It’s taken a long time, but the top of the chart of AWS Cloud consulting services partners has had a shake up on the leader board.
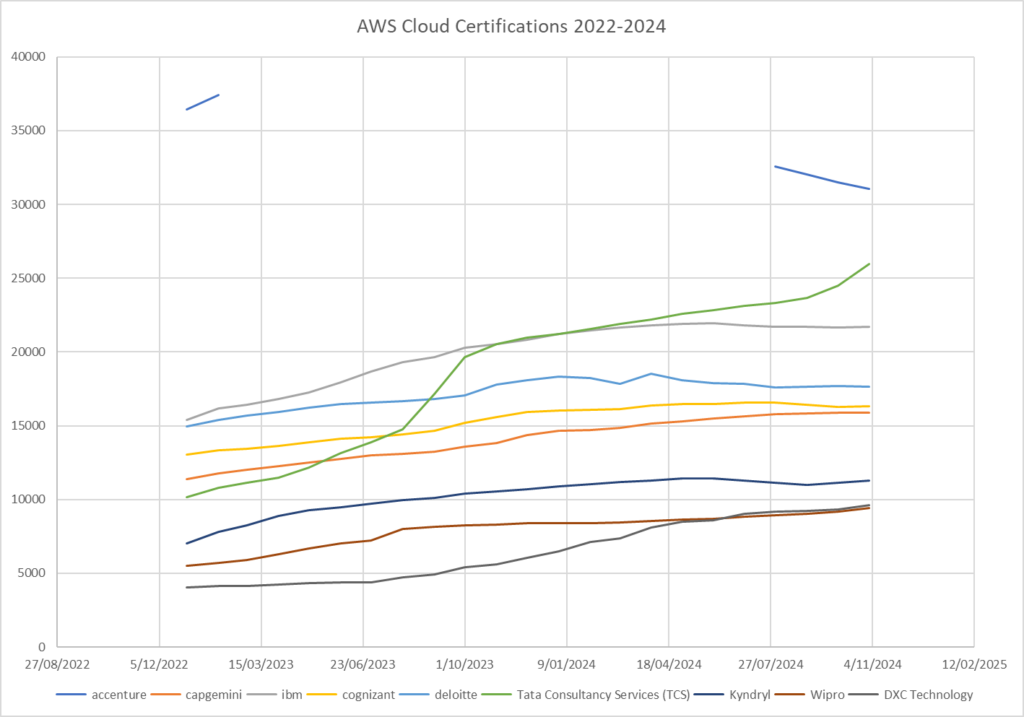
It’s not scientific, and could mean nothing, but I have been tracking the reported number of AWS Cloud certifications across the AWS Partner Community for a while now. It is a limited view into the commitment of these organisations to get their staff knowledge validated, at some level. That level could be Foundational (and thus non-technical), or it could be through to specialist. And for the last few years, the worlds largest partner by this metric has been Accenture.
But not today.
Today, Tata Consulting (TCS) overtook Accenture. Here’s the plot per day since the start of 2025, and the orange line (TCS) has just poked through the green line (Accenture):
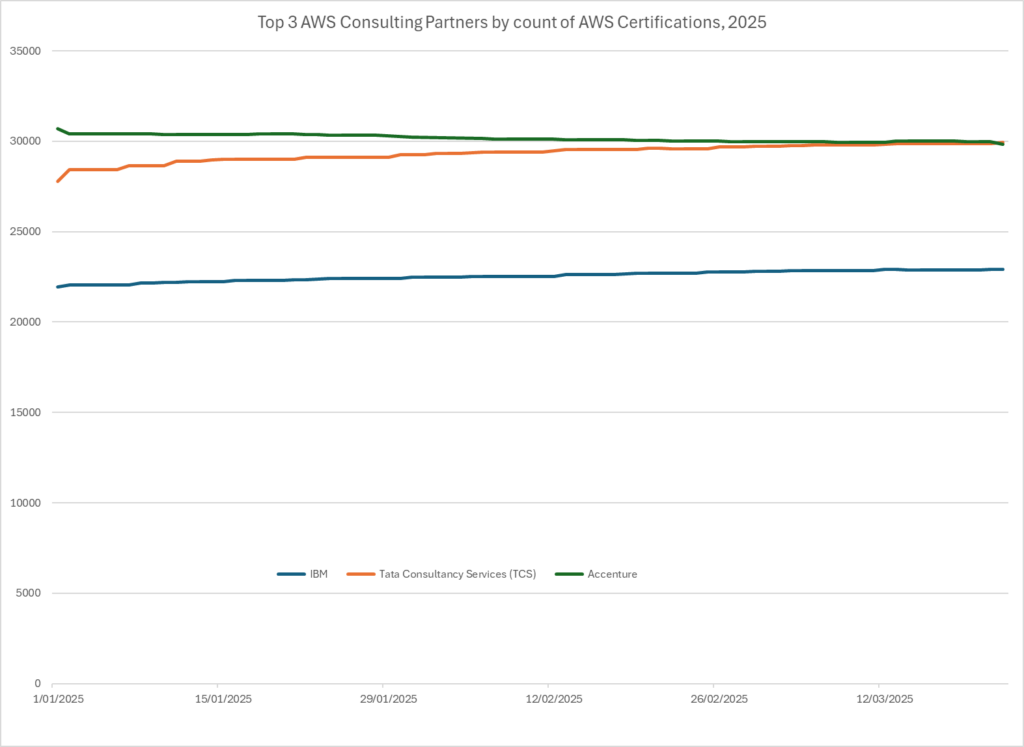
TCS now stands in 1st spot with 29, 947, compared to 29,845 for Accenture, a gap of 102 AWS Cloud certifications.
Yesterday, Accenture was still in front on 29,983, and TCS was just 113 behind.
At it’s peak, Accenture could talk of more than 36,000 AWS Certifications. But in the recent past, this number has been steadily declining, while TCS and the rest of the providers have generally been ascending.
I have not seen any indication why Accenture’s total attributed AWS Certifications have been dropping. Perhaps a policy on paying the charges for their staff for re-certifications, perhaps staff attrition, mergers and de-merges. Perhaps a bunch of people who achieved the Cloud Practitioner (non-technical) 3 years ago as some initiative changed focus and let them expire.
Either way, it seems that the focus and drive that Accenture had shown, is not matched by the focus of TCS.
Does this matter in the AWS Cloud partner ecosystem? Perhaps not. But I find it interesting to consider.