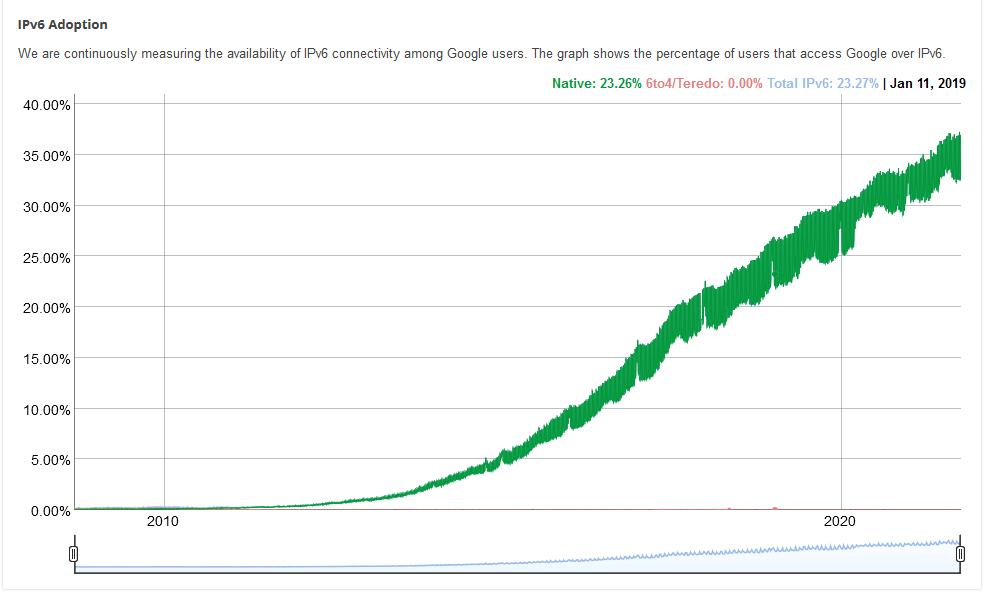
As we round out another year, here’s a perspective on where we are up to on the IPv6 transition that has been going for 20 years, but now gathering momentum.
Adoption
Google has been doing a great job tracking the IPv6 traffic level they see since 2008.
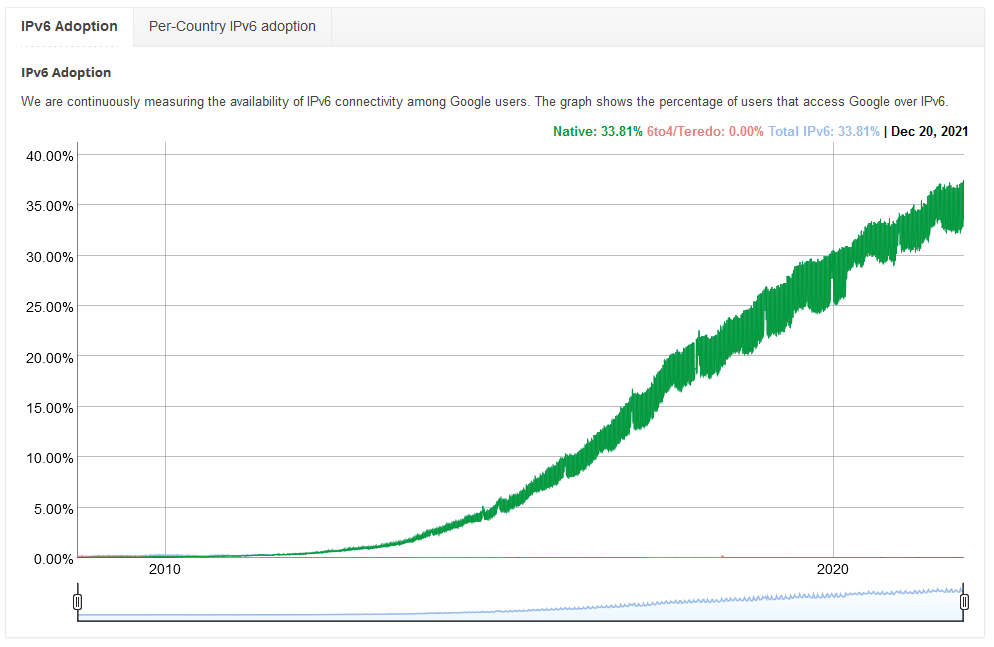
With around 33% of traffic being IPv6, its reasonably significant on a global level. The country-by-country map shows the US on 47%, Germany at 55%, UK on 34%, and Australia at 27%. We’re fast reaching the tipping point where IPv6 is the expected traffic type.
Clearly, the biggest factor is going to be the destination services that people (and systems) want to get to offering IPv6, and then the client (users) having IPv6 available to then send that traffic.
In Australia, the dominant cell phone provider, Telstra, has been using IPv6 for its consumer business since 2016. Now, five and a half years later, we’re still waiting for Optus (Singtel), Vodafone, and many more to pick up.
For ISPs: iiNet continues to show no innovation since the engineering talent departed in the post TPG acquisition. Aussie Broadband (whom I churned to) still call their IPv6 offering a beta, but its been very stable for me now for… years. Perhaps time to take the beta label off?
IPv6 on the Cloud
AWS made many IPv6 announcements through pre-Invent and re:invent (the annual AWS Cloud summit/conference).
Many key services already had 1st class dual-stack support for IPv6 along side IPv4. Key amongst this is Route53, serving DNS responses on either transport layer.
Now we’re seeing IPv6 only capability, as IPv4 starts to look more and more like a legacy transport protocol.
With that perspective, its a shame to see how many of the trusted brands back on the commercial ISP and Mobile carrier market just aren’t up to speed. No engineering investment to really modernise.
AWS VPC: IPv6 only subnets
When defining a VPC, one of the most durable configurations is the IPv4 CIDR range assigned. Once allocated, its set. You can add one more IPv4 allocation if you must, in a separate range, with all kinds of complications.
Since 2016 AWS has permitted an IPv6 network allocation to dual-stack subnets in a VPC, and to allocate to an EC2 instance. Traffic within the VPC was still primarily IPv4 – for services like RDS (databases), etc. Slowly we’ve seen Load Balancers become dual-stack, which is one of the most useful pieces for building customer/internet facing dual-stack, but then fall back to IPv4 on the private side of the load balancer.
The IPv6 in subnets had an interesting feature. Initially the address allocation was only, but now you can BYO, however, the subnet size is always /56, some 18 quintillion IP addresses. Compare with IPv4, where you can make subnets from /28 (14 IPs) to /16 (65,533 IPs).
Two common challenges used to appear with IPv4 subnets: one, you ran out of addresses, especially in public subnets with multiple ALBs of variable traffic pattern peaks, and two: a new Availability Zone launch, and the contiguous address space needs some consistency to meet with traditional on-premises (internal) firewalling.
Now, you only have the one consideration: contiguous address space, but you’re unlikely to exhaust a subnet’s IPv6 address allocation.
When ap-southeast-2 launched, I loved having two Availability zones, and in the traditional IPv4 address space, I would allocate a contiguous range for each purpose across AZs equally. For example:
| Purpose | AZ A | AZ B | Supernet |
| Public | 10.0.0.0/24 | 10.0.1.0/24 | 10.0.0.0/23 |
| Apps (Private) | 10.0.2.0/24 | 10.0.3.0/24 | 10.0.2.0/23 |
| Databases (Private) | 10.0.4.0/24 | 10.0.5.0/24 | 10.0.4.0/23 |
From the above, you can see I can summarise up the two allocations for each purpose, the one in AZ A and AZ B, into one range.
Now for various points I wont dive into her, having TWO AZs is great, but having three is better. However, address space is binary and works in powers of two the purpose of subnetting and supernetting, so if I wanted to preserve contiguous address space, then I would have kept the 10.0.2.0/24 reserved for the AZ C, and then have a left over /24 (10.0.3.0/24) in order to make a larger supernet of 10.0.0.0/22 to cover all Public Subnets:
| Purpose | AZ A | AZ B | AZ C | Reserved | Supernet |
| Public | 10.0.0.0/24 | 10.0.1.0/24 | 10.0.2.0/24 | 10.0.3.0/24 | 10.0.0.0/22 |
| Apps (Private) | 10.0.4.0/24 | 10.0.5.0/24 | 10.0.6.0/24 | 10.0.7.0/24 | 10.0.4.0/22 |
| Databases (Private) | 10.0.8.0/24 | 10.0.9.0/24 | 10.0.10.0/24 | 10.0.11.0/24 | 10.0.8.0/22 |
Now we’ve split our address space four ways, preserved continuity to be able to subnet, but we had to reallocate the .2 and .3 ranges. What a pain.
Now, we can take VPC subnetting further; the next increment would be provisions for 8 AZs. That’s probably a stretch for most organisations, so 4 seems to be most common.
Now take an IPv6 lens over this, and the only thing you’re looking at keeping contiguous over the IPV6 range is the order of allocation, from :00:, through to :03: for the Public Subnets, and then :04: to :07: for apps, and :08: to :0b: (yes, its hex) for the Databases.
Going backwards from IPv6 toIPv4
Another release at reinvent for VPC was the support for DNS64, and NAT64 on NAT Gateway. On a subnet by subnet basis, you can have the DNS resolver return a specially crafted IPv6 address that actually has an IPv4 embedded in it; when used with NAT64,then NAT Gateway will bridge the traffic going outbound from IPv6 internally, back to IPv4 externally. Now you can adopt modern IPv6 internal topologies, but still reach back into the past for those integrations that haven’t gone dual-stack yet.
Of course, this would be far easier if, for all services you wanted to access, you already had the choice of IPv4 or IPv6. Which, as a service provider, you should be offering to your integration partners already.
Load Balancers end-to-end IPv6
Until recently, when traffic from the Internet hit an ALB or NLB over IPv6, it would drop down to IPv4 for the internal connection; however that changed during reinvent with end-to-end IPv6. Virtual Machines (EC2 instances) now see the originating IPv6 address in packets.
Summary
Its been 3 years since some of the critical state government projects I was working on went dual stack in AWS. I encourage my teams to present dual-stack external interfaces, and to prepare all customer environment for this switch over as part of their managed services and professional services deployments. Its not complicated, it doesn’t add any cost, and it can be a competitive advantage. Its another example of a sunrise and sunset of yet another digital standard, and it wont be the last.